
LSA and ADS 2024
Conferences
Presentations
Research
Students
Utah
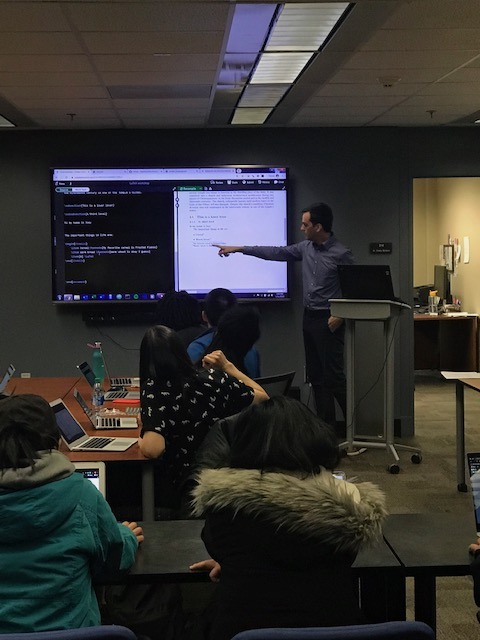
This week I’m in New York City at annual meetings of the Linguistic Society of America and the American Dialect Society. I gave three talks, which you can download here.
NWAV51
Conferences
Presentations
Research
This weekend, some students that I advise in different capacities presented their research at NWAV51 in New York! I am…
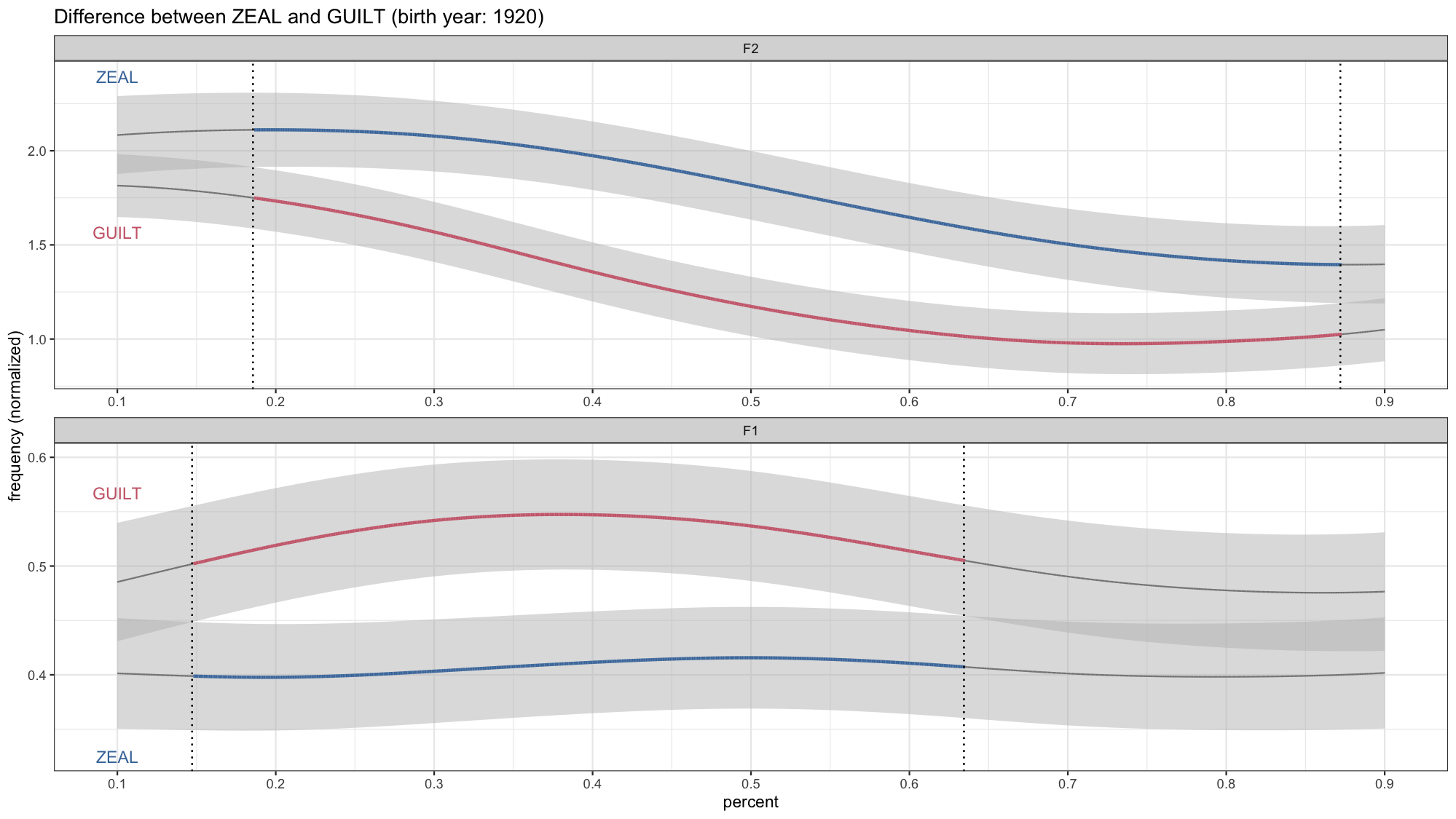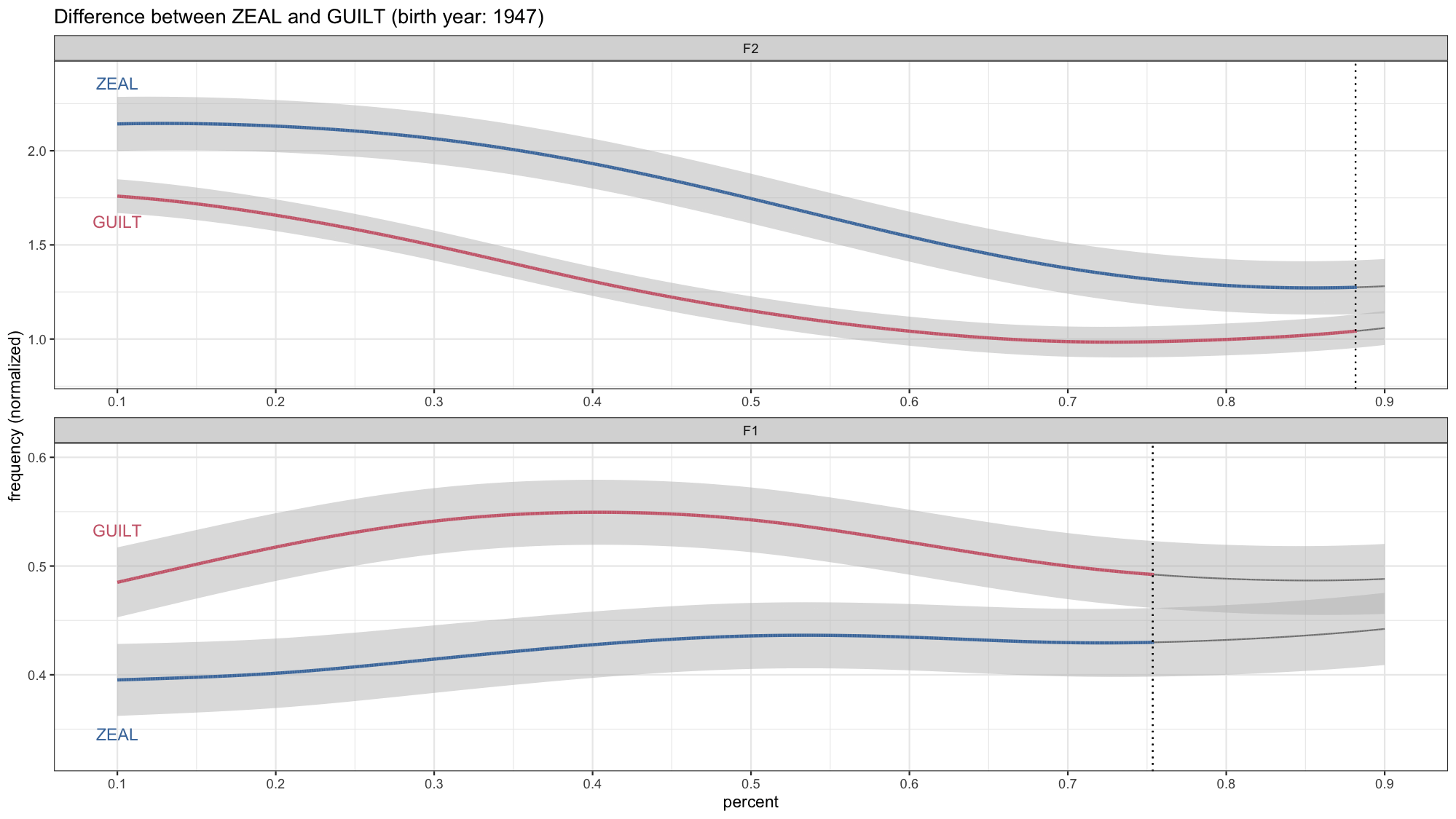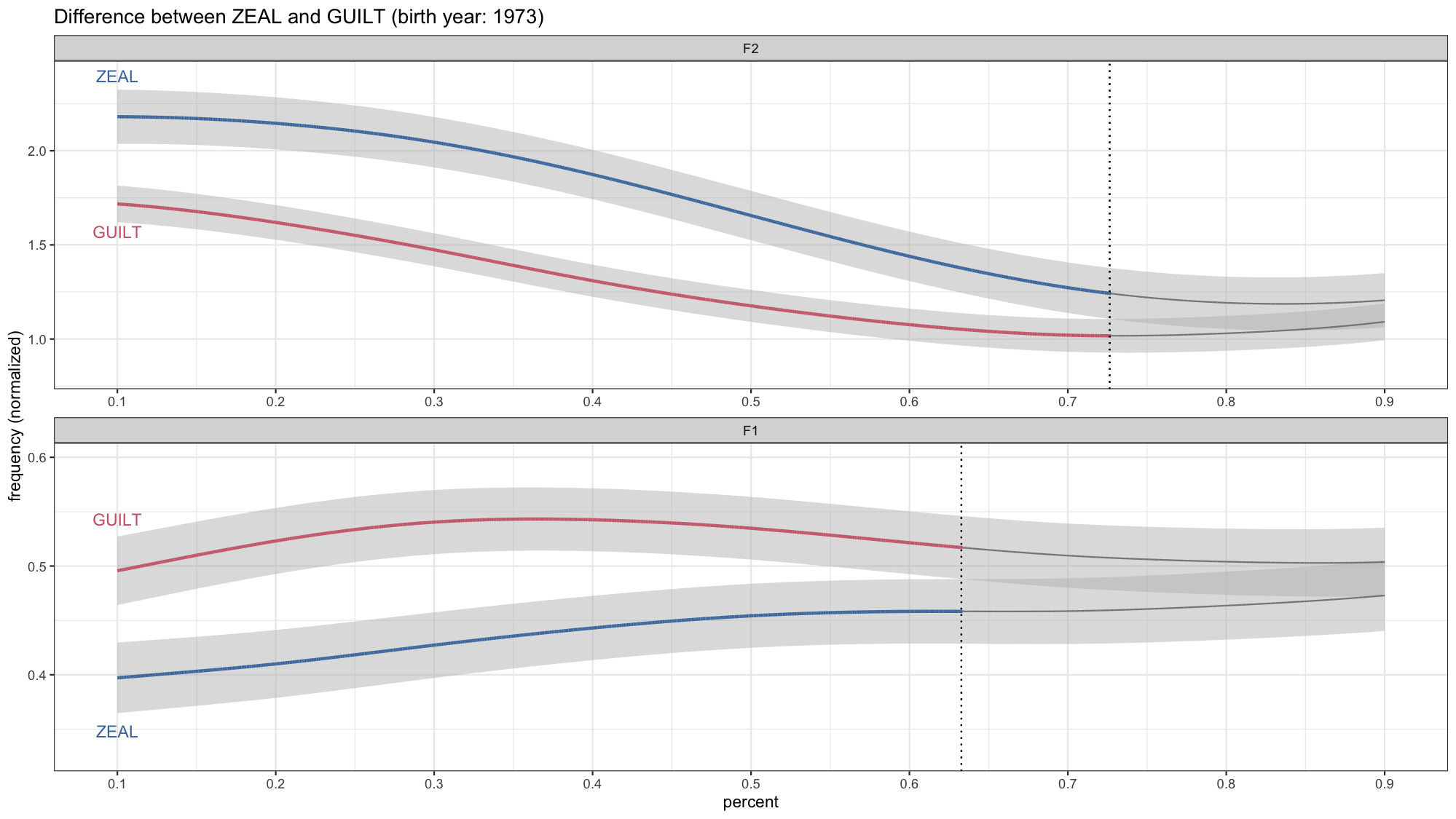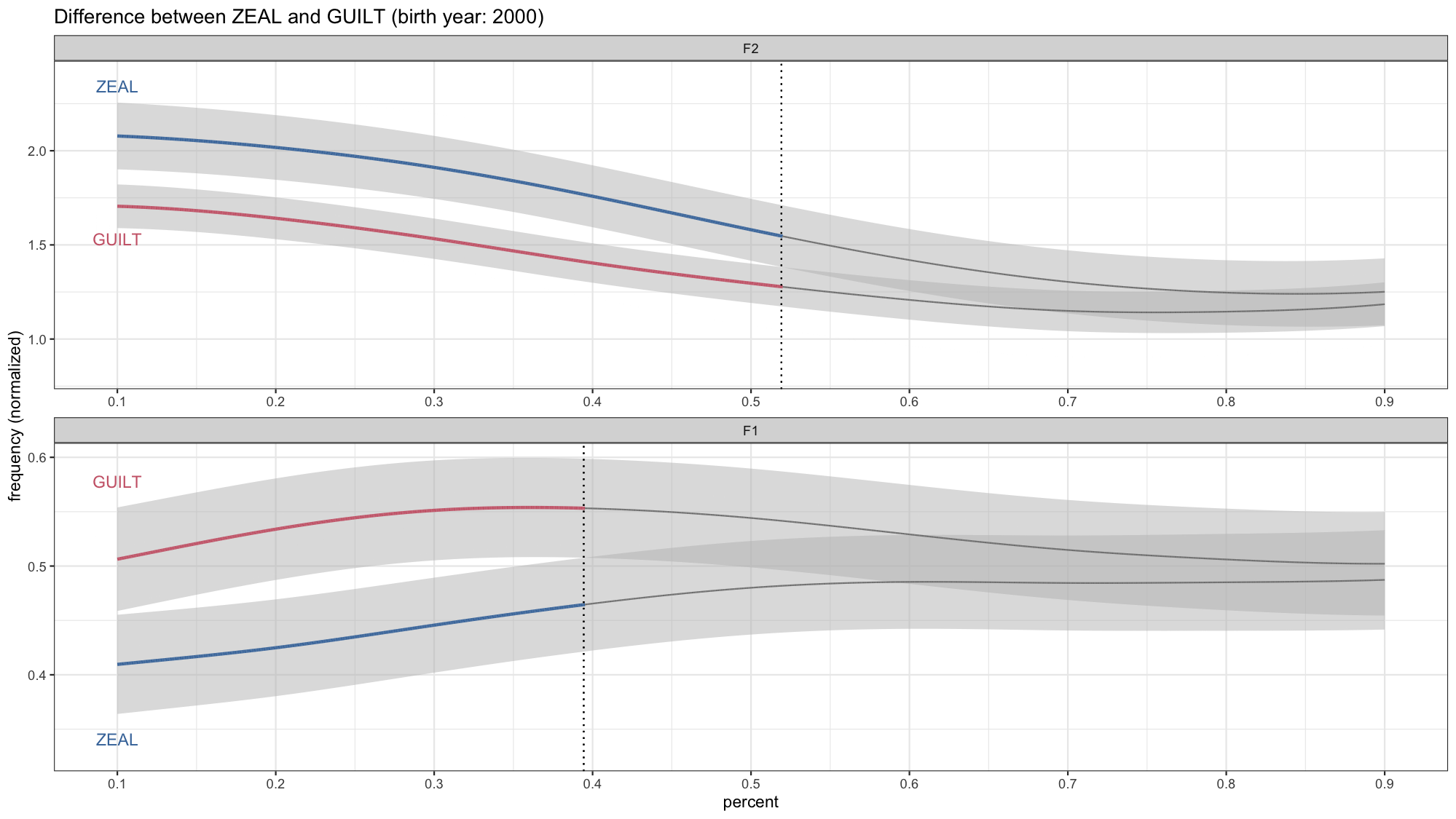
My cot-caught distribution
Dissertation
Lexical Sets
Personal
In appendix C of my dissertation, I listed…
SoSy
Conferences
Presentations
Research
Students
Today, I’m in Champaign, Illinois at the 5th Sociolinguistics Symposium (SoSy) at the University of Illinois…
LSA and ADS 2023
Conferences
Presentations
Research
Students
Utah
West
This week I’m in Denver at annual meetings of the Linguistic Society of America and the American Dialect Society. I gave two talks, which you can download here:
New publication in Linguistics Vanguard
Methods
Research
Publications
Vowel Overlap
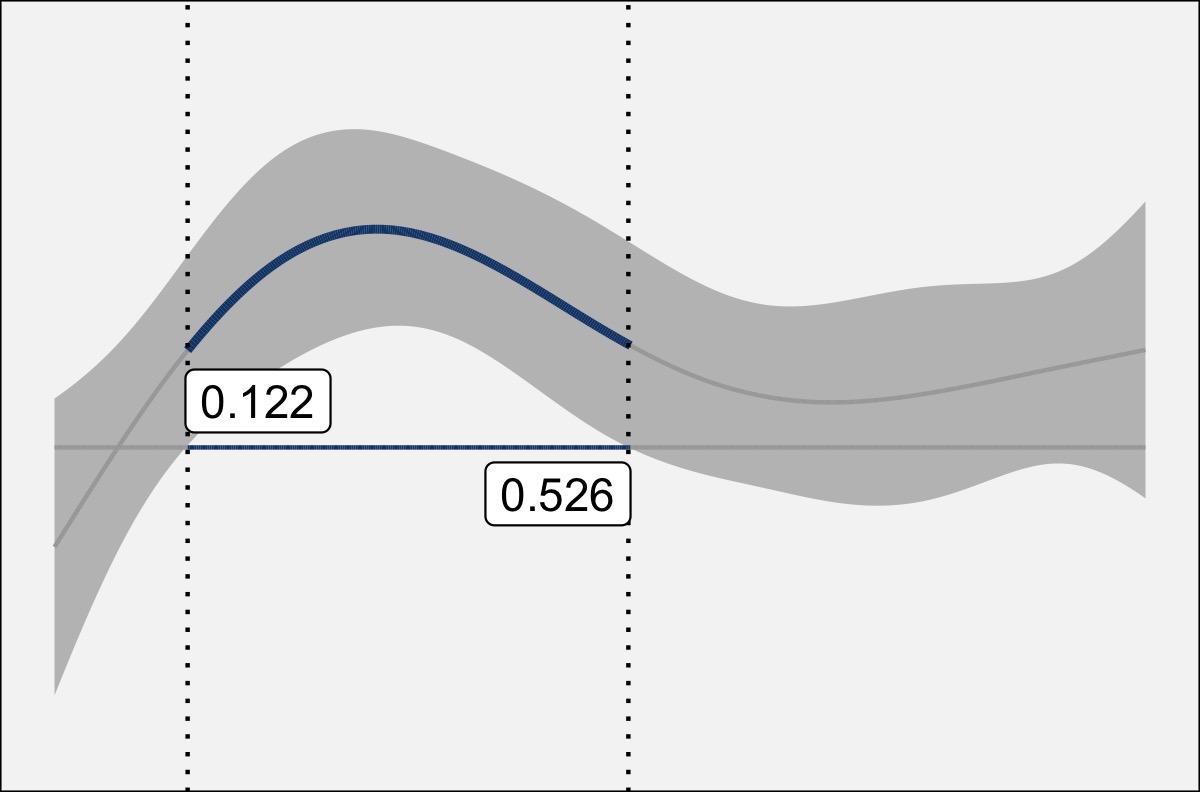
I’m happy to announce that a paper of mine has been published in Linguistics Vanguard. It’s called…
NWAV50
Conferences
Methods
Phonetics
Presentations
Research
Simulations
Statistics
Vowel Overlap
Today I gave a talk that Betsy Sneller and I have been working on called “How Sample Size…
New publication in the Penn Working Papers in Linguistics
Methods
Research
Publications
Vowel Overlap
