library(dplyr)
library(ggplot2)
Note
This post was written in 2018 and used code that was up-to-date at the time. In November 2023, I updated the code to reflect changes in dplyr.
Last week I was approached by a fellow graduate student who asked how they might go about making vowel plots in R. I’ve made my share of these plots and have learned some tricks along the way, so I thought it might make for an interesting blog post. Actually, I thought it would make for an interesting series of blog posts. In this first one, I’ll stick with scatterplots and look at the code you’ll need for them. In the next one I show how to plot vowel trajectories.
For this workshop, we’ll need just two packages: dplyr and ggplot2. Let’s load those now.
Just FYI, there are actually some phonetic-specific packages that make it easier to do this (I’m thinking the vowels package by Tyler Kendall and Erik Thomas), but I like the flexibility of doing it from scratch in ggplot2.
Read in and process data
The dataset I’ll be working with comes from me reading 300 sentences while sitting at my kitchen table. This was transcribed manually and force-aligned using DARLA, with formants extracted using FAVE. You can access this dataset yourself with my joeysvowels package. I’ve removed a lot of the outliers already, so the remaining data that we’ll use here is relatively clean.
As with any R script, the first step (after loading your packages) is to read in and prepare your data. For maximal reproducibility in your own data, I’m going to work with the FAVE output as is, so you can see how I process the data. This means that we’ll be seeing the vowels in “ARPABET”, rather than IPA. Since the focus of this post isn’t necessarily on the minutia of the data processing, I’ll keep that part to a minimum.
my_vowels <- read.csv("http://joeystanley.com/data/joey.csv") %>%
filter(stress == 1,
!vowel %in% c("AY", "AW", "OY", "ER"),
!word %in% c("TO", "US", "ON")) %>%
mutate(word = tolower(word))So what this chunk does is it reads in file called joey.csv that I have saved in a folder called data. It then filters the data by keeping just the vowels with primary stress, removing diphthongs and /ɚ/, and removing a couple stopwords. Then it changes all the words so that they’re lowercase. Here’s what the dataset looks like
head(my_vowels)| name | sex | vowel | stress | pre_word | word | fol_word | F1 | F2 | F3 | F1_LobanovNormed_unscaled | F2_LobanovNormed_unscaled | B1 | B2 | B3 | t | beg | end | dur | plt_vclass | plt_manner | plt_place | plt_voice | plt_preseg | plt_folseq | pre_seg | fol_seg | context | vowel_index | pre_word_trans | word_trans | fol_word_trans | F1.20. | F2.20. | F1.35. | F2.35. | F1.50. | F2.50. | F1.65. | F2.65. | F1.80. | F2.80. | nFormants |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LA000-Joey | M | AA | 1 | WITHOUT | todd | EARLY | 662.8 | 1162.4 | 2596.3 | 1.1671501 | -1.0629811 | 287.2 | 419.8 | 221.4 | 12.917 | 12.86 | 13.03 | 0.17 | o | stop | apical | voiced | oral_apical | T | D | internal | 2 | W IH0 TH AW1 T | T AA1 D | ER1 L IY0 | 775.3 | 1336.7 | 740.5 | 1162.1 | 614.6 | 1065.2 | 637.6 | 1109.4 | 545.2 | 1314.1 | 6 | |
| LA000-Joey | M | AE | 1 | THE | last | TIME | 658.1 | 1389.0 | 2496.6 | 1.1377223 | -0.4825991 | 505.4 | 208.3 | 81.6 | 13.713 | 13.68 | 13.78 | 0.10 | ae | fricative | apical | voiceless | liquid | complex_coda | L | S | internal | 2 | DH IY0 | L AE1 S T | T AY1 M | 638.3 | 1513.1 | 642.6 | 1445.0 | 613.8 | 1005.4 | 645.1 | 1395.4 | 615.9 | 1237.3 | 6 |
| LA000-Joey | M | EY | 1 | ALL | places | THAT | 391.0 | 1664.2 | 2589.7 | -0.5346548 | 0.2222603 | 85.1 | 216.4 | 115.7 | 17.452 | 17.44 | 17.49 | 0.05 | ey | fricative | apical | voiceless | obstruent_liquid | one_fol_syll | L | S | internal | 3 | AO1 L | P L EY1 S IH0 Z | DH AH0 T | 391.0 | 1664.2 | 391.0 | 1664.2 | 363.4 | 1810.2 | 354.7 | 1944.9 | 354.7 | 1944.9 | 6 |
