This year, FiveThirtyEight started a monthly Jealousy List, which is essentially a list of really cool articles they saw other people do that they wish they had been the ones to write. This is an idea they got from Bloomberg and I think others are starting to do their own as well. It’s kind of a fun way to showcase some of the best stuff that has come out recently and to share others’ work. I kinda like the idea so I thought I’d start an occasional jealousy list of my own.
I’m a linguist at heart, but because I’m interested learning more about R and statistics, I tend to keep tabs on a lot of what’s going on in the data science world. I follow a lot of data scientists on Twitter and I’m also subscribed to something like 50 academics’ blogs that I read when I have a spare minute. Consequently, most of what I’ll post here will probably not be directly related to linguistics, but they’ll show off some really cool R skills. Things that I find really cool or I wish I could have been the one to do write it. I tend to share some of this kind of stuff on Twitter, but I thought I’d start compiling them here.
So, in no particular order, here is a list of some of the things I liked the most in the past few weeks/months. Some are tutorials, others are just information, but they’re all stuff I jealously wish I could have written:
Helen Graham. “Now that’s what I call text mining and sentiment analysis”
This is an analysis of all the lyrics in the 100 Now! music albums. (Yeah, those are still a thing, and the UK series just released their hundredth album!) First, they use
rvestfor web scraping andgeniusRfor extracting the lyrics from genius.com. But the real fun comes fromtidytextand looking at how word usage, sentiments, and other trends change over time. I’ve never done we scraping but I feel like maybe it’s not so hard after reading this.Listen Data. “15 Types of Regression you should Know”
This is just a quick overview of lots of different kinds of regression analysis. I took a course in regression so I felt pretty confident going into this, but I learned about some cool types of models that I hadn’t heard of like Lasso, Poisson, and other fancier ones. There’s some brief R code and a simple explanation of how each is different from the others. I’m particularly interested in the Poisson regression and wonder how that might be used in corpus studies.
Laura Ellis. “Highlighting with ggplot2: The Old School and New School Way”
Something that you might need to do in ggplot2 is to highlight data. This author explains two ways to do that. I had been doing what they refer to as the “old school” way, which is essentially overlay a second layer using just a subset of the data (which is exactly what I did here). After reading this, I think I should switch to the new school way, which uses Hiroaki Yutani’s
gghighlightpackage. I can’t wait to try it out.Josef Fruehwald. “Why does Labov have such weird transcriptions?”
The title of this post is literally something I’ve asked myself. If I had really dug around for an answer, I probably could have found some of the early sources that explain it, but this blog post summarizes it all up nicely for you. One of the reasons is that the “transcriptional system is now encoding a phonological analysis.”
Timo Grossenbacher. “Categorical spatial interpolation with R”
I recently got a fair amount of spatial data and I’ve been meaning to learn how to visualize some of what I got. This post gives a complete tutorial for how to do k-nearest neighbor categorical interpolation using the
kkNNpackage. Because this involves some pretty complicated calculations, I also learned I could utilize the multiple cores I have on my computer for super intense stuff, which is always fun. I ended up creating this map, thanks to this tutorial: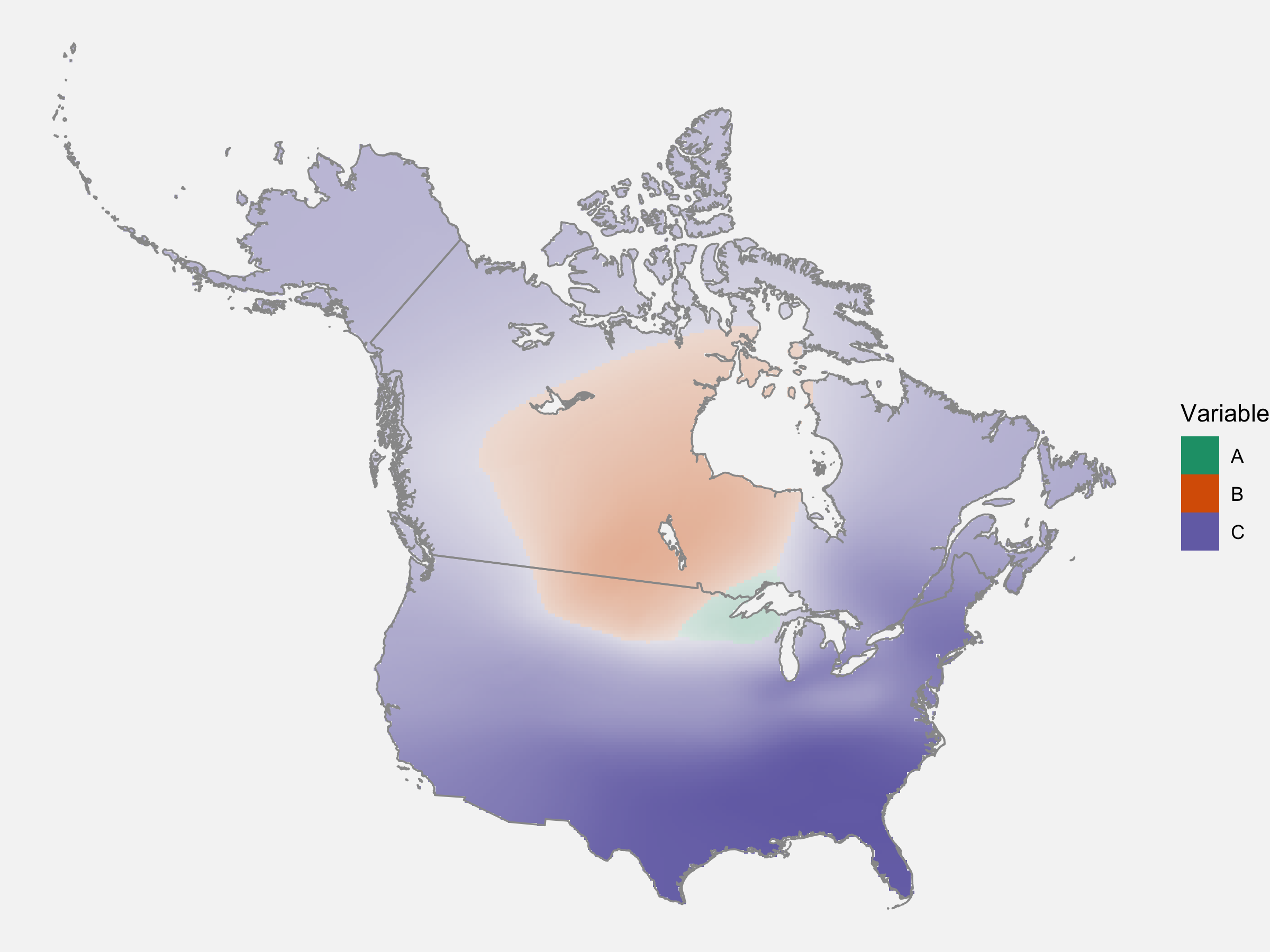
As far as what this map shows, well, no spoilers, but I’m waiting to hear back from ADS about whether I get to present on this data.
So that’s my jealousy list. Text analysis, regression, ggplot2, vowel transcriptions, and GIS. That’s actually a nice smattering of the things I read about the most.