I’ve just been informed that a manuscript I submitted to the Penn Working Papers in Linguistics has been…
Using Phonic for Collecting Sociophonetic Data
How-to Guides
Skills
A few months ago, I was looking for ways to collect audio within a Qualtrics survey and I stumbled upon this answer which lead me to Phonic.ai. It looked good, so I decided to try it out for a new project. I’m happy to report that I’m overall very satisfied with how it all turned out. In this post, I’ll explain…
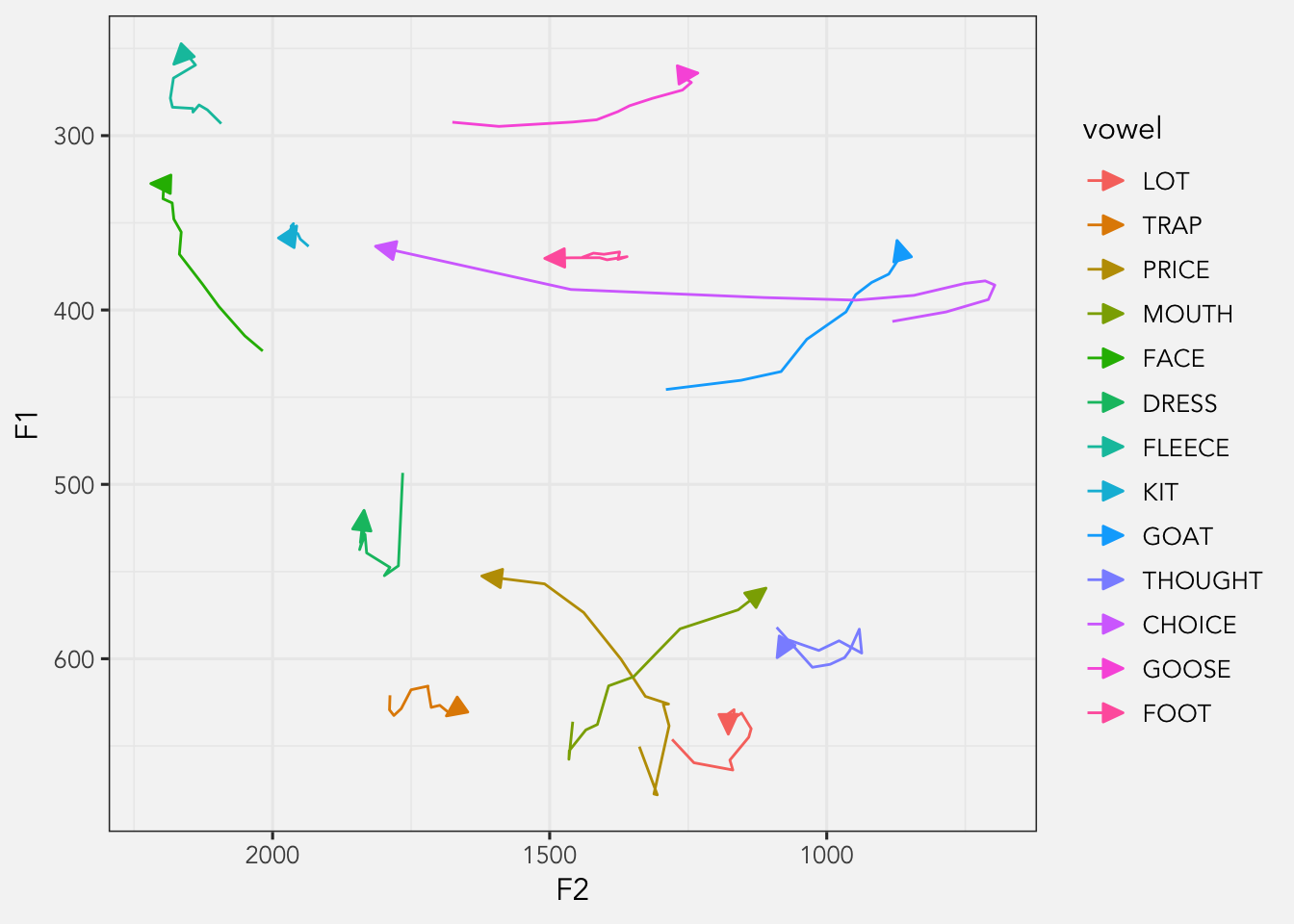
Animating Formant Trajectories
Animations
Data Viz
How-to Guides
R
Skills
Vowel Overlap
Last week, I presented some work that Lisa Johnson and I have been working on. We discussed ways that vowel…
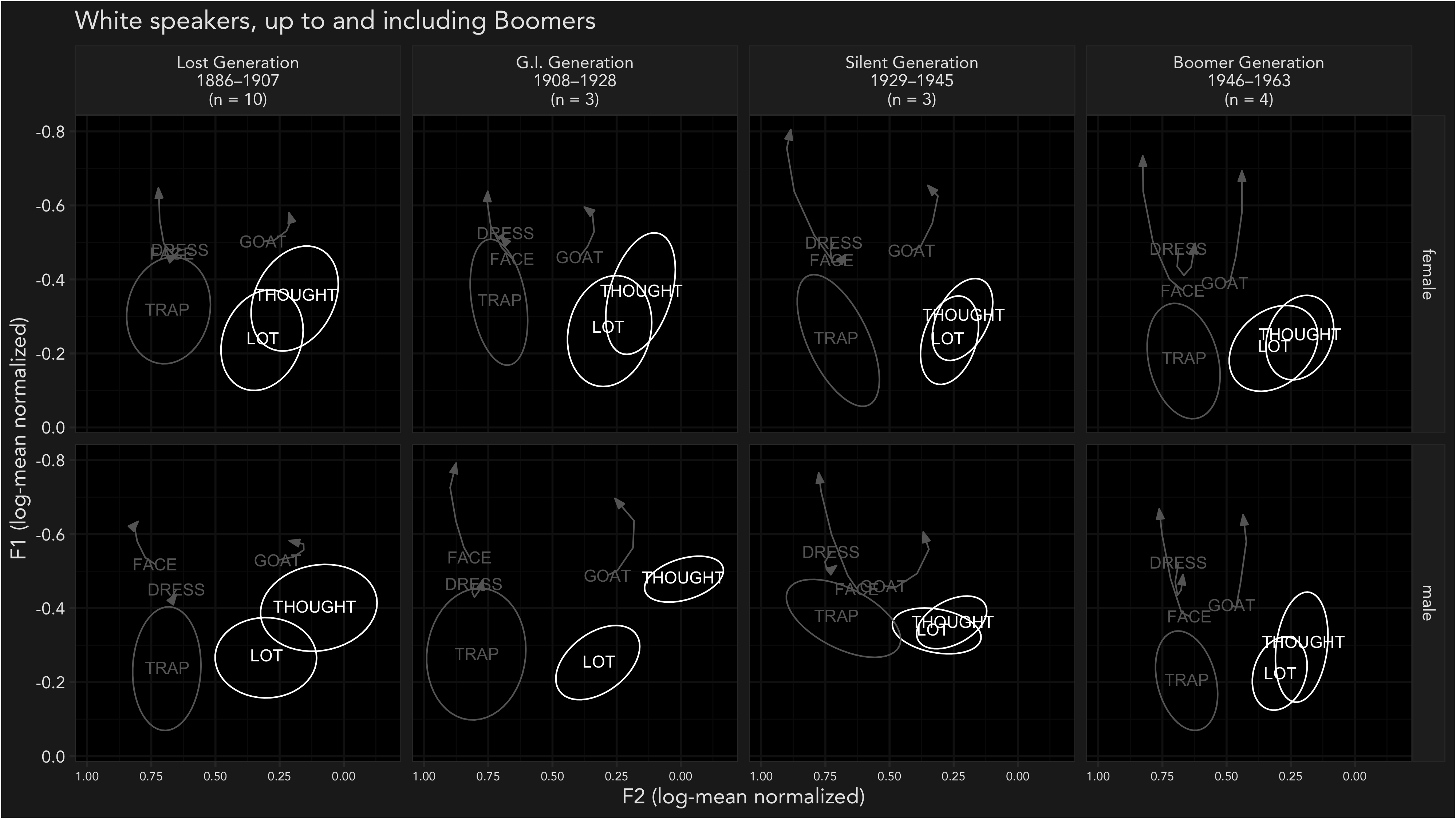
ADS and LSA 2022
Animations
Conferences
Data Viz
MTurk
Phonetics
Presentations
R
Research
South
Students
Utah
Vowel Overlap
West
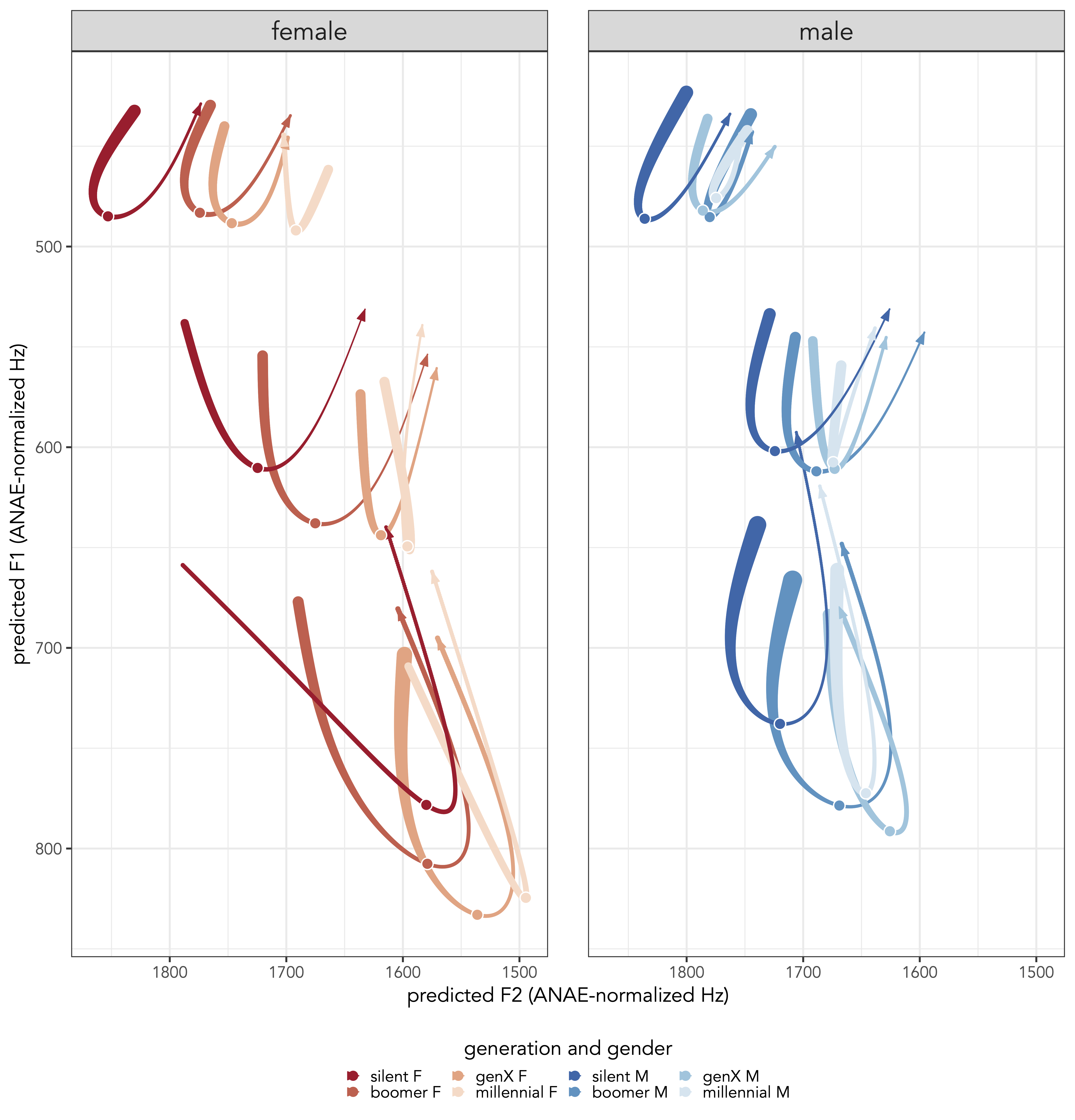
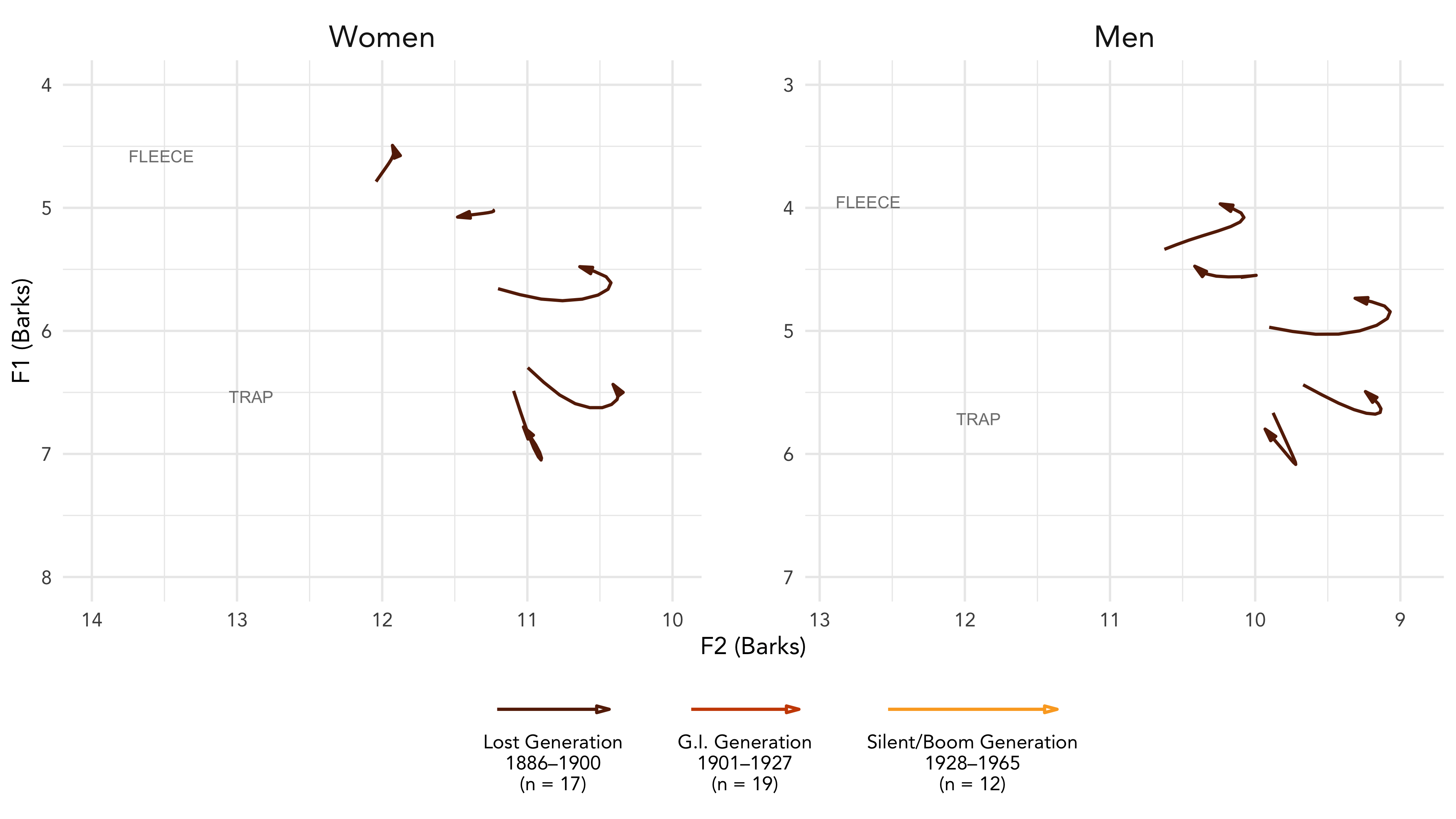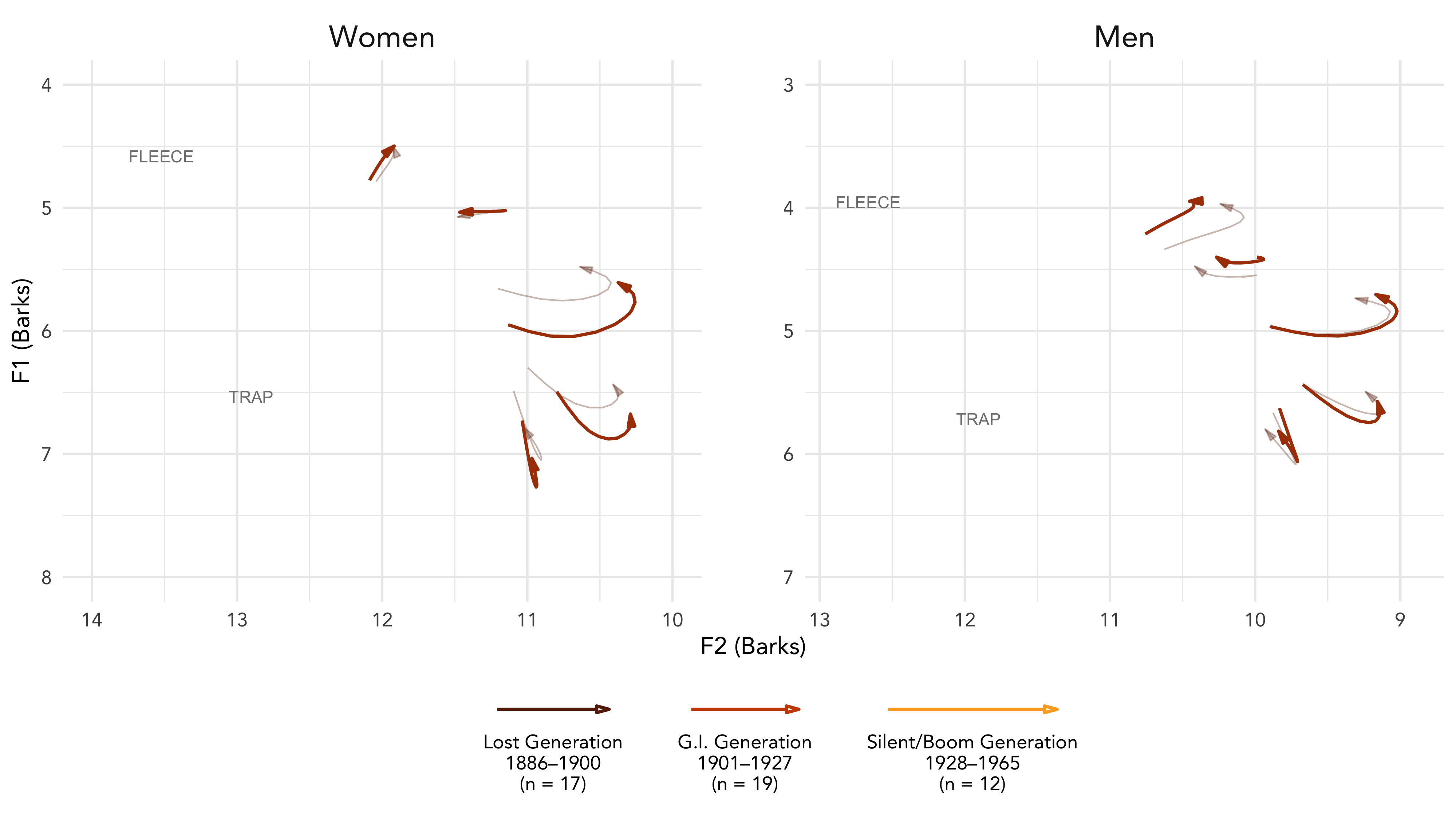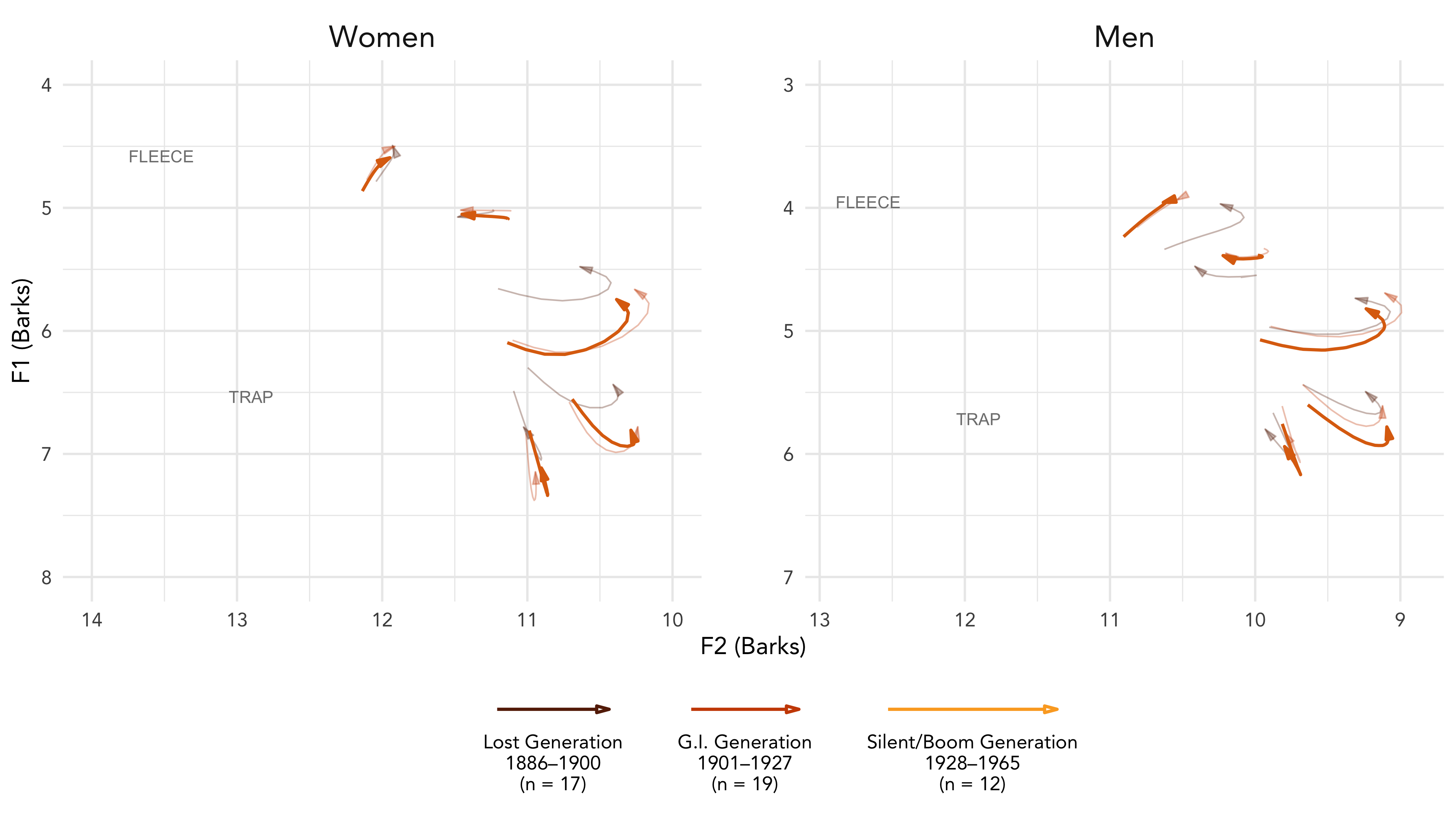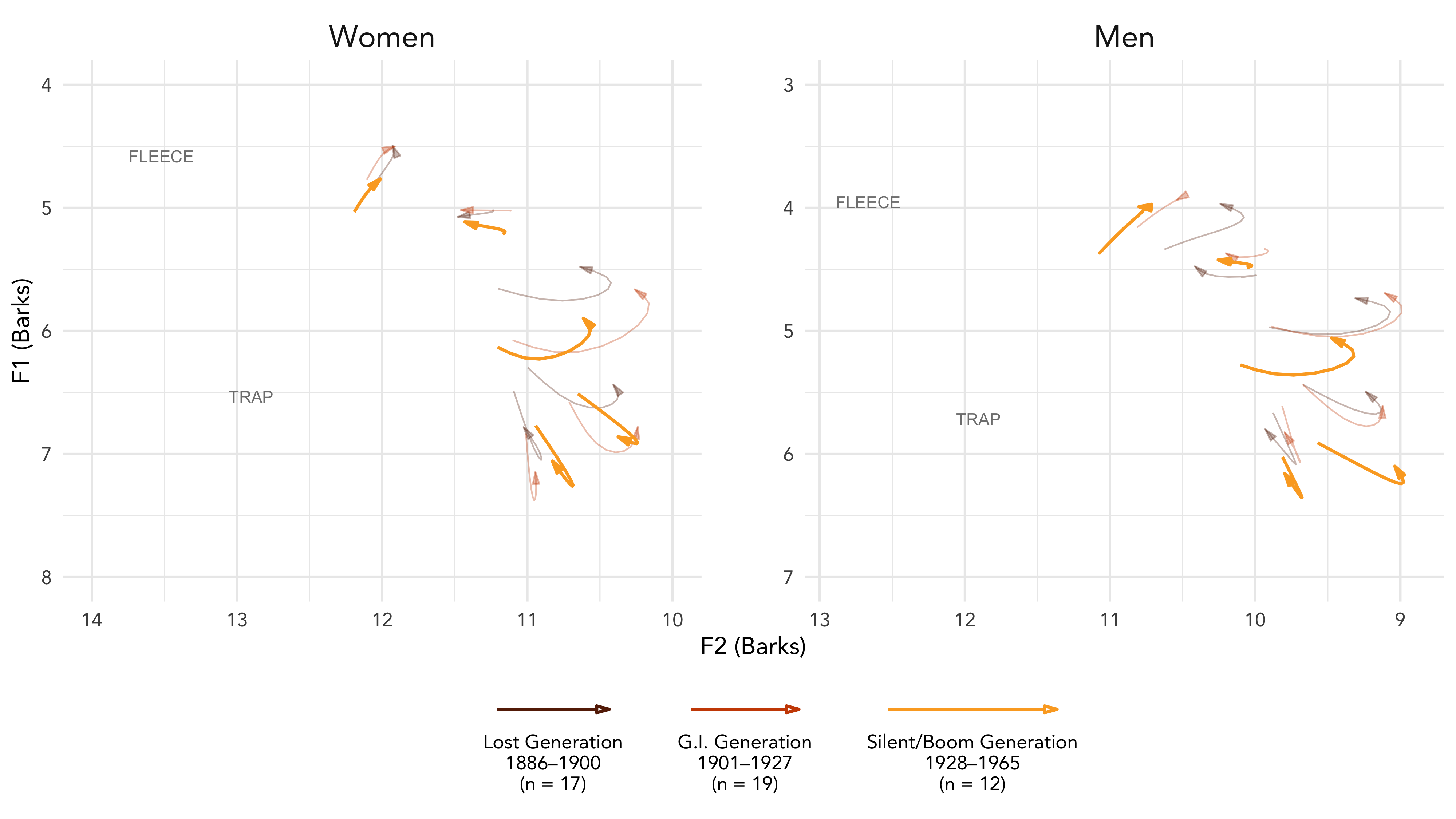
I’m attending the Annual Meeting of the Linguistic…
Curved Text in ggplot2 with geomtextpath
Data Viz
How-to Guides
Side Projects
Skills
I recently saw a tweet by @timelyportfolio that mentions an R package,
geomtextpath, by Allan Cameron. The…
ASA181
Conferences
Dissertation
Methods
Pacific Northwest
Phonetics
Presentations
R
Research
Simulations
Statistics
Vowel Overlap
I’m in Seattle at the 181st Meeting of the Acoustical Society of…
NWAV49
Conferences
Methods
Presentations
Research
Simulations
South
I’m at New Ways of Analyzing Variation 49 online right now! Other than an quick online satellite session of LabPhon last summer, I haven’t attended a conference since…
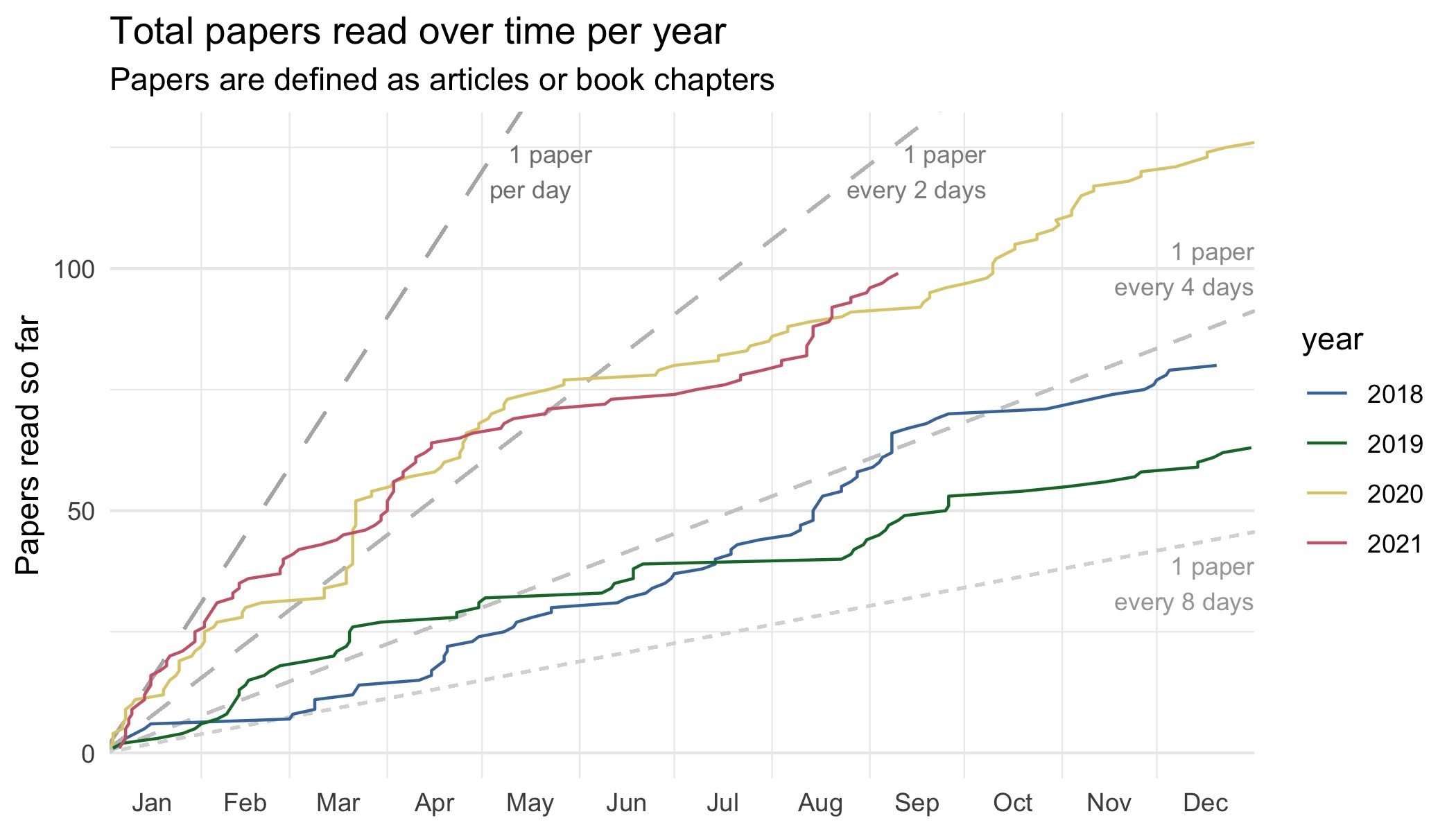
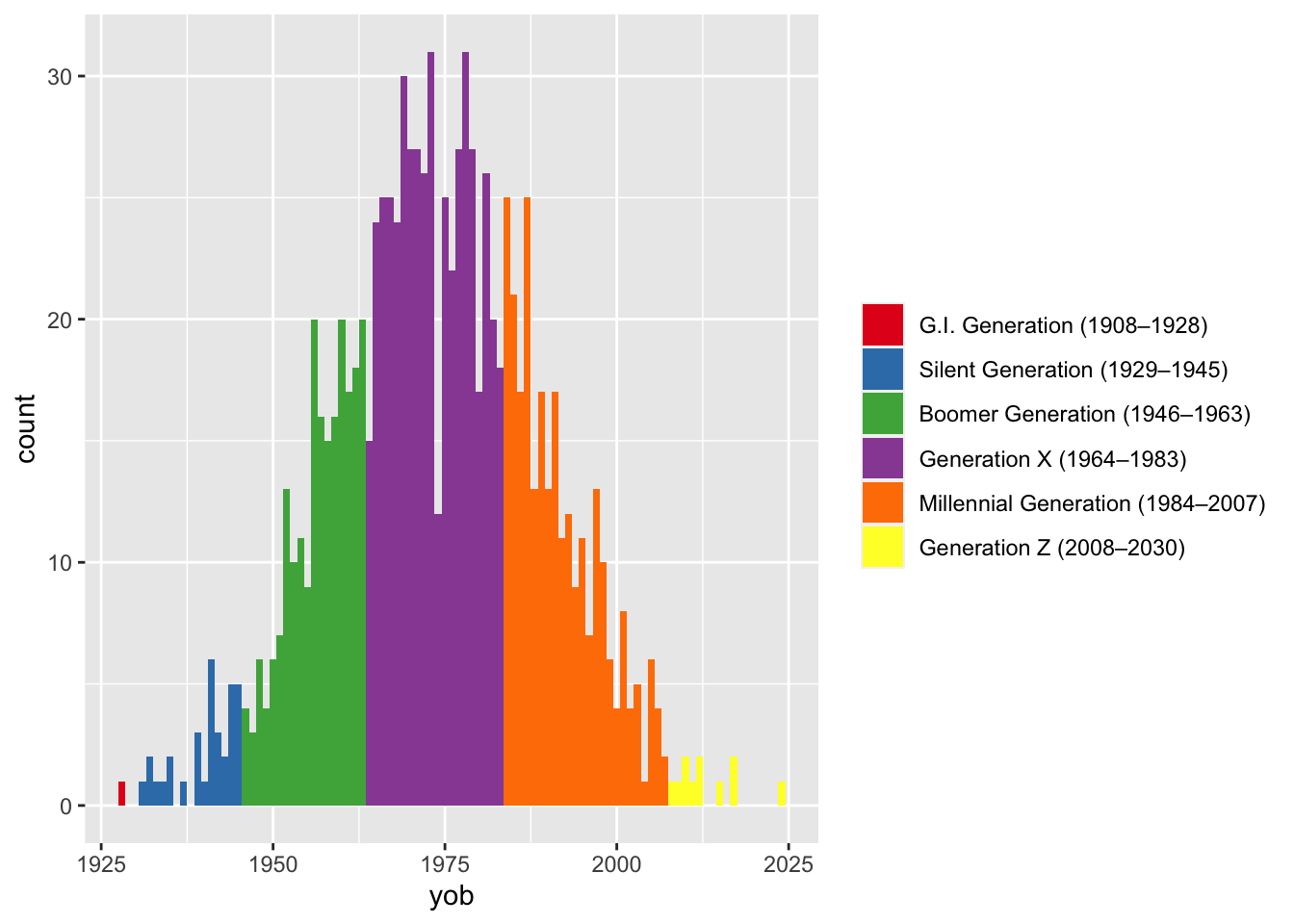
365 Papers (Update)
Personal
At the beginning of 2018, I set the ambitious goal of reading 365 papers during that year. I tweeted about it and blogged about it, but ultimately didn’t achieve my goal. Turns out 365 is a lot. Well, after 1338 days, I can finally say I’ve ready 365 papers! So here’s just…


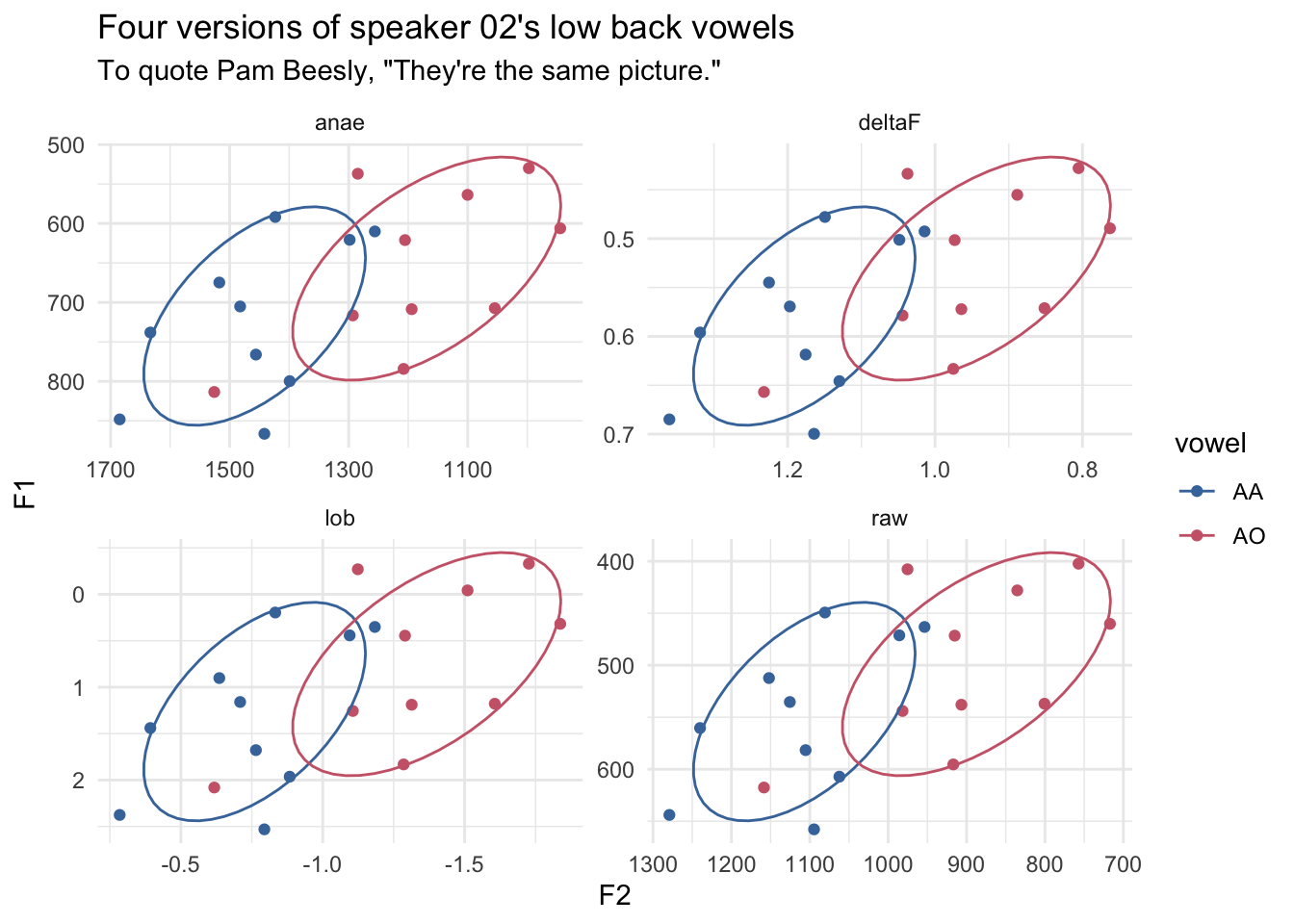
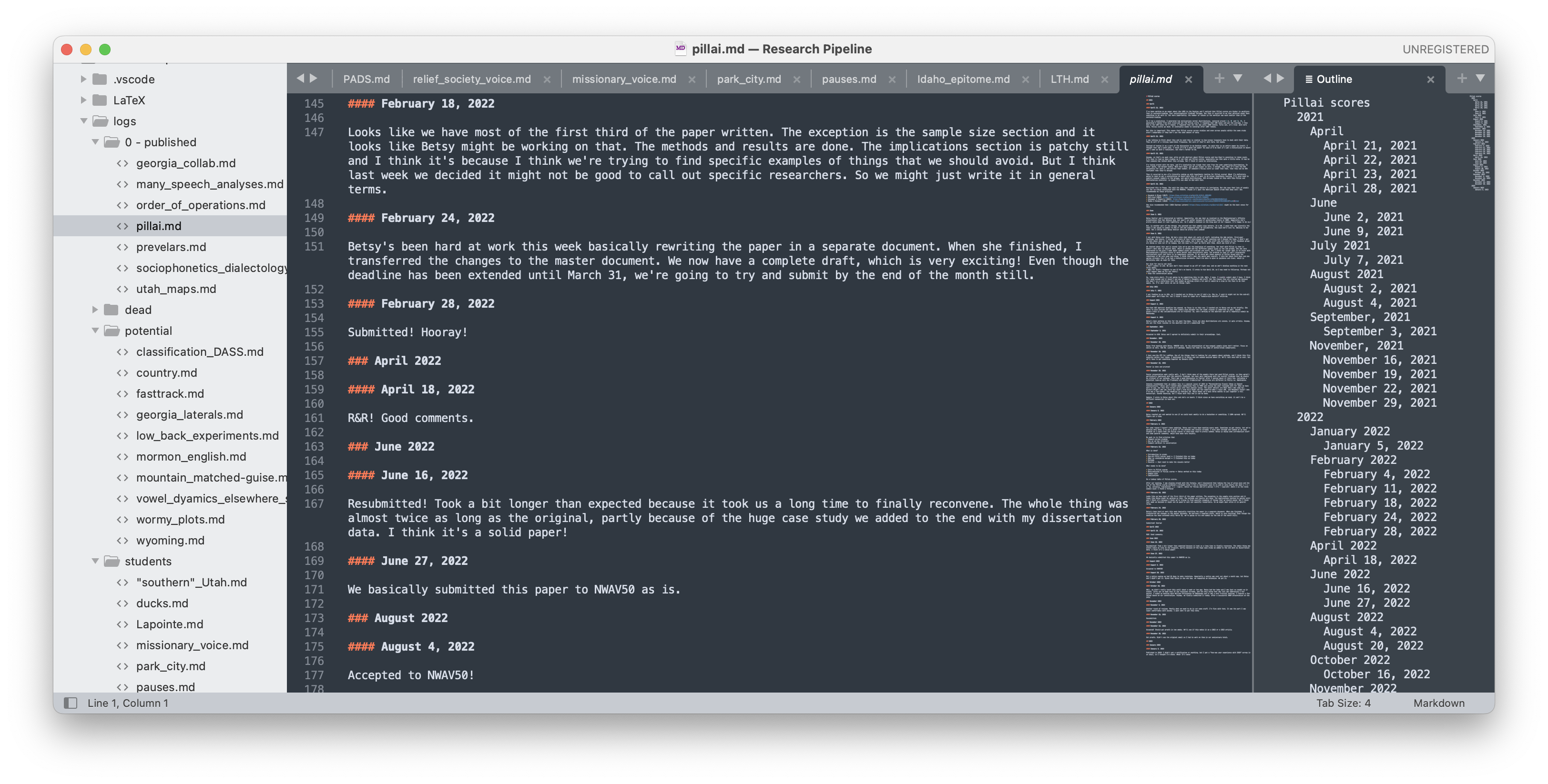
Pillai scores don’t change after normalization
How-to Guides
Methods
Phonetics
R
Skills
Vowel Overlap
I was playing around with some data the other day and I discovered that if you calculate the pillai score on raw data you get the same result as if you calculated it on…


New publication in the latest PADS volume
Pacific Northwest
Publications
Research
West
This week I finally got to lay my hands on a physical copy of my latest publication! It’s called “The Absence of a Religiolect among Latter-day Saints in Southwest Washington” and it’s in the latest Publication of the American Dialect…
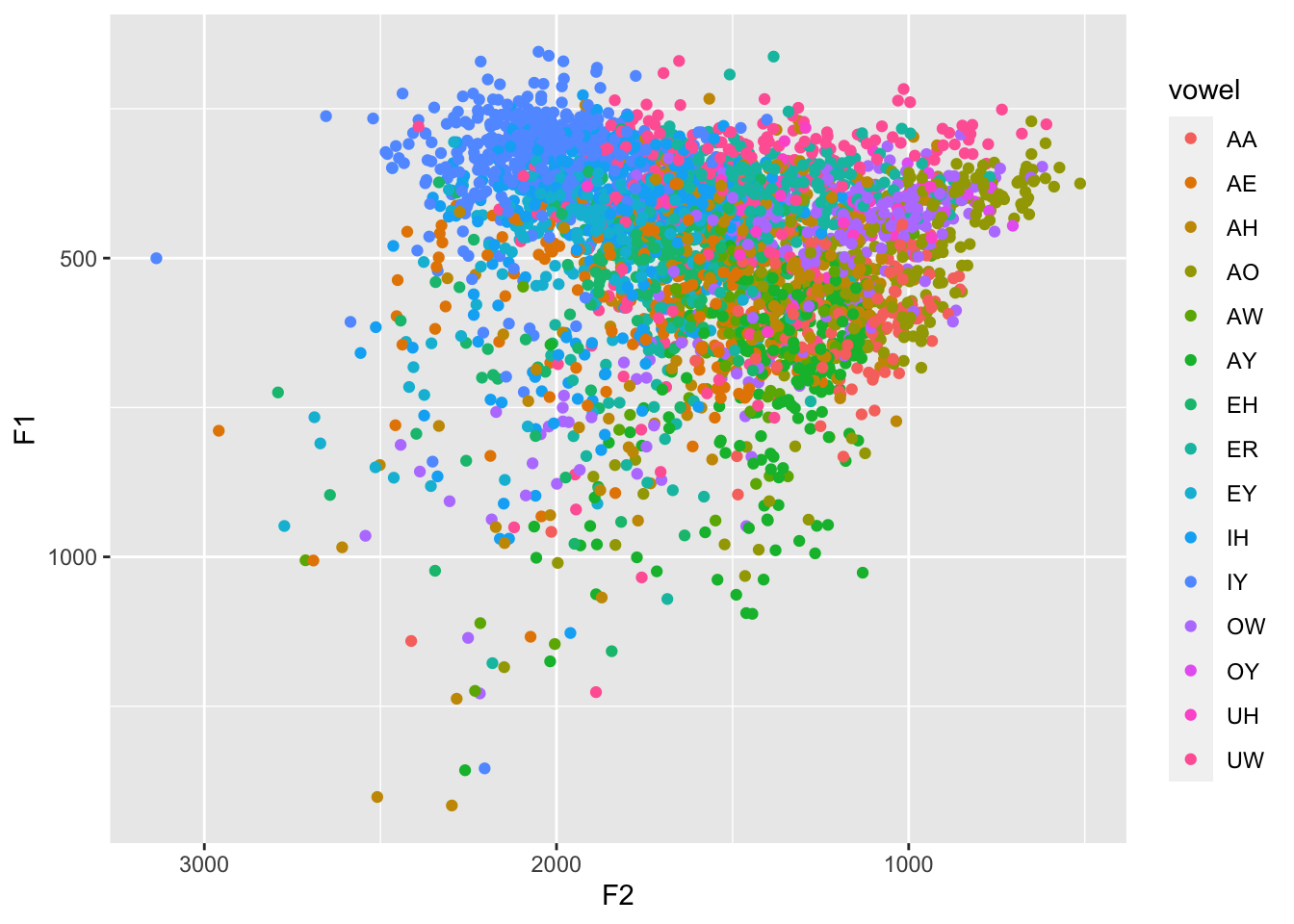
joeysvowels: An R package of vowel data
Github
Methods
Phonetics
R
R Packages
Side Projects
Teaching
West
I’ve just released my third R package,
joeysvowels. It provides a handful of datasets, some subsets of others, that contain formant measurements and other information about the vowels in my own speech. The purpose of the… 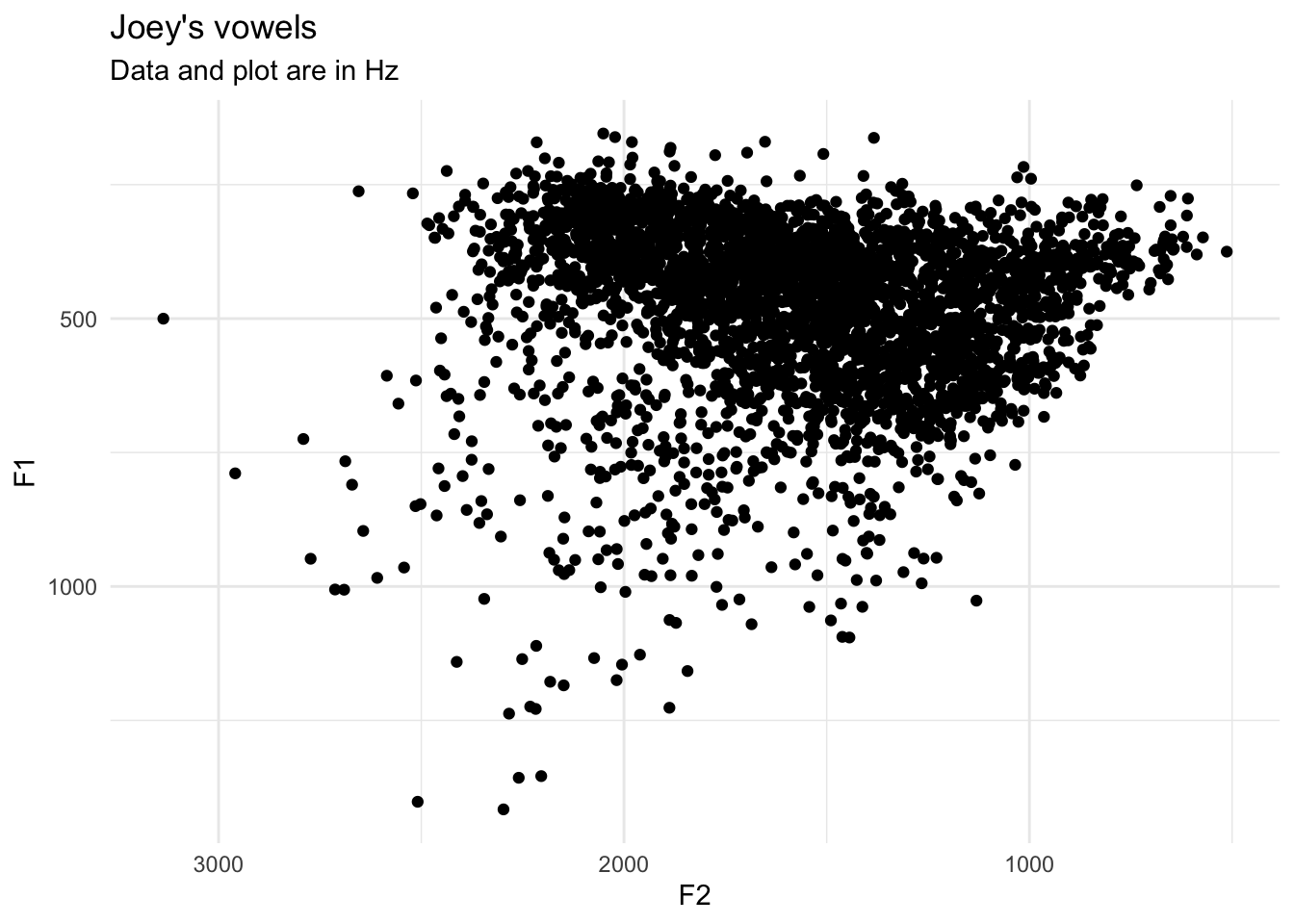
barktools: Functions to help when working with Barks
Data Viz
Github
How-to Guides
Methods
Phonetics
R
R Packages
Side Projects
Skills
I’m happy to announce that I’ve just released another small R package called
barktools. Now that I’ve got one R package out there already, I’ve sort of caught the bug and realized it’s kinda fun to put these small packages out there. This one is just a lightweight little guy that I thought up a few days ago…

futurevisions: My first R package!
Data Viz
Github
R
R Packages
Side Projects
Today I released my first complete, functional, R package! It’s called futurevisions and it’s available on my github. It’s just a little one that contains about 20 different color palettes. I’ve had the idea to work on it for a few months and this week, I decided to go ahead and do it!…
Full house at my first LaTeX workshop!
Github
LaTeX
Presentations
Today I had the opportunity to teach LaTeX for the first time. Caleb Crumley, an RA for the DigiLab at UGA, has been working on a dissertation template in LaTeX that conforms with UGA’s formatting check. He finished it, and it’s got the stamp of approval from the Graduate…
UGA Linguistics Colloquium 2020
Animations
Dissertation
Pacific Northwest
Presentations
Research
For the fourth time in six years, I presented some of my research at the UGA Linguistics Colloquium. I talked about some findings from my dissertation, though I…
LSA and ADS 2020
Animations
Conferences
Linguistic Atlas
Research
South
For the first time in a few years, I did not attend the ADS/LSA annual meetings. It would have been nice to hang out in New Orleans…

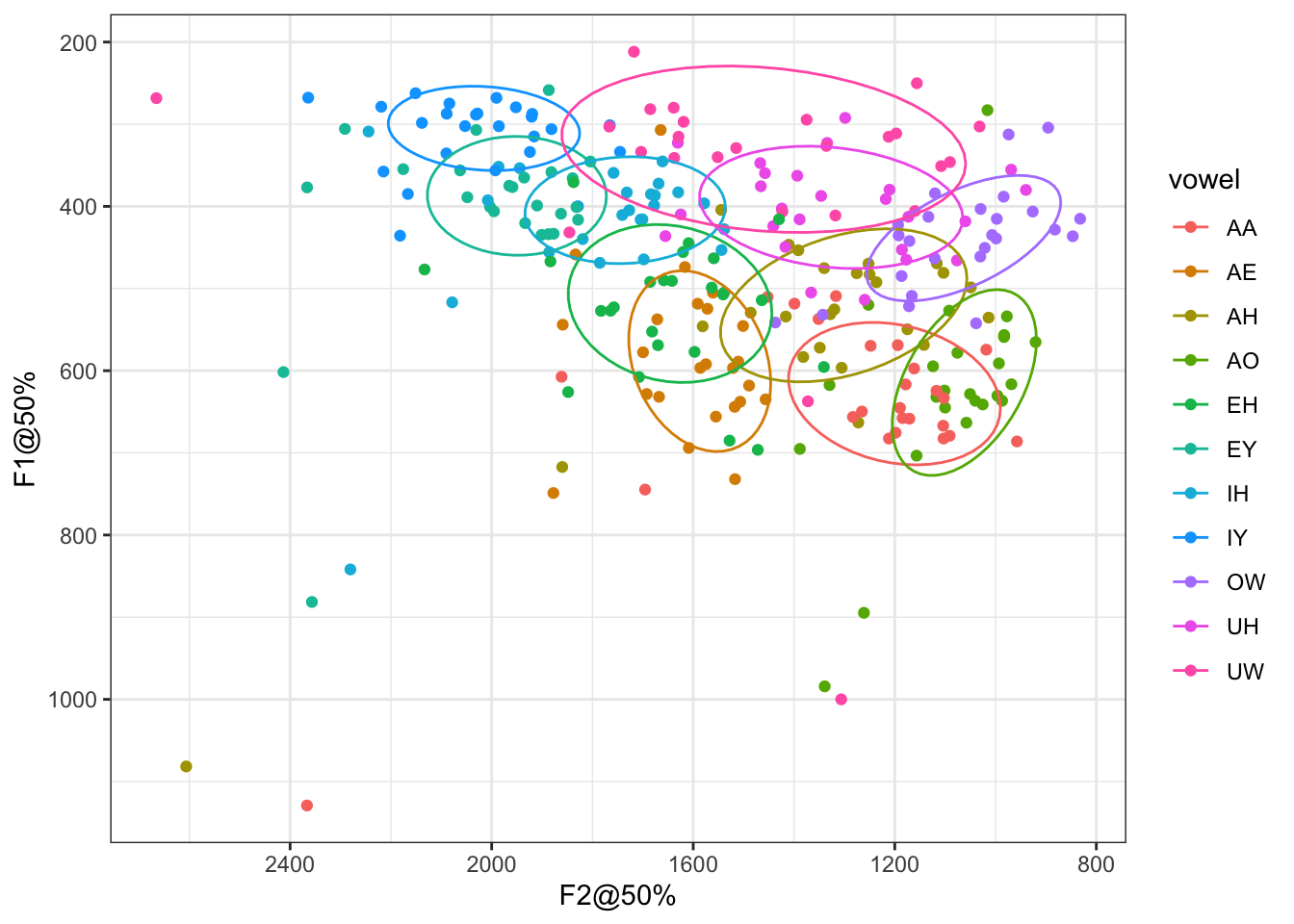
Reshaping Vowel Formant Data with tidyr 1.0
How-to Guides
Methods
Phonetics
R
Skills
Vowel trajectory data can be tricky to work with in R. Sometimes I need to reshape my data into specific format…
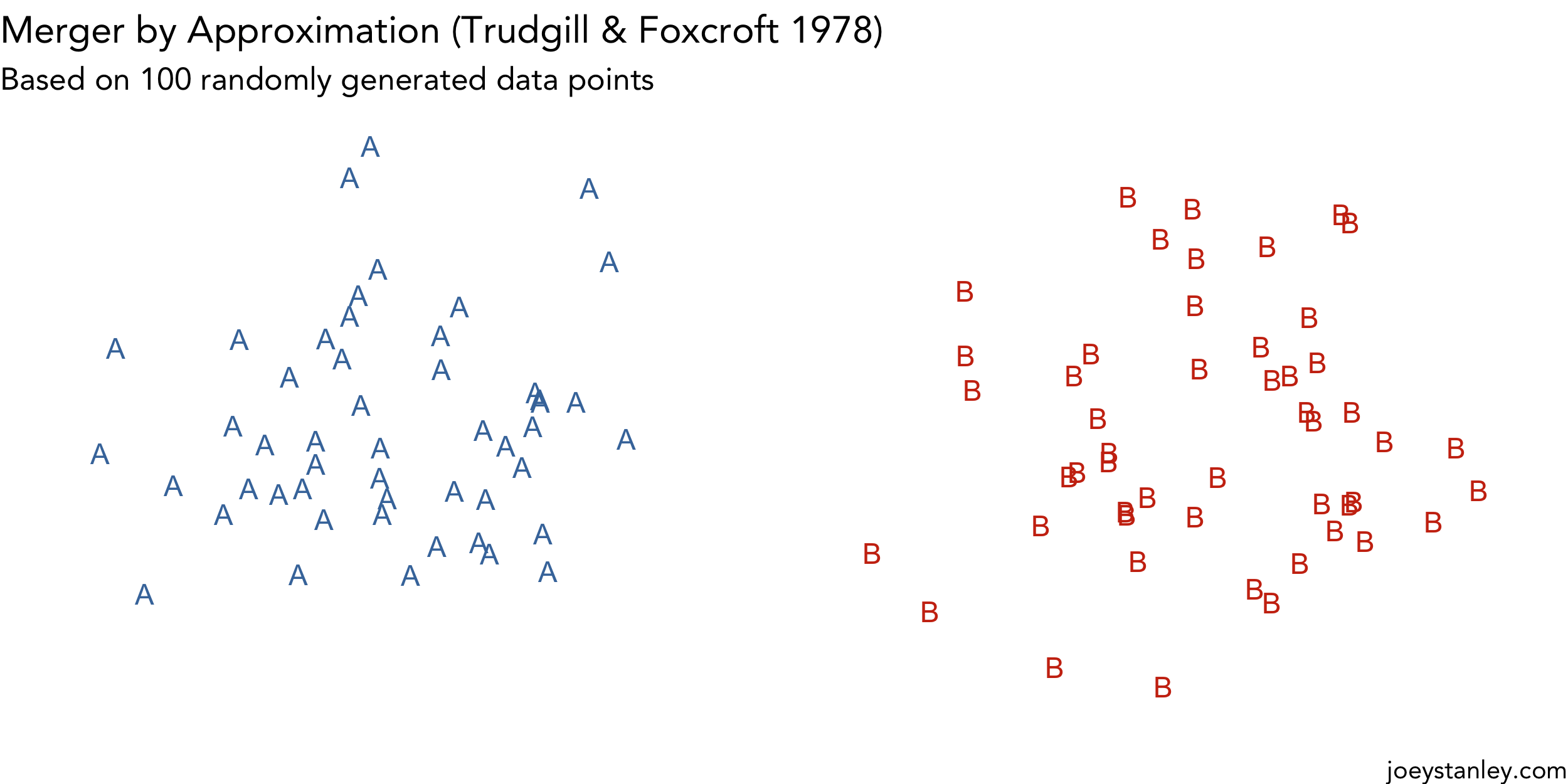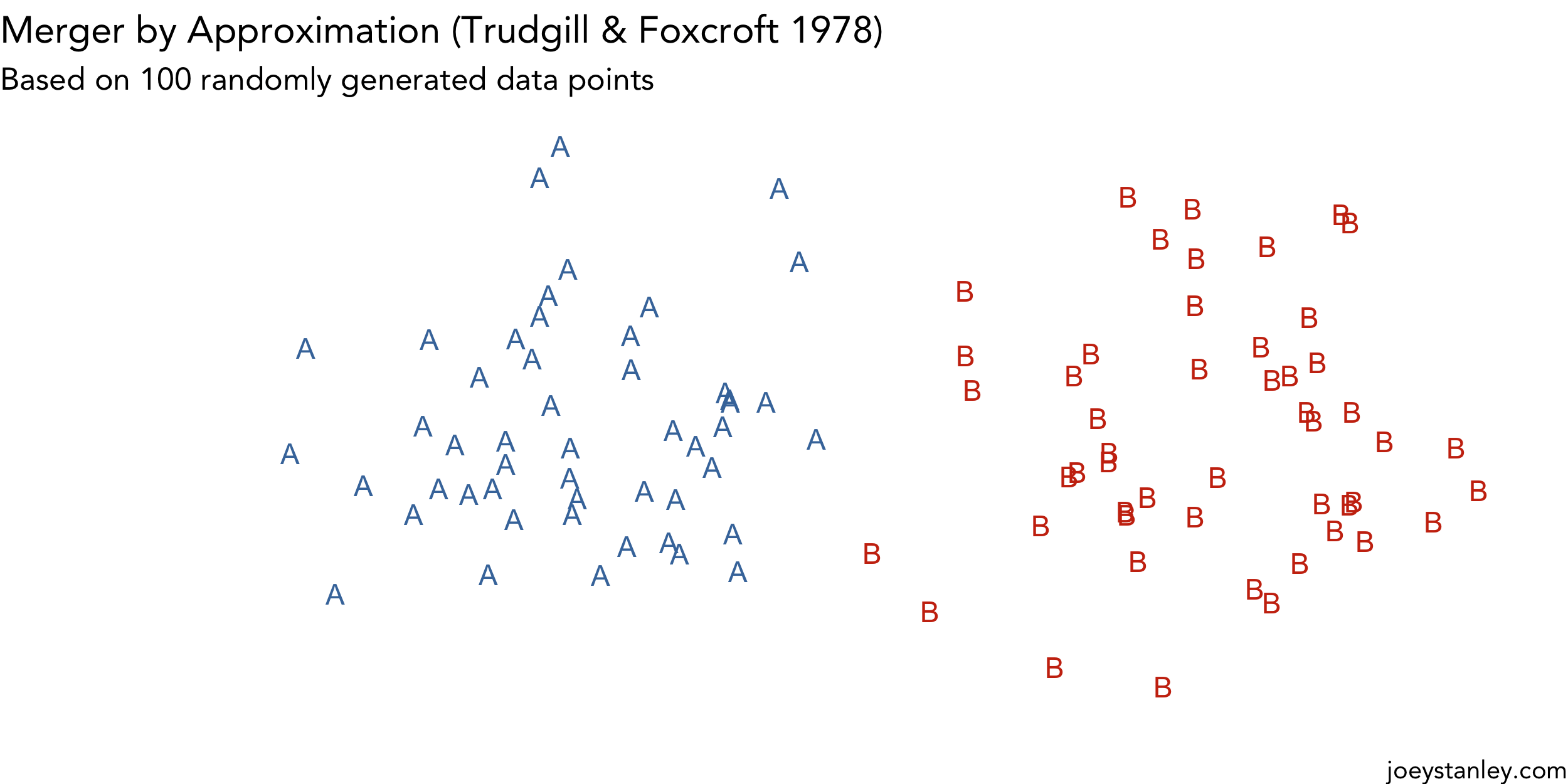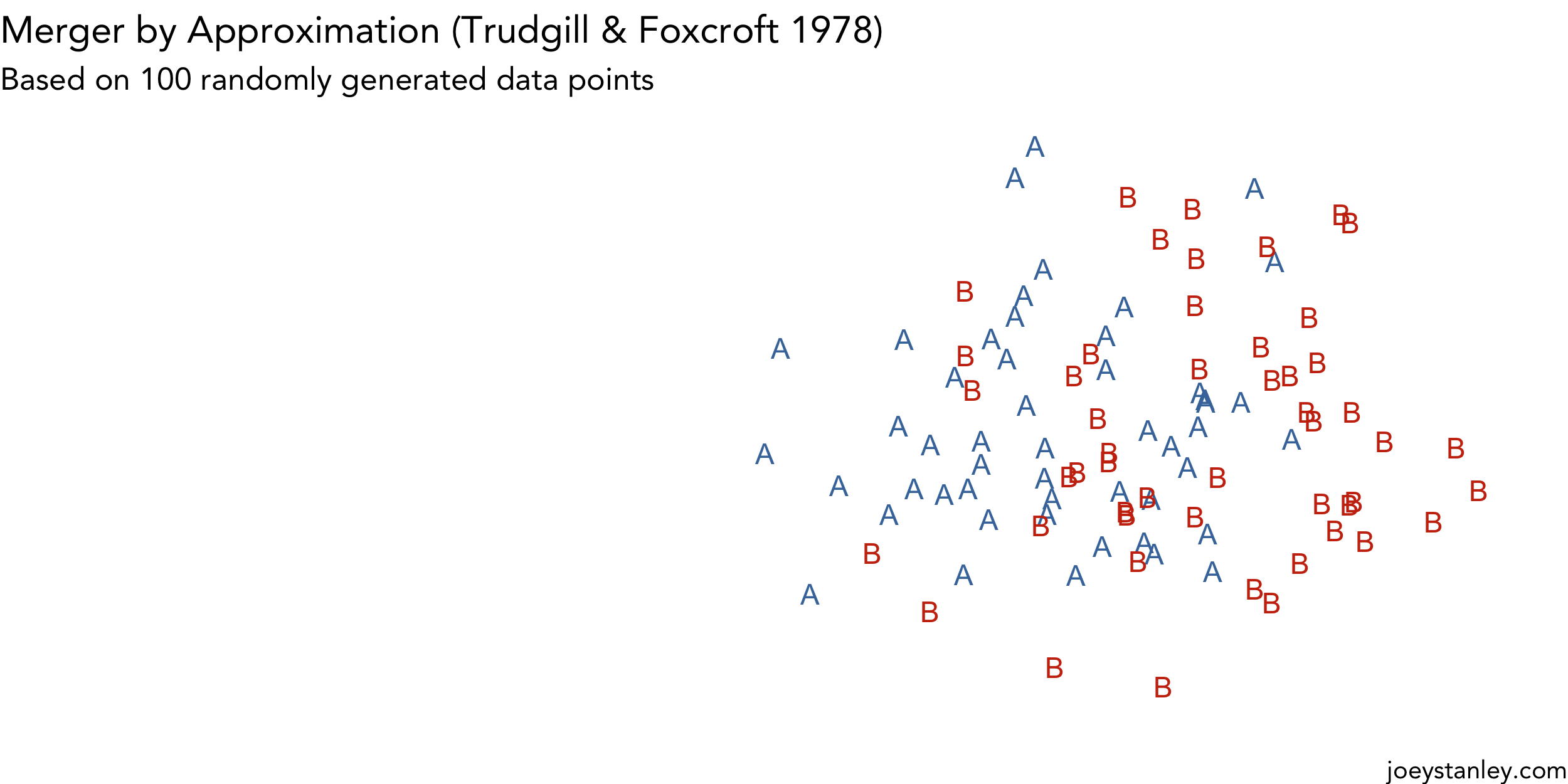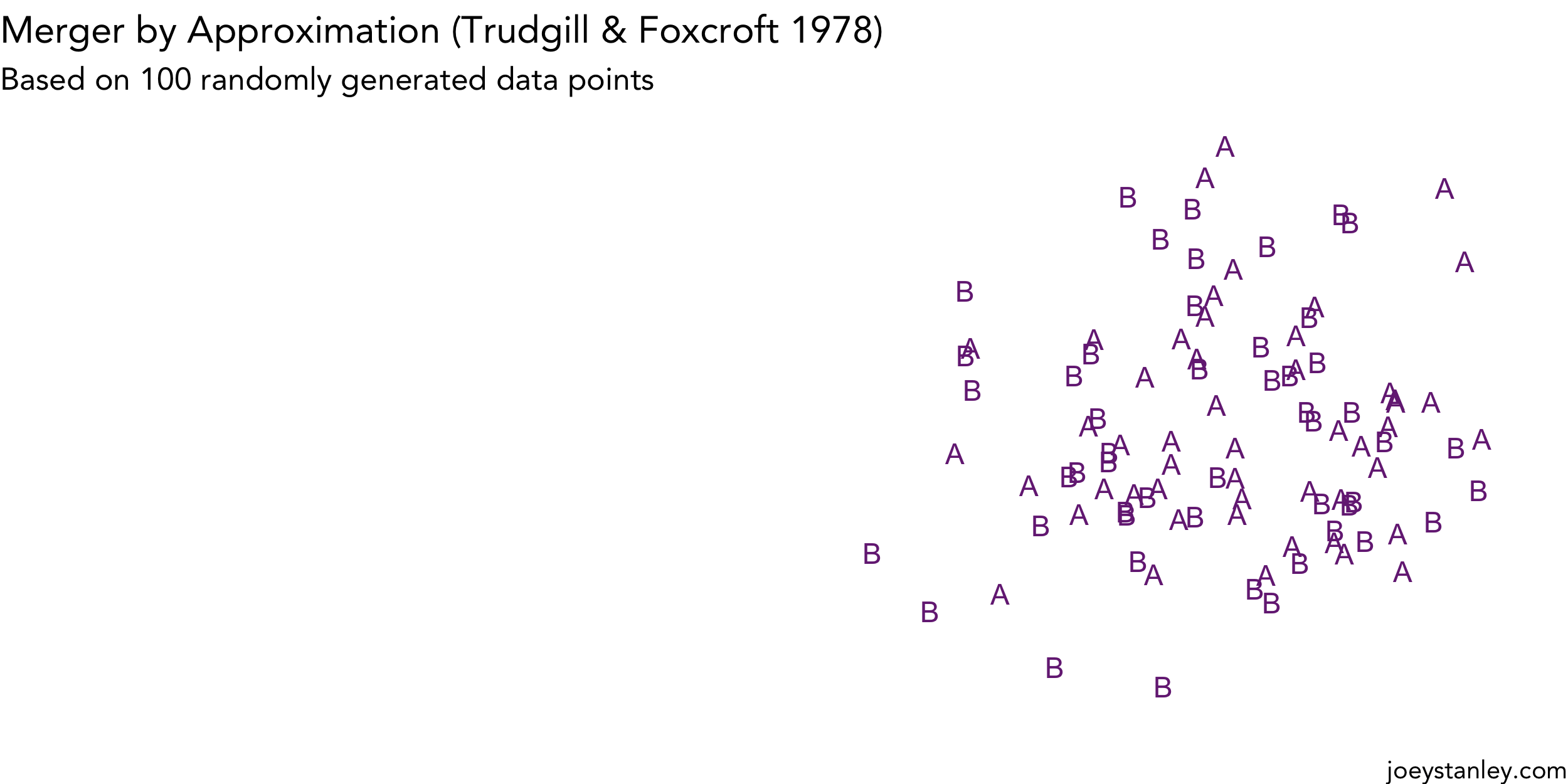
Animating Mergers
Animations
Data Viz
Github
R
Side Projects
Simulations
Teaching
I’ve dabbled with creating animations in R, but since the newest version of gganimate came out, I’ve been trying to find a useful way to use it. (I don’t know if visualizing simulations of…
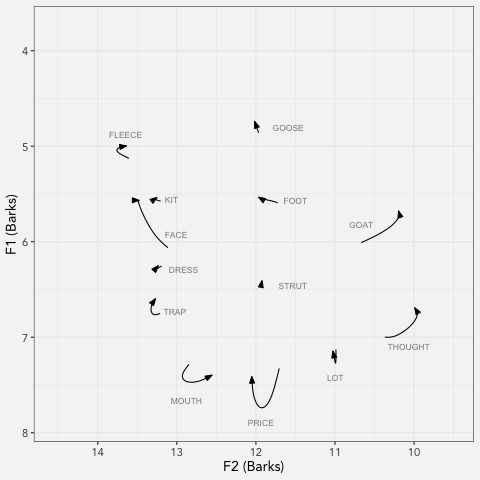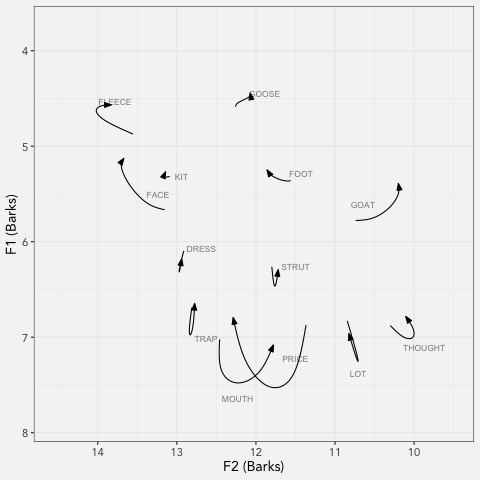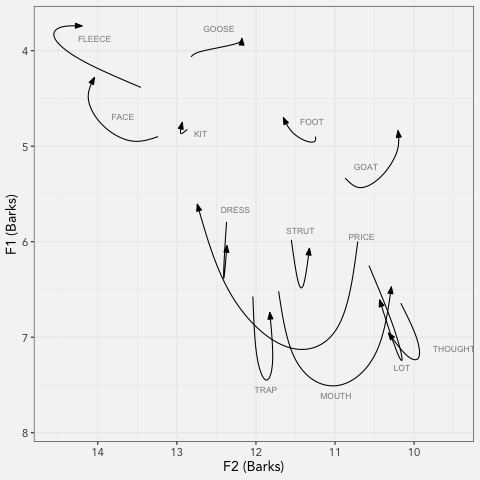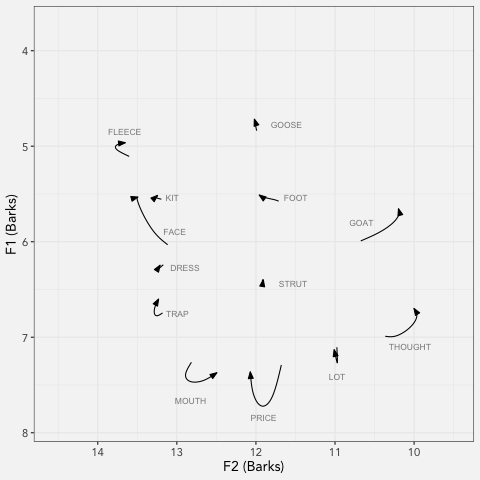
LCUGA6
Animations
Conferences
Linguistic Atlas
Presentations
Research
South
I presented at the 6th annual Linguistics Conference at UGA today! My presentation, which was called “Real Time Vowel Shifts in Georgia English” compared Georgians born…
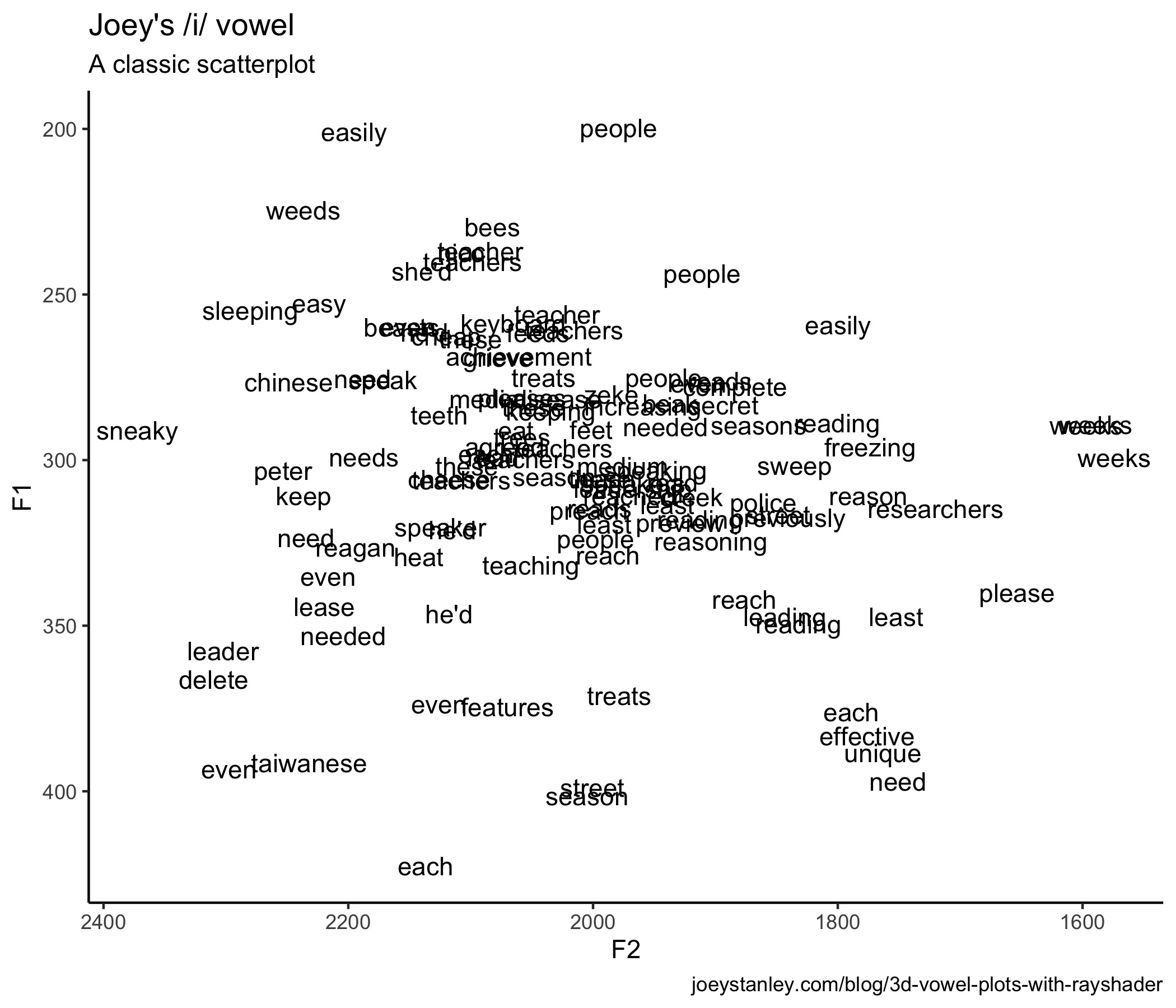
3D Vowel Plots with Rayshader
Animations
Data Viz
Github
How-to Guides
Phonetics
R
Side Projects
Skills
So Tyler Morgan-Wall has recently come out with the rayshader package and the R and data science Twitter community has been buzzing. I’ve seen people post some absolutely amazing 3D plots and animations. I haven’t seen any linguists…
Jealousy List 3
Jealousy Lists
Data Viz
R
Skills
Statistics
This is the third iteration of my Jealousy List, which is a list of…
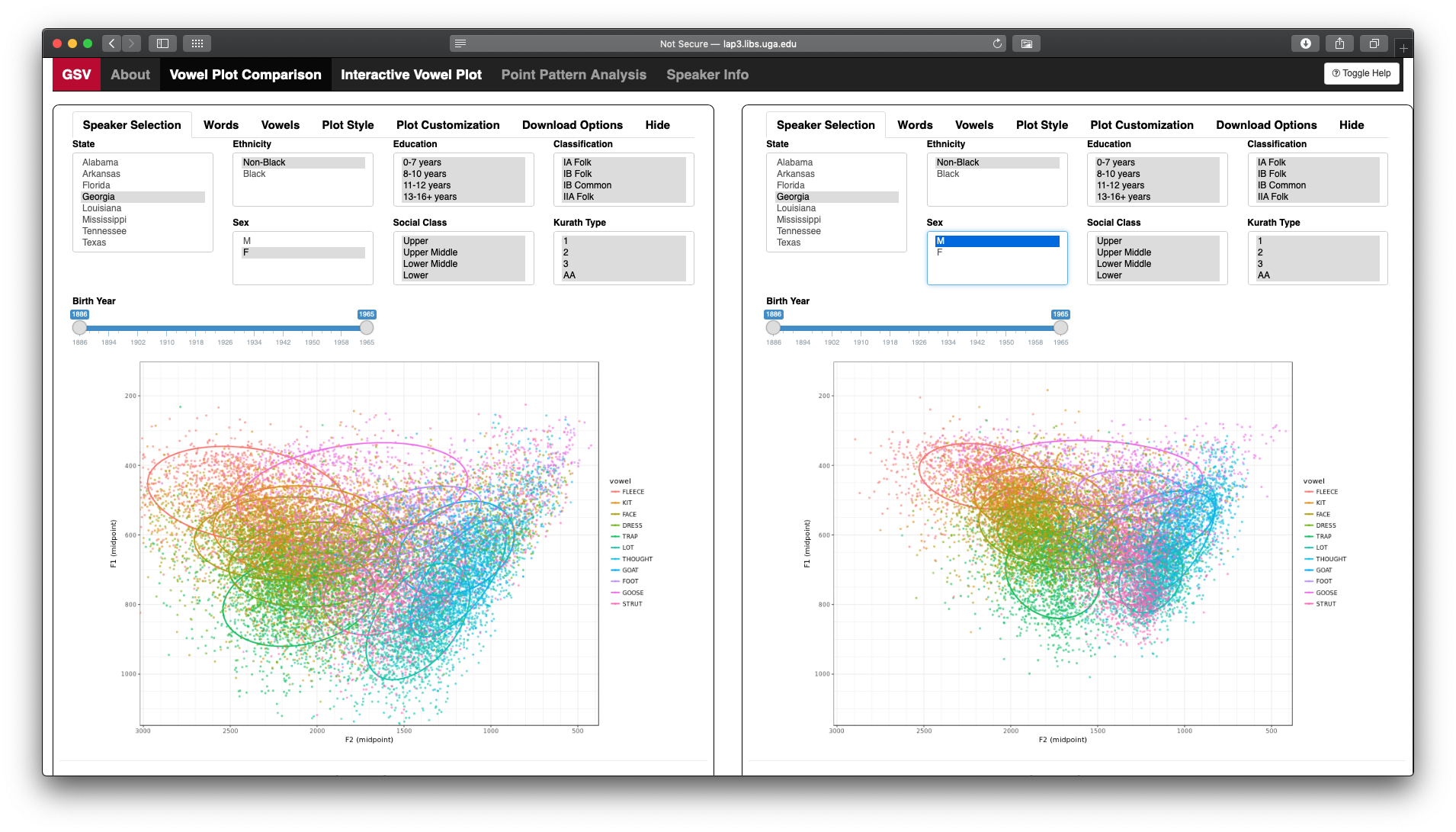
DH 2019
Conferences
Linguistic Atlas
Presentations
Research
South
At the Digital Humanities 2019 conference in Utrecht, the Netherlands, I presented with Bill Kretzschmar on ways to visualize a lot of phonetic data.
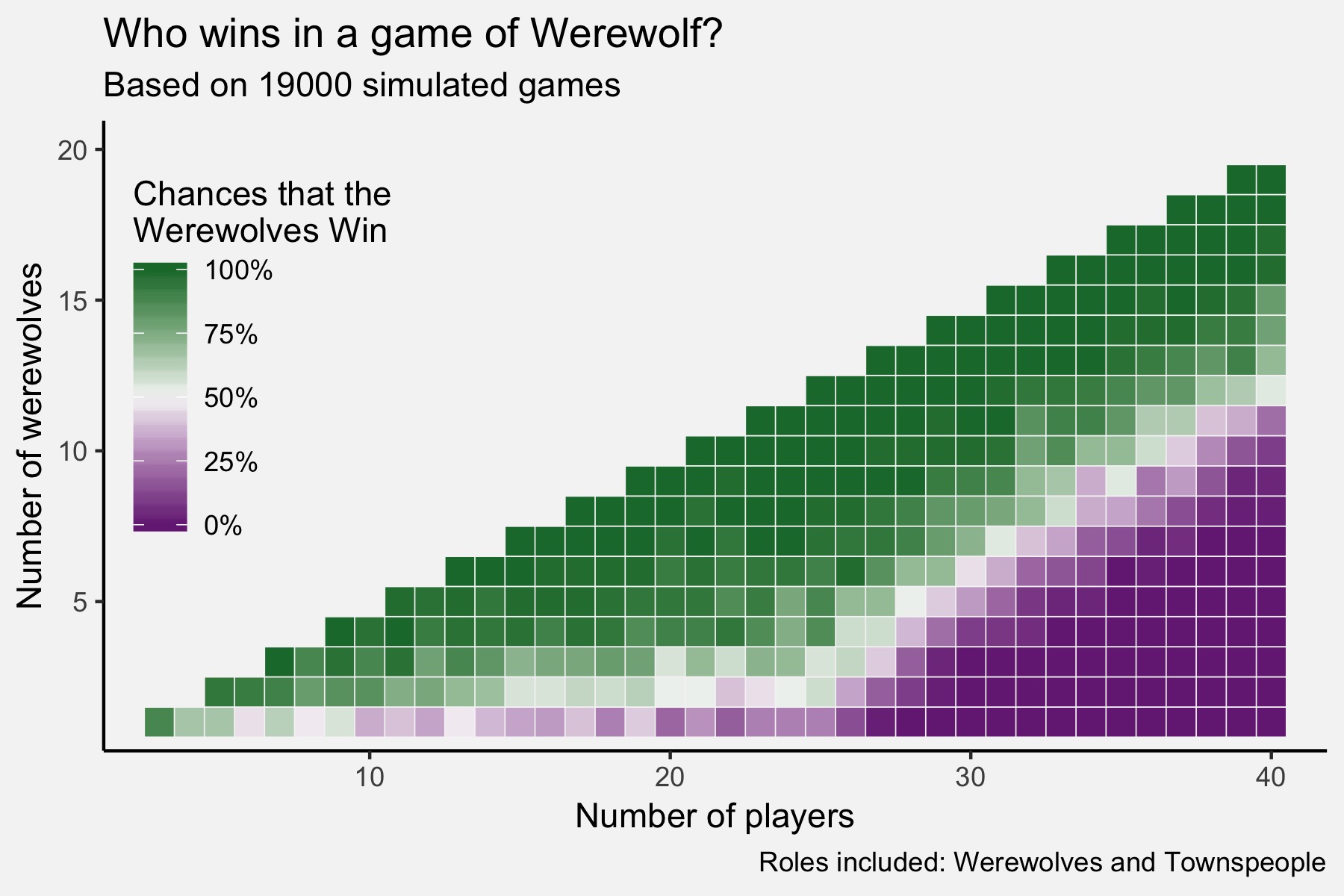
Simulating Werewolf
Github
Side Projects
Simulations
I really enjoy the party game called Werewolf. When I was an undergrad, I played it many…
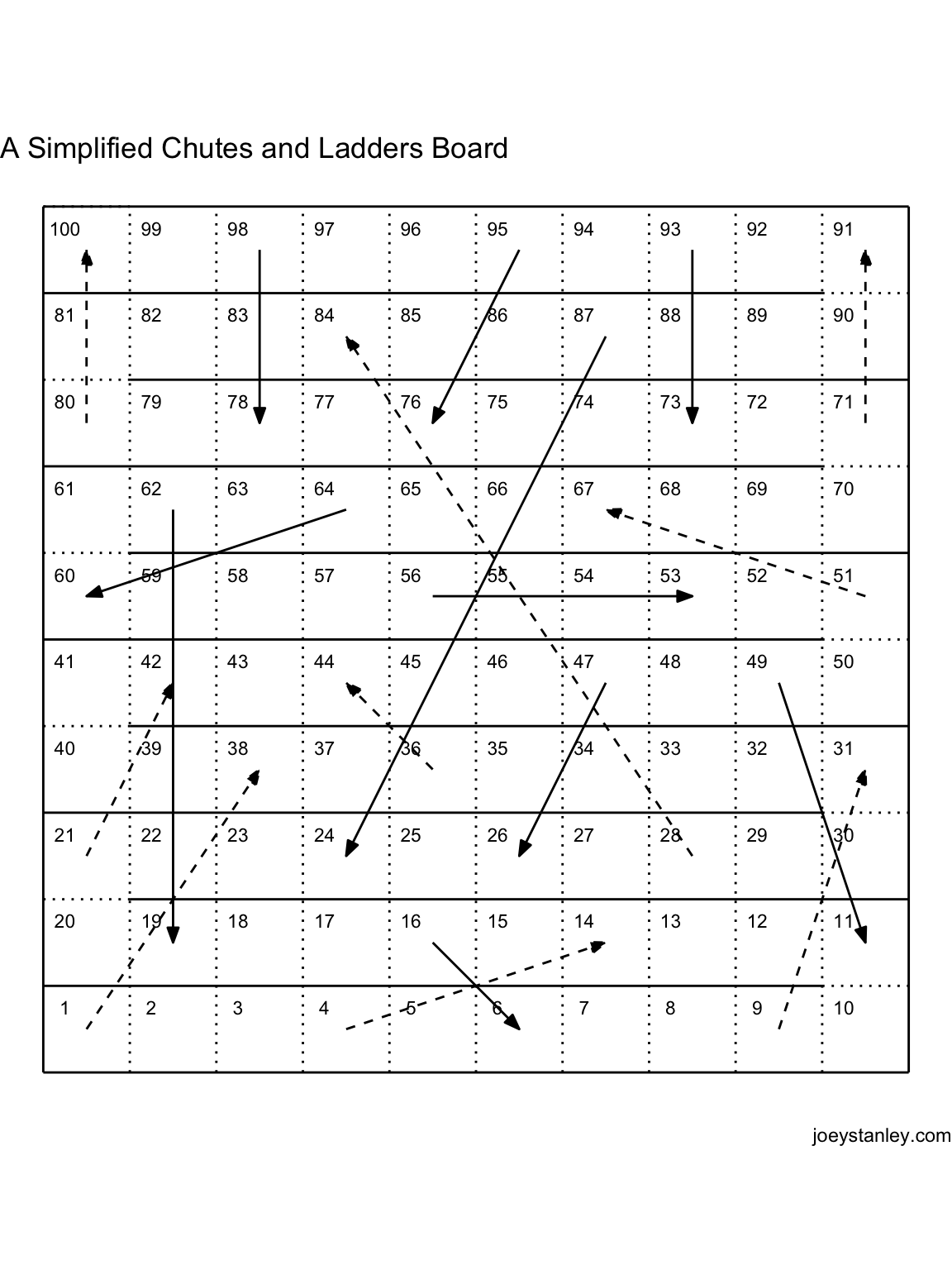
Simulating Chutes and Ladders
Animations
Github
Side Projects
Simulations
We tried teaching our little almost-three-year-old Chutes and Ladders today. She wasn’t very good at counting tiles. But, as I was sitting there climbing up and sliding down over and over, I wondered what the average number of turns it would…
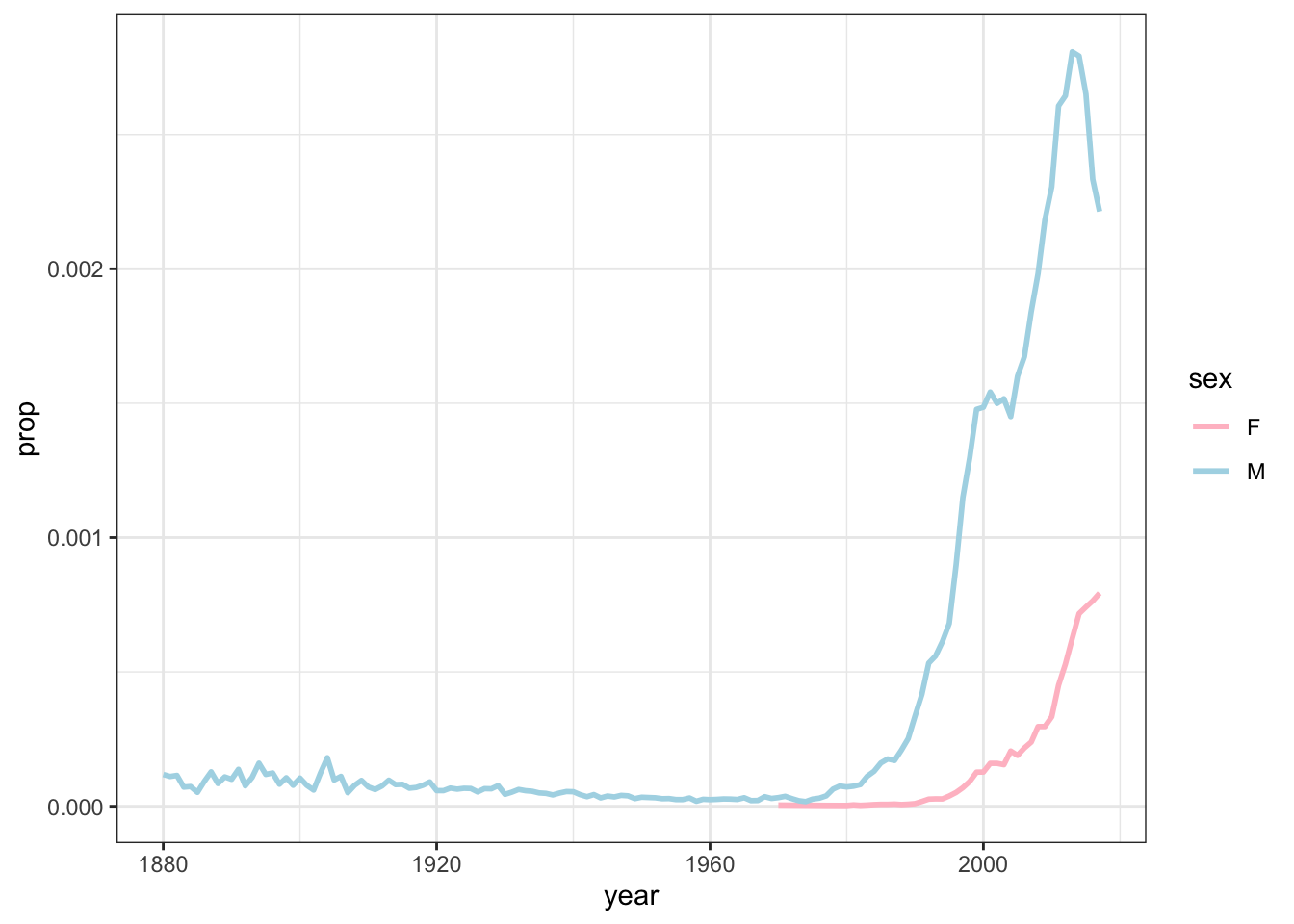
Assigning Pseudonyms in R with the babynames package
Github
How-to Guides
Methods
R
Side Projects
Skills
Recently, on RWeekly.org, I saw that Hadley Wickham’s babynames package had been updated. I had never heard of it, but when I saw that it contained Social Security data for births in the US from 1880 to 2017, I immediately thought…
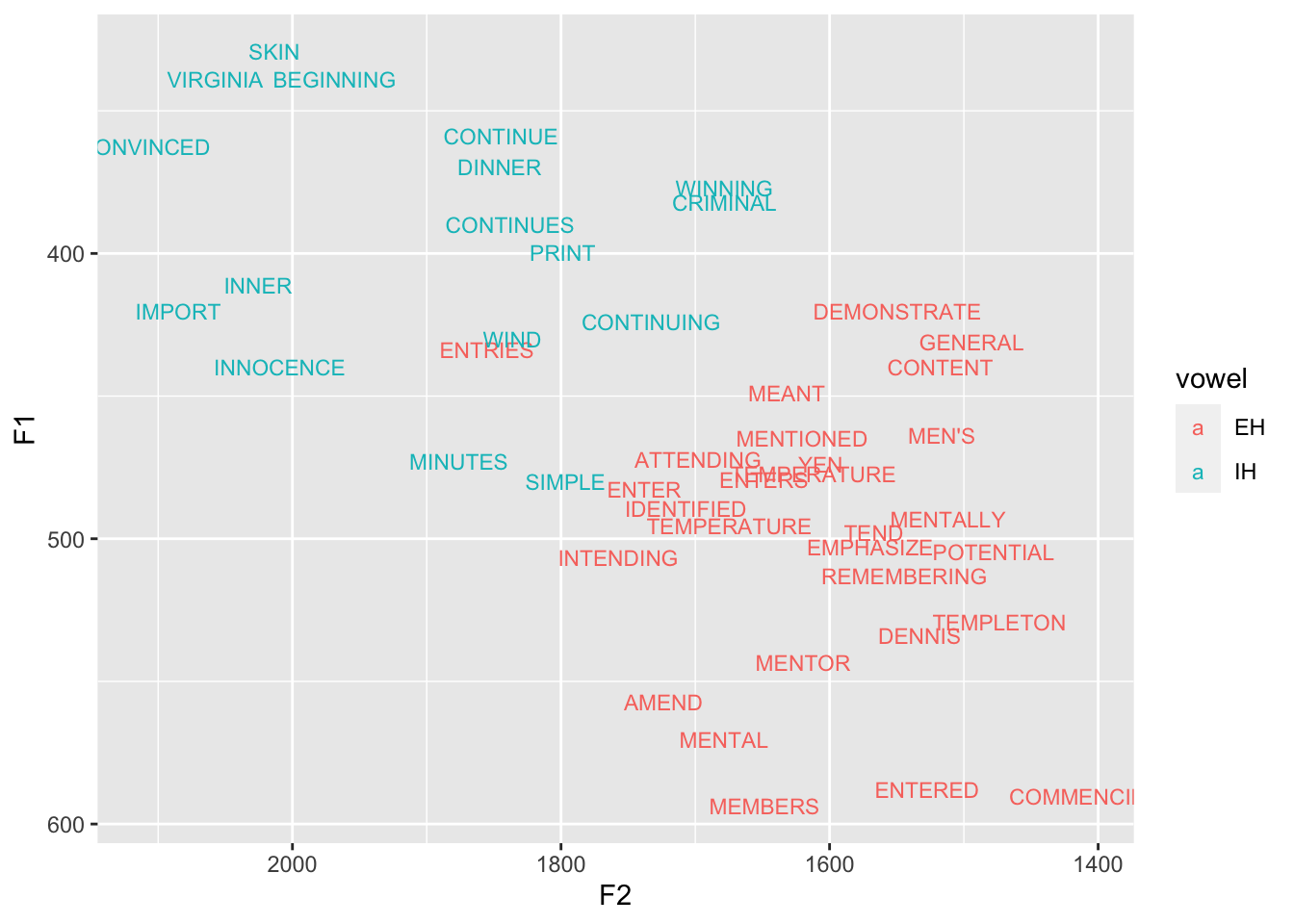
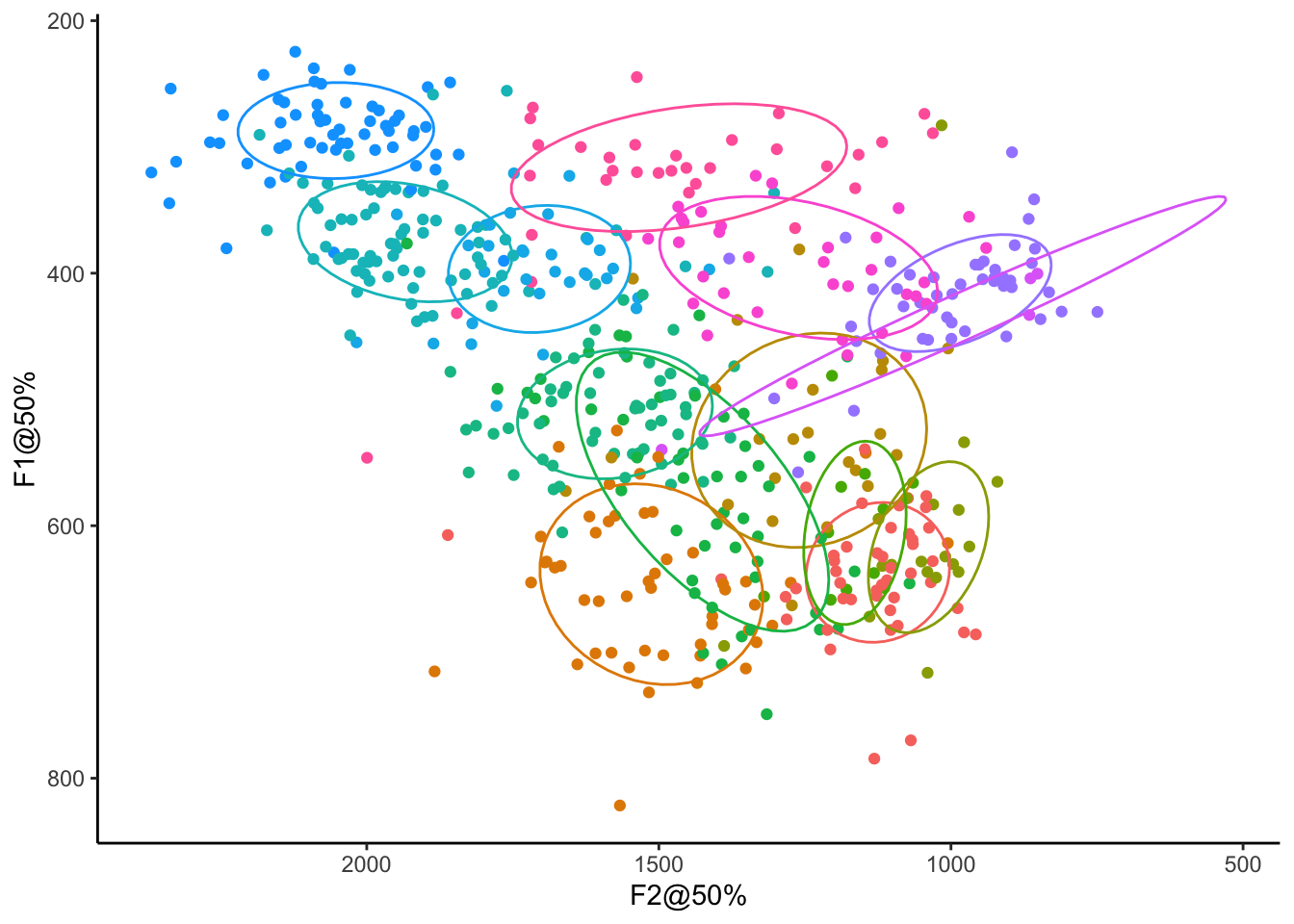
Vowel overlap in R: More advanced topics
How-to Guides
Methods
Phonetics
R
Skills
Data Viz
Vowel Overlap
This is a continuation of my previous tutorial on how to calculate Pillai scores and Bhattacharyya’s Affinity…
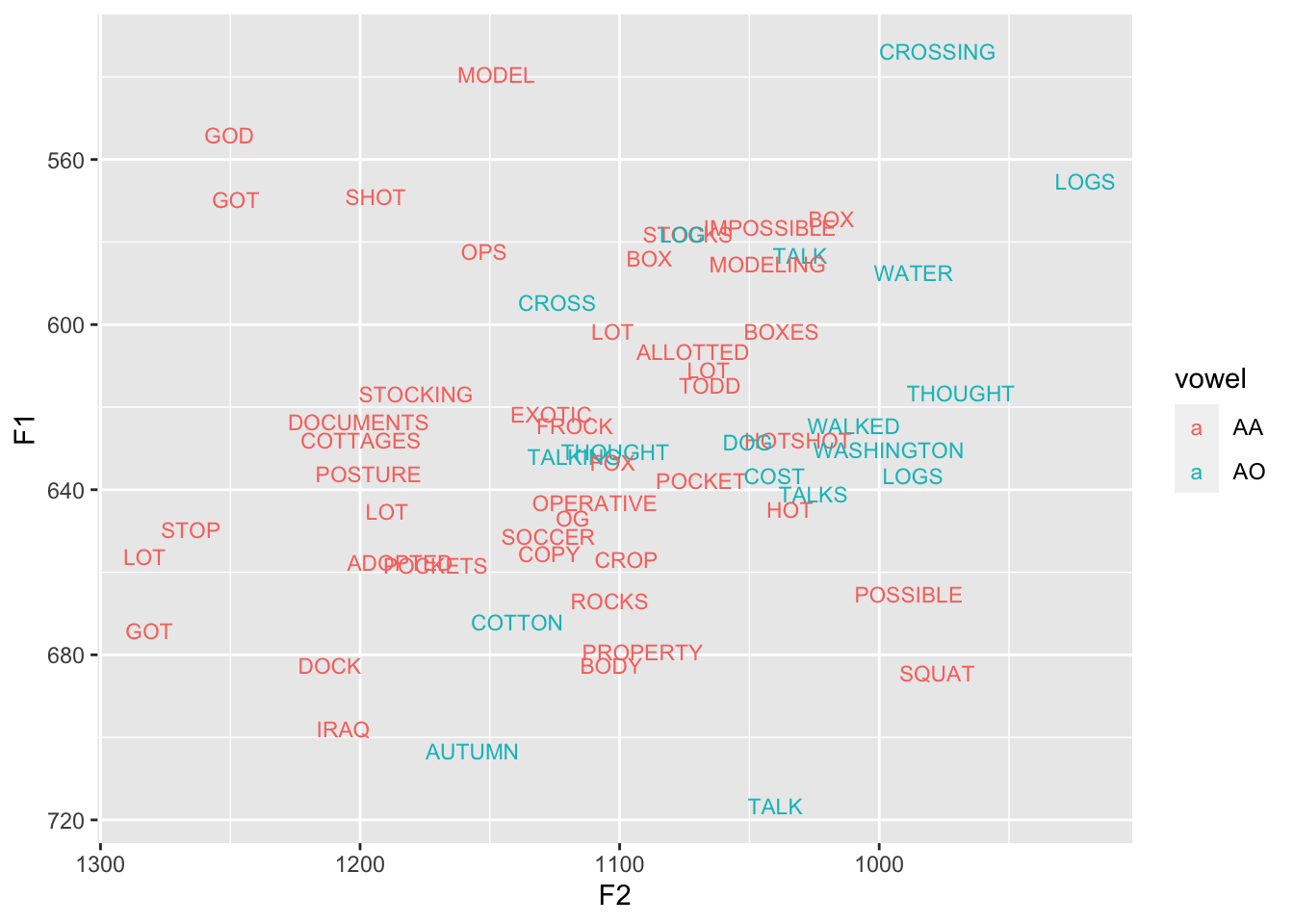
A tutorial in measuring vowel overlap in R
Data Viz
How-to Guides
Methods
Phonetics
R
Skills
Vowel Overlap
Please…
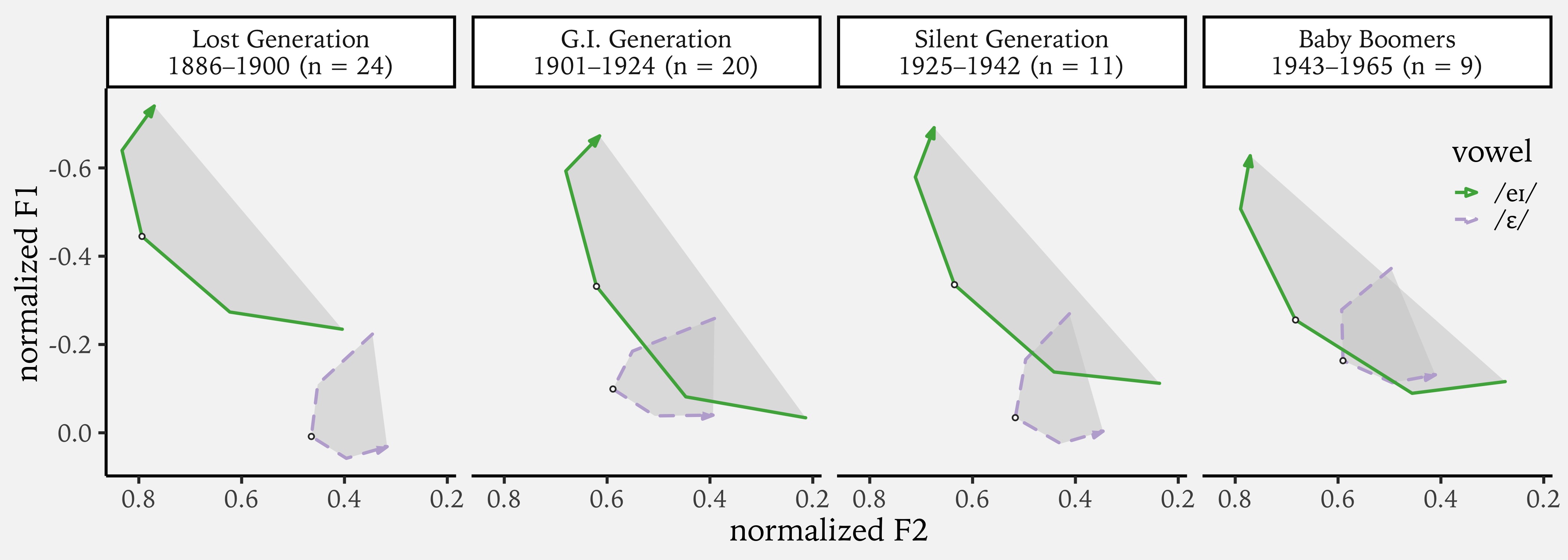
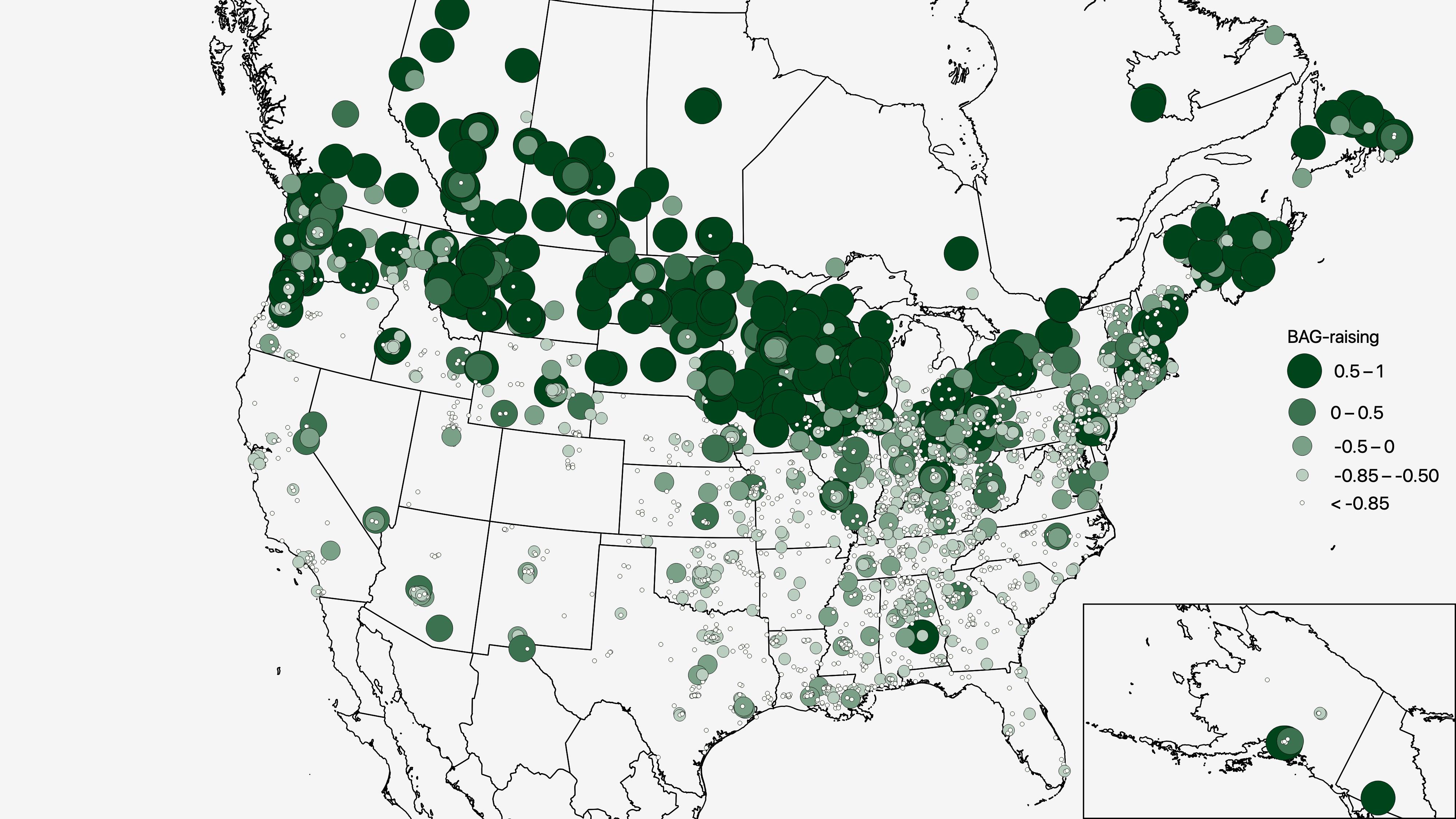
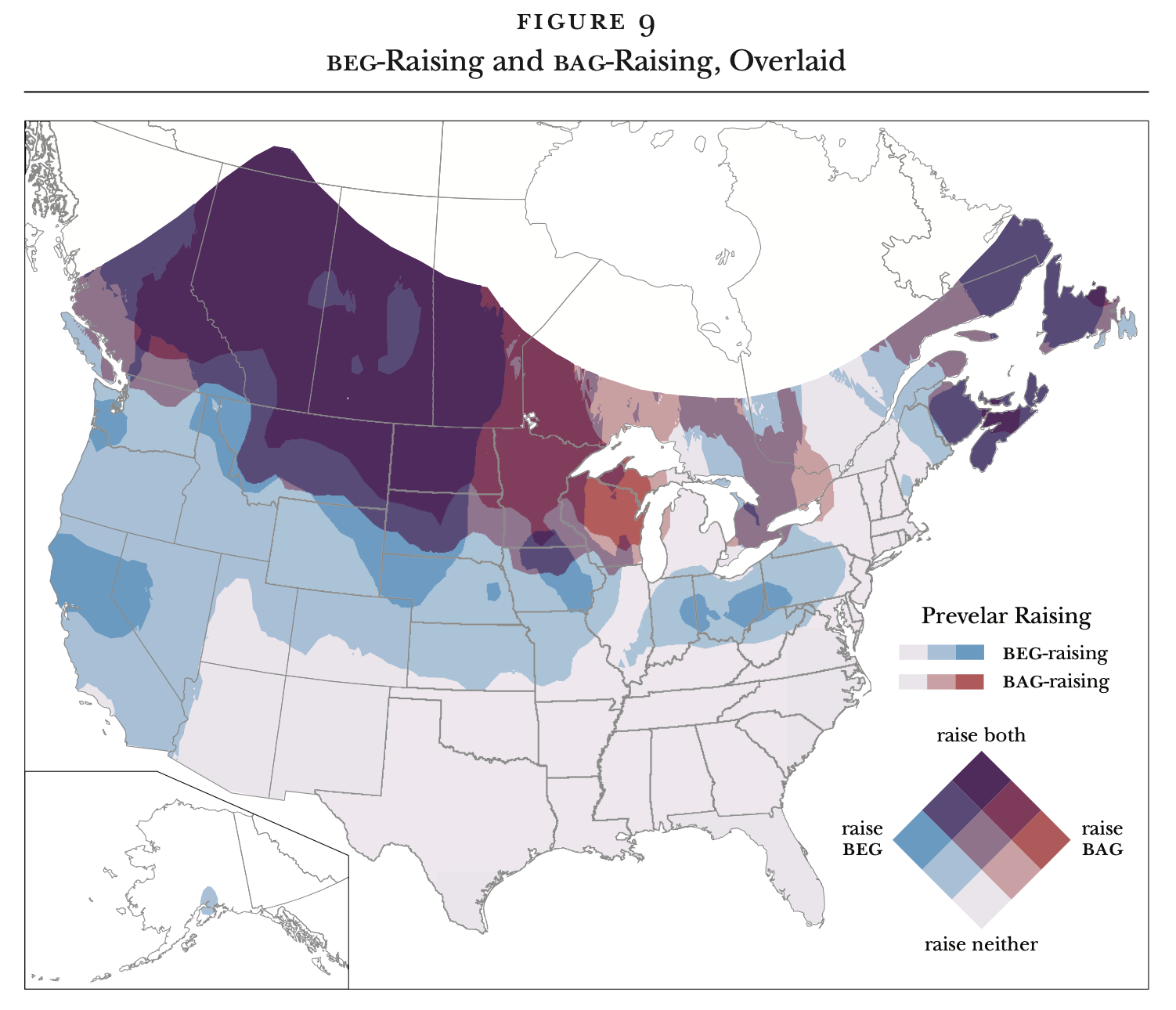
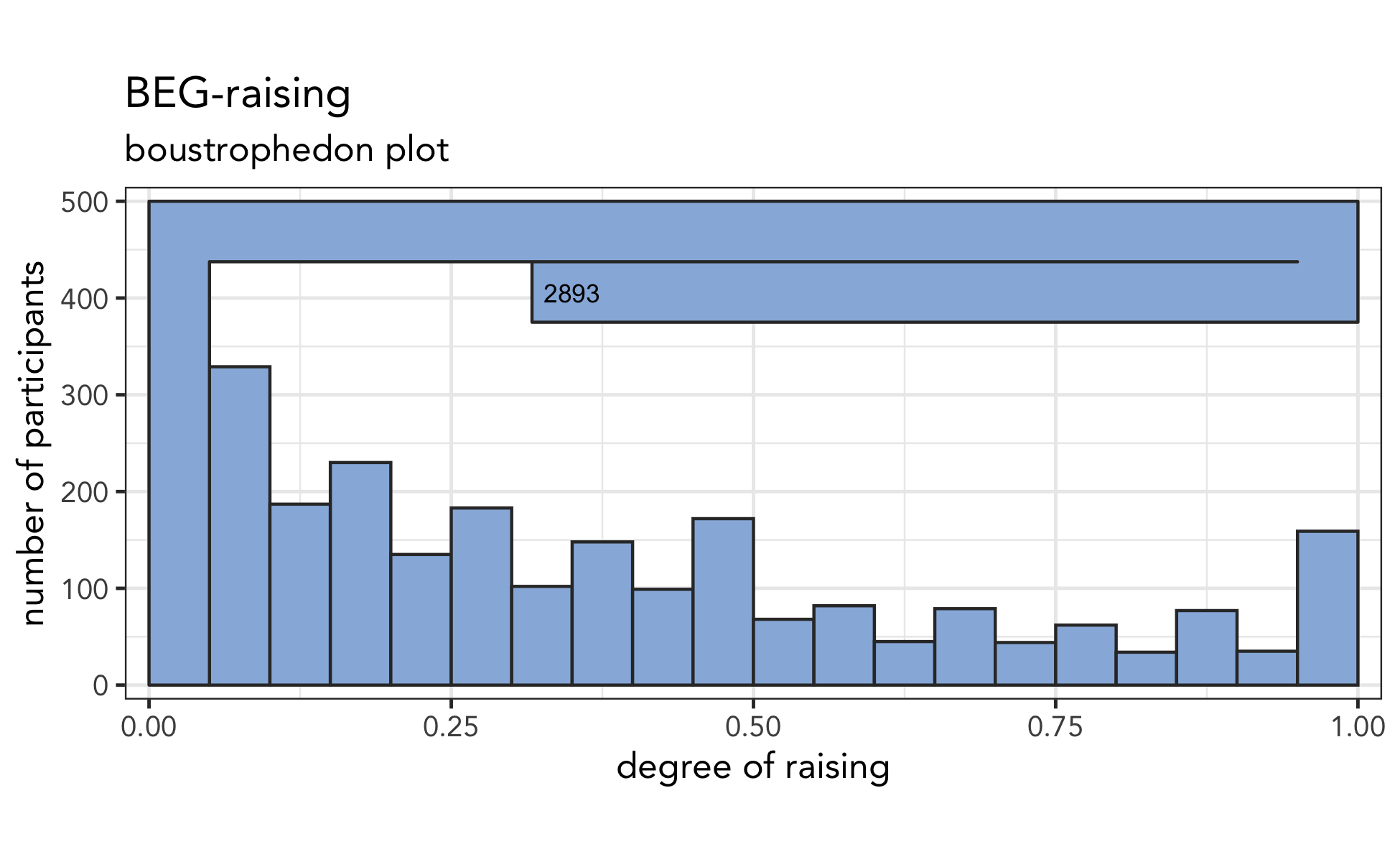
Prevelar Raising Survey Results
Side Projects
For the public
In April and May this year, I posted a survey to…

NWAV47
Conferences
Pacific Northwest
Presentations
Research
Today, I gave a poster presentation on prevelar raising. As it turns out, despite beg and bag being relatively small lexical classes, I found phonological, morphological, and lexical effects on the degree…
LCUGA5
Conferences
Pacific Northwest
Phonetics
Presentations
Research
South
Utah
Today, I was fortunate to give two presentations on very different areas of my research at the 5th Annual Linguistics Conference at UGA, one on an obscure consonantal phonological pattern in the West using new recordings and another on well-studied vowel…
Brand Yourself 2
CSS
Github
How-to Guides
Meta
Presentations
Twitter
Today, I was asked to do a professionalization workshop on different ways grad students can boost their online presence through building a personal webpage, utilizing social…
Jealousy List 1
Jealousy Lists
R
Skills
Statistics
GIS
Data Viz
This year, FiveThirtyEight started a monthly Jealousy List, which is essentially a list of…
Making vowel plots in R (Part 2)
How-to Guides
Methods
Phonetics
R
Skills
Data Viz
This post was written in 2018 and used code that was up-to-date at the time. In November 2023, I updated the code to reflect some changes in
tidyverse.

Making vowel plots in R (Part 1)
How-to Guides
Methods
Phonetics
R
Skills
Data Viz
This post was written in 2018 and used code that was up-to-date at the time. In November 2023, I updated the code to reflect changes in
dplyr.
365papers
Research
Side Projects
Twitter
Around the first of the year, I saw that several academics I follow on Twitter made a goal to…
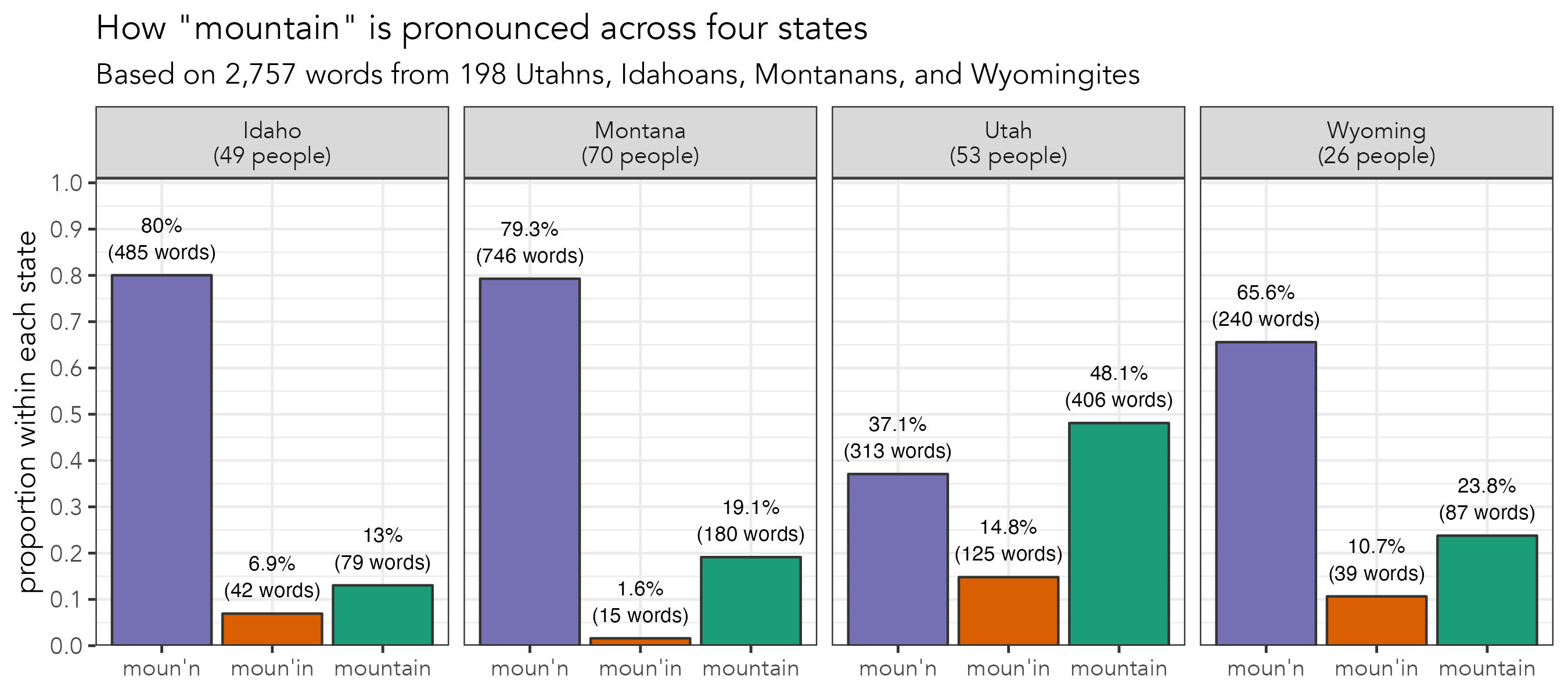
Randomizing a Wordlist
How-to Guides
Methods
R
Research
Skills
Utah
A few weeks ago I did some fieldwork in Utah and used a wordlist as part of my data…
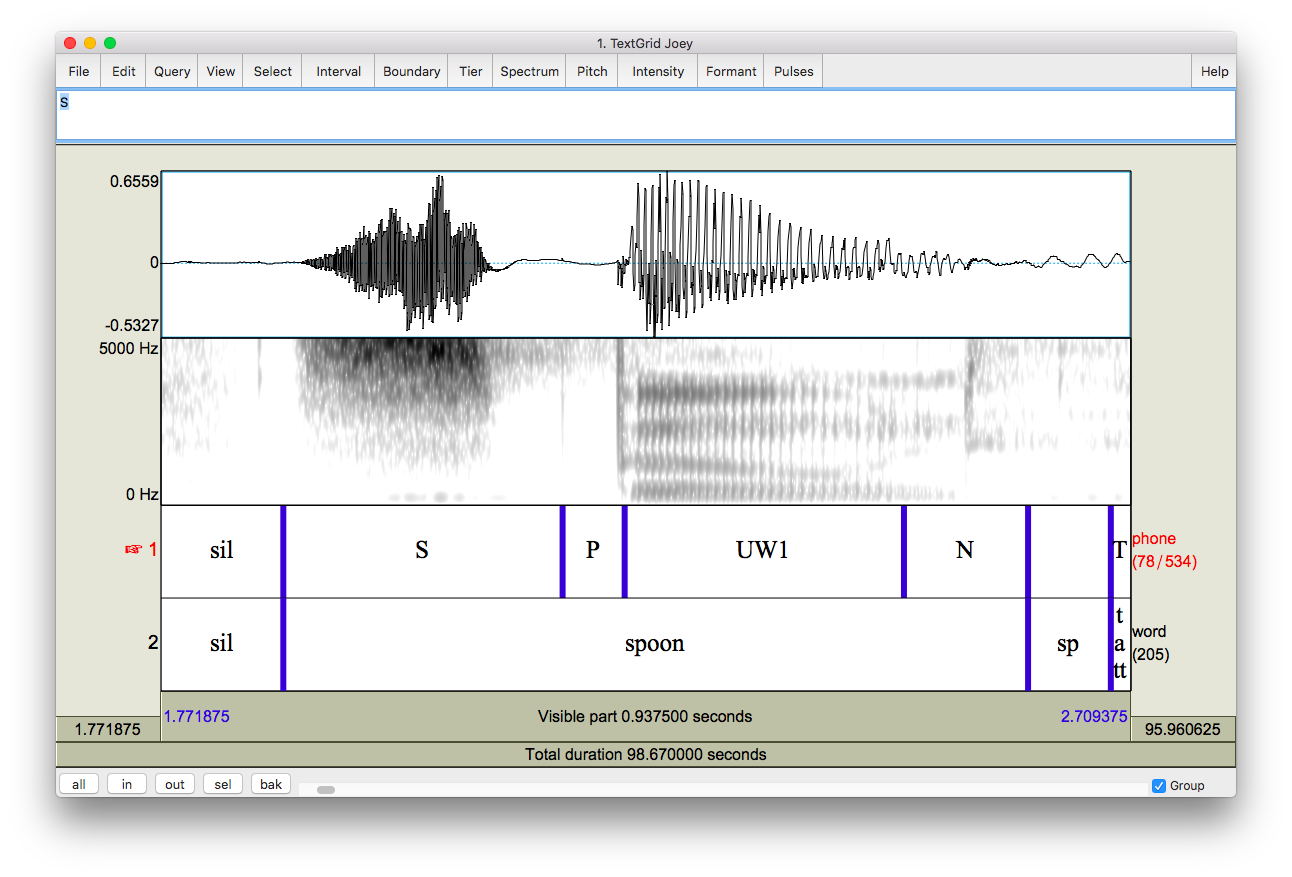

NWAV46
Conferences
Dissertation
Pacific Northwest
Presentations
Research
At the 46th New Way of Analyzing Variation conference in Madison, Wisconsin, I presented a poster called Changes in the Timber Industry as a Catalyst for Linguistic Change.
LCUGA4
Conferences
Pacific Northwest
Presentations
Research
Utah
This weekend, I had the opportunity to present twice at the 4th Annual Linguistics Conference at UGA. One was planned and the other was a…
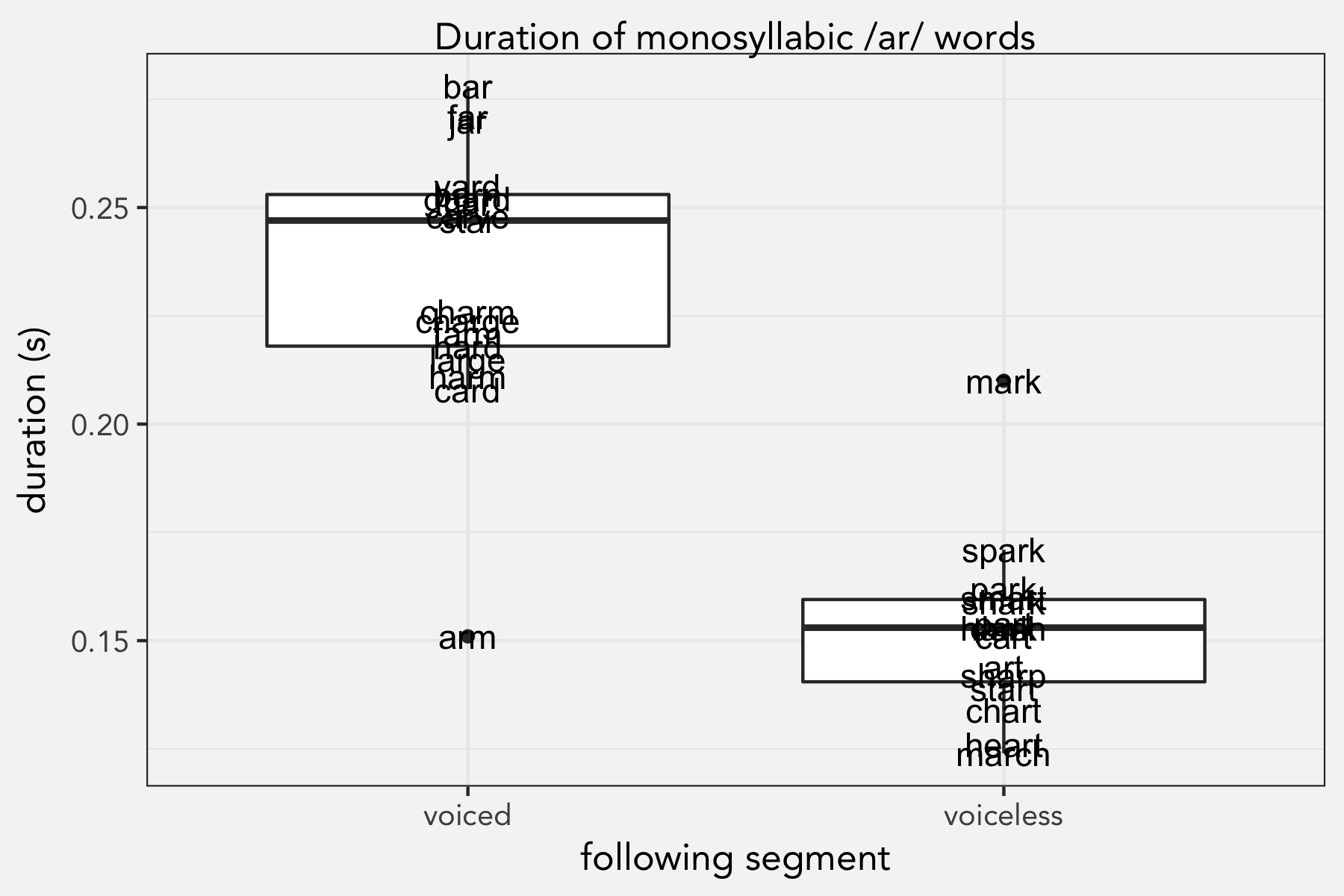
/ɑr/-Raising
Side Projects
Phonetics
Statistics
I’ve noticed for a while in my own speech that the vowel in star is higher and longer than start. I have American Raising, which, simplifying a bit, is where /aɪ/ is raised before voiceless consonants. So I just expected this to be another manifestation of that. I had…
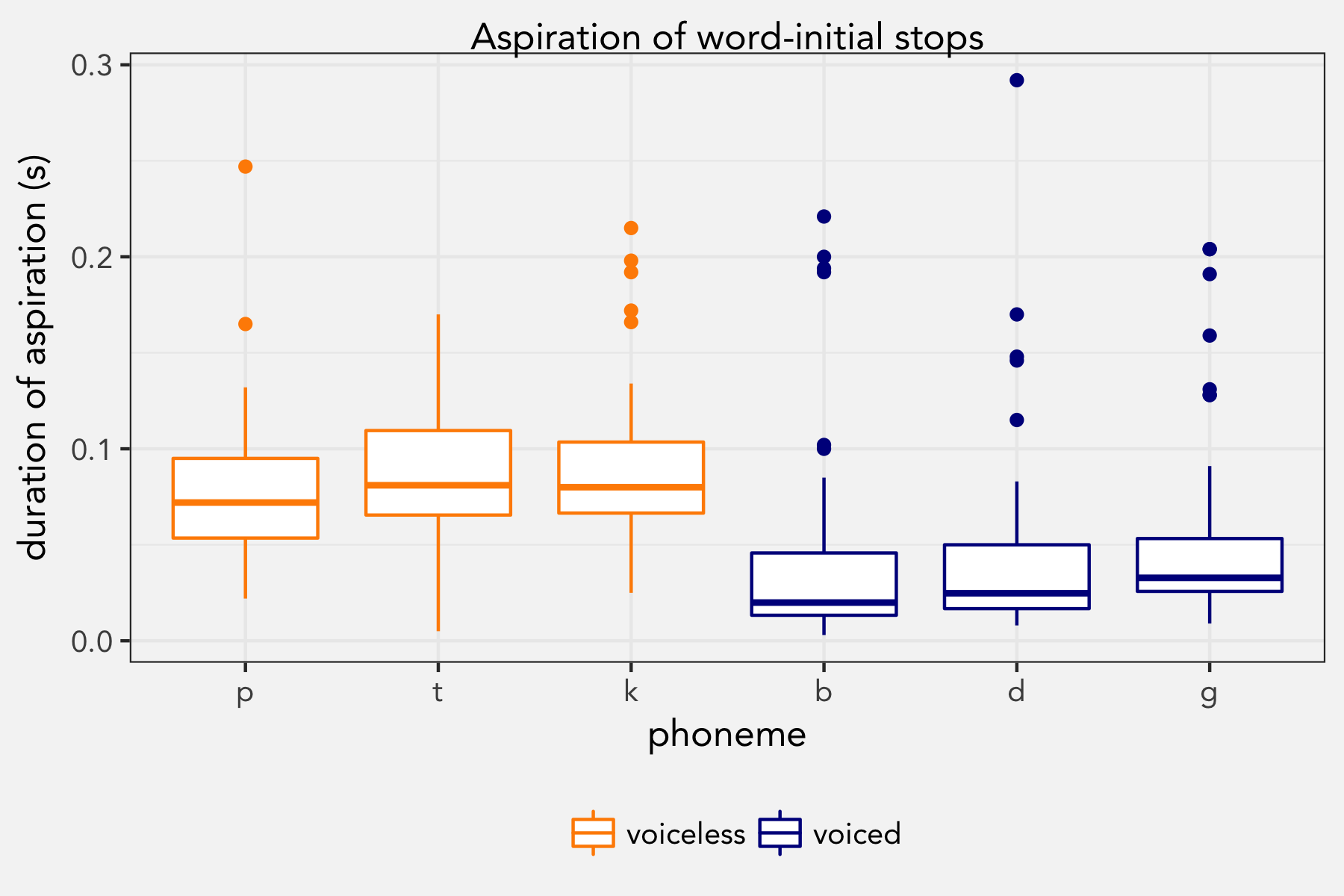
Testing VOT Durations in A Course in Phonetics
Side Projects
Teaching
Statistics
Phonetics
So I’m teaching phonetics and phonology this semester and we’re using Ladefoged & Johnson’s A Course in Phonetics textbook. As I was preparing to teach about stops, I thought it might be a good idea as a homework assignment for students to gather their own data…
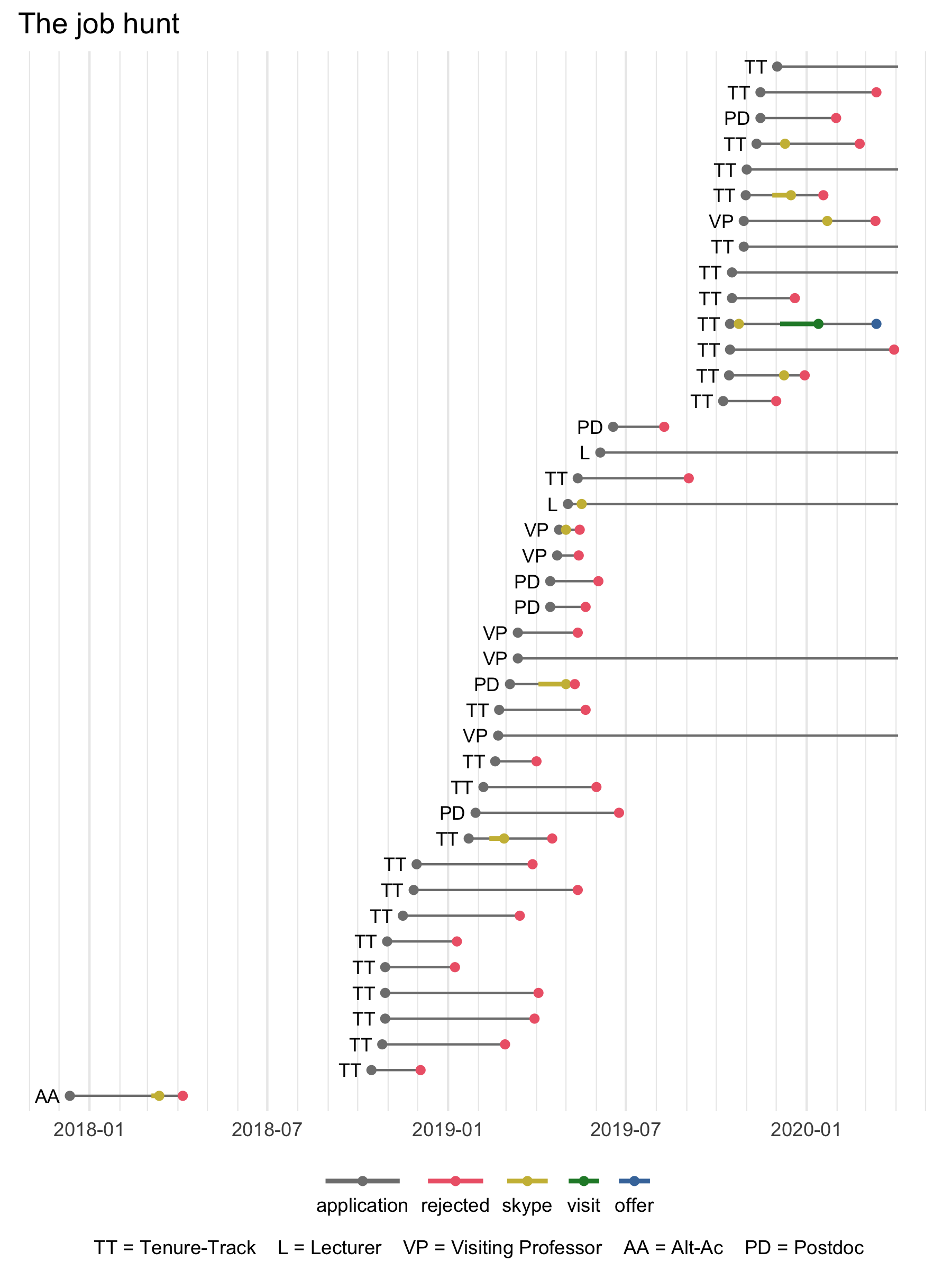
General Update
West
Utah
MTurk
Research
Conferences
Linguistic Atlas
Pacific Northwest
Dissertation
Because I know I have such a massive following, I thought I’d give an update on my research since it’s been a few months since the last time I wrote.
Using MTurk
Research
West
Pacific Northwest
MTurk
A few weeks ago, I wroteabout a grant I was awarded where I’ll use Amazon…

SECOL 2017
Conferences
Linguistic Atlas
Presentations
Research
Skills
I was unable to attend this year, but my colleagues presented two papers I was a part of at the 84th Southeastern Conference on Linguistics (SECOL84)…
Updated mvnorm.etest() function
Statistics
R
Skills
In Levshina’s How to do Linguistics with R, the function
mvnorm.etest() from the energy library is used. This runs what’s called the “E-statistic (Energy) Test of Multivariate Normality” which used to test whether multivariate data is normally distributed.…
LSA2017
Pacific Northwest
Conferences
Research
Last weekend, I had the opportunity to present at the 2017 Annual Meeting of the American Dialect…
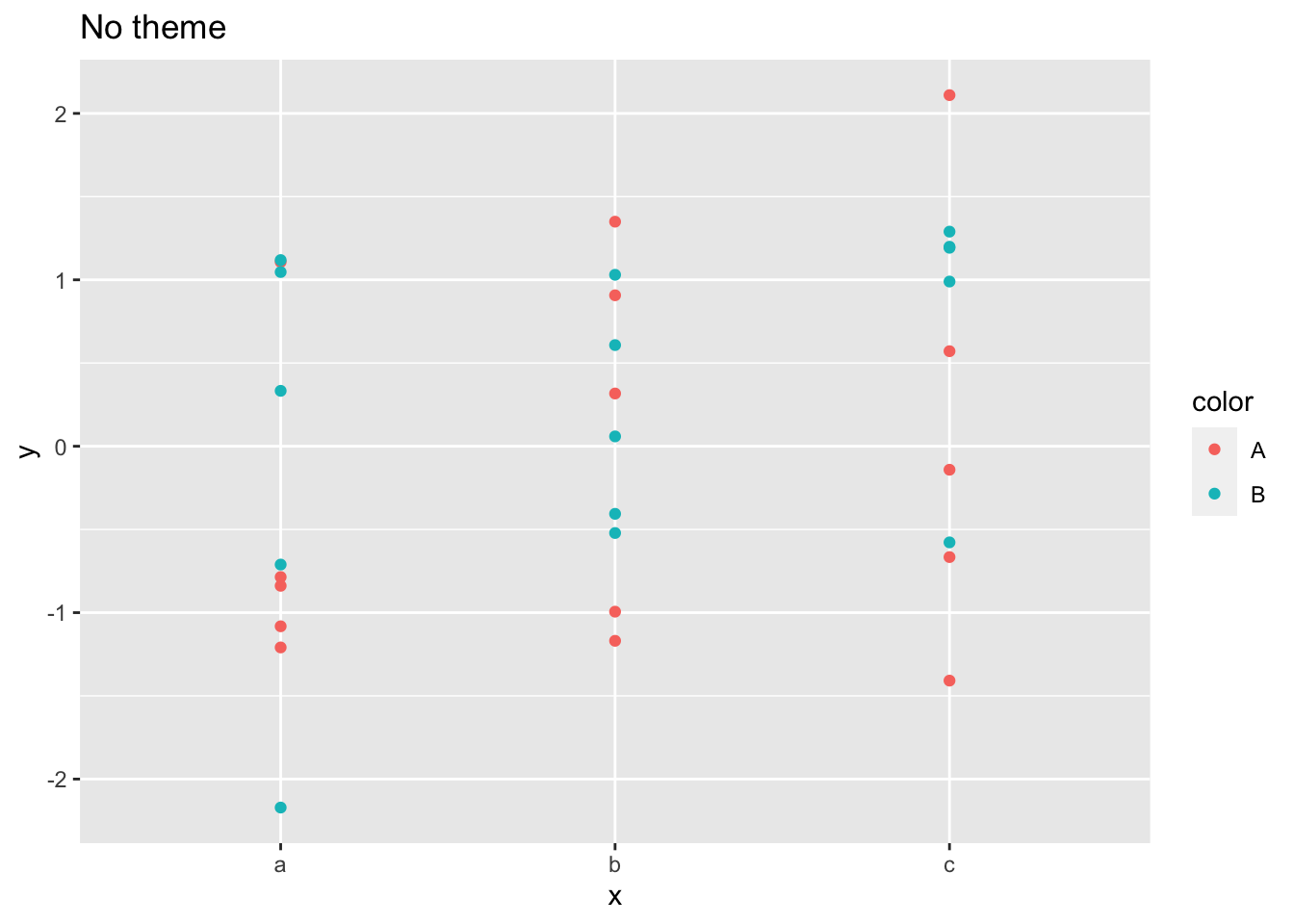
Custom Themes in ggplot2
How-to Guides
Methods
Skills
R
Data Viz
For additional detail and updated information on creating custom themes, see this handout…

Brand Yourself
CSS
Github
How-to Guides
Meta
Presentations
Twitter
Today Emily McGinn of the Digital Humanities Lab at UGA and I did a professionalization workshop for grad students. We gave a presentation on different ways grad students can boost their online presence through building a personal webpage, utilizing social media, and finding your field’s conversation. We then let the attendees a chance to work on their own to create a new online profile, using what they learned.
DiVar
Conferences
Pacific Northwest
Research
I’m excited to announce I’ve been accepted to present at the first iteration of the Diversity and Variation in Language Conference (DiVar1), which will be held at Emory University in Atlanta February 10–11. I’m excited to hear that many of my colleagues at UGA have also been…
The Importance of Twitter
How-to Guides
Methods
Research
Twitter
I’m preparing a workshop right now for the…
JMP
Data Viz
Presentations
Skills
Statistics
As a part of my assistantship this year, I get to work with the DigiLab in the Main Library…
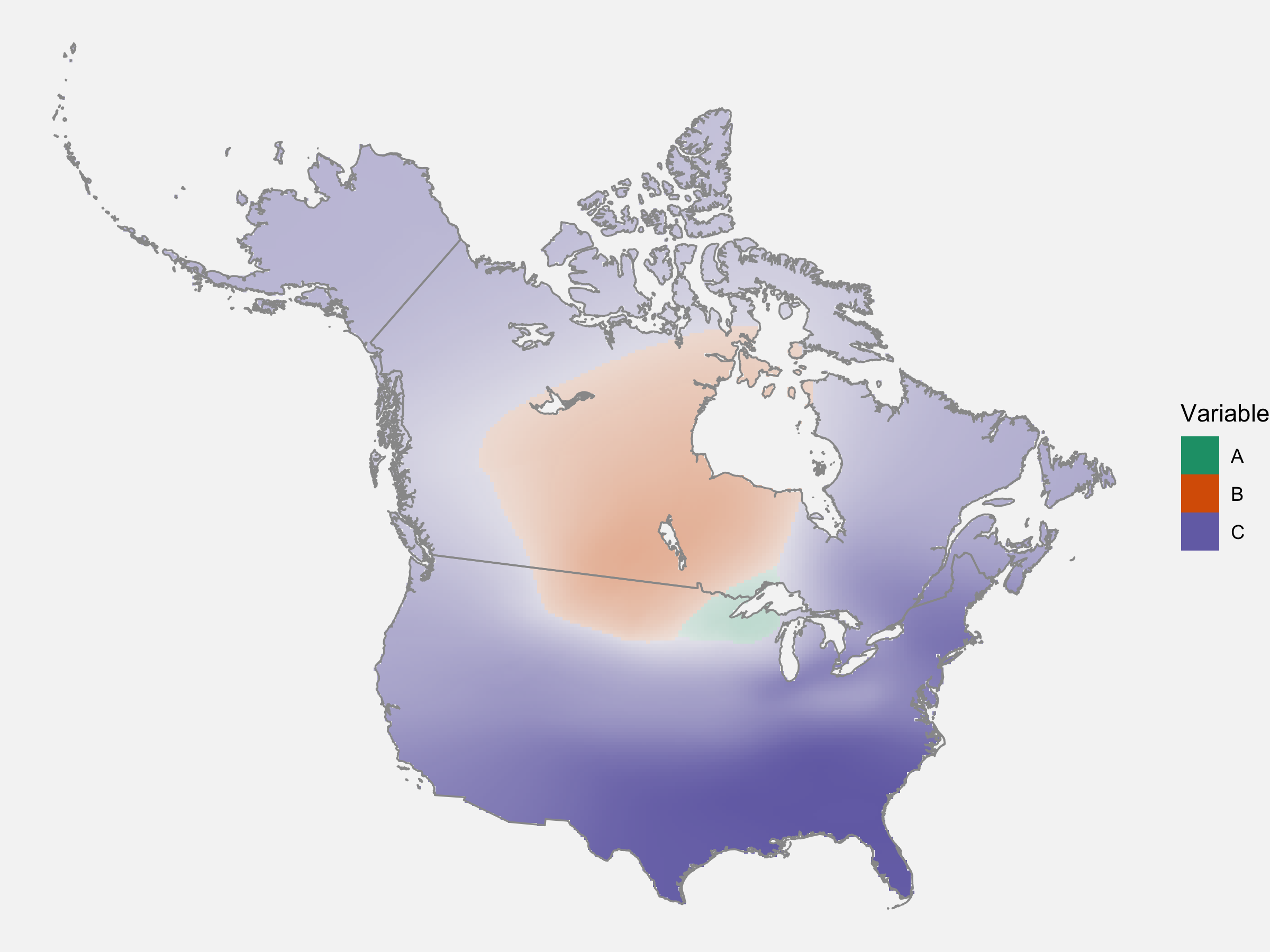
The Linguistic Atlas of the Pacific Northwest
Linguistic Atlas
Pacific Northwest
Research
As a part of my research assistantship this year, I work with the Linguistic Atlas Project…
ADS Meeting!
Conferences
Pacific Northwest
Research
I’m thrilled to announce I’ve been accepted to present a paper at the 2017 annual conference of the American Dialect Society!
No matching items