| LA000-Joey | M | EH | 1 | MY | guest | SIL | 501.3 | 1674.3 | 2416.1 | 0.1559599 | 0.2481291 | 84.9 | 92.5 | 442.6 | 19.830 | 19.81 | 19.87 | 0.06 | e | fricative | apical | voiceless | velar | complex_coda | G | S | internal | 2 | M AY1 | G EH1 S T | SIL | 468.4 | 1719.3 | 472.9 | 1711.9 | 533.0 | 1613.9 | 549.3 | 1549.6 | 548.4 | 1545.5 | 6 |
| LA000-Joey | M | IY | 1 | SP | sleeping | FREEZING | 254.8 | 2279.9 | 2658.2 | -1.3874357 | 1.7992296 | 82.9 | 110.1 | 124.1 | 24.073 | 24.03 | 24.16 | 0.13 | iy | stop | labial | voiceless | obstruent_liquid | one_fol_syll | L | P | internal | 3 | S L IY1 P IH0 NG | F R IY1 Z IH0 NG | 300.6 | 1595.5 | 261.7 | 2216.3 | 253.8 | 2335.6 | 260.8 | 2351.3 | 244.0 | 2229.0 | 5 | |
| LA000-Joey | M | EH | 1 | DOES | collectors | MONEY | 521.9 | 1342.8 | 2471.9 | 0.2849414 | -0.6009294 | 113.6 | 62.9 | 106.4 | 31.917 | 31.90 | 31.95 | 0.05 | e | stop | velar | voiceless | obstruent_liquid | complex_one_syl | L | K | internal | 3 | D IH0 Z | K L EH1 K T ER0 Z | M AH1 N IY0 | 512.0 | 1317.0 | 512.0 | 1317.0 | 530.2 | 1377.6 | 488.7 | 1436.6 | 488.7 | 1436.6 | 5 |
| LA000-Joey | M | EY | 1 | HAVE | snakes | AND | 472.7 | 1823.0 | 2584.5 | -0.0231116 | 0.6289888 | 341.8 | 197.7 | 183.4 | 34.419 | 34.39 | 34.48 | 0.09 | ey | stop | velar | voiceless | nasal_apical | complex_coda | N | K | internal | 3 | HH AE1 V | S N EY1 K S | AH0 N D | 372.5 | 1855.8 | 468.8 | 1828.8 | 408.6 | 1608.8 | 355.7 | 1510.0 | 314.5 | 1652.2 | 6 |
| LA000-Joey | M | IY | 1 | HE | feeds | WIRE | 261.5 | 2044.8 | 2771.1 | -1.3454854 | 1.1970768 | 58.3 | 75.0 | 154.6 | 41.217 | 41.17 | 41.31 | 0.14 | iy | stop | apical | voiced | oral_labial | complex_coda | F | D | internal | 2 | HH IY1 | F IY1 D Z | W AY1 R | 1387.6 | 2206.5 | 256.6 | 2035.2 | 252.6 | 1895.6 | 230.6 | 2086.2 | 236.1 | 1999.6 | 6 |
| LA000-Joey | M | IH | 1 | THE | trigger | SP | 351.0 | 1643.2 | 2198 | -0.7851044 | 0.1684738 | 62.5 | 87.6 | 207.6 | 43.740 | 43.72 | 43.78 | 0.06 | i | stop | velar | voiced | obstruent_liquid | one_fol_syll | R | G | internal | 3 | DH IY0 | T R IH1 G ER0 | 346.6 | 1602.3 | 347.5 | 1607.4 | 353.2 | 1689.6 | 340.0 | 1768.0 | 337.6 | 1777.7 | 5 | |
| LA000-Joey | M | IY | 1 | ON | speaking | AS | 302.9 | 1948.8 | 2459.5 | -1.0862700 | 0.9511956 | 63.8 | 124.2 | 92.2 | 50.653 | 50.63 | 50.70 | 0.07 | iy | stop | velar | voiceless | oral_labial | one_fol_syll | P | K | internal | 3 | AO1 N | S P IY1 K IH0 NG | EH1 Z | 274.2 | 1791.6 | 293.1 | 1856.2 | 284.1 | 1898.8 | 273.7 | 2009.4 | 263.3 | 2190.1 | 6 |
Building a basic scatterplot
The way things work in ggplot2 is we be build a visualization layer by layer. The base layer can be created by just using the ggplot() function.
ggplot()
It’s just a blank, gray rectangle, but it is valid code. To make this actually useful, we can tell it to work with the my_vowels data.
ggplot(my_vowels)
Okay still no visualization, but we’re on our way. The next part of a ggplot function is what’s called the mapping argument. This is where you tell ggplot which columns of your data should correspond to what parts of the visualization. Traditionally in vowel plots, we want F2 along the x-axis and F1 along the y-axis. We can do that using the aes() function and specify that we want to work with the columns called F1 and F2 from our spreadsheet.
ggplot(my_vowels, aes(x = F2, y = F1))
We’re getting closer. What ggplot has done at this point is added some information to your plot already. There are now x- and y-axis labels, ticks, and a grid with major and minor lines. All we need to do is populate this with some data.
Tangent: Column names
Side note. In FAVE output, there are several column names with formant data. The F1 and F2 columns have measurements at slightly different points depending on the vowel. If you want to plot the midpoints specifically, you’ll have to use different column names. If you open the file in Excel, the column names are F1@50% and F2@50%. However, R doesn’t really like having the @ or % in the column names, so if you read it in using read.csv like I did, those characters will be changed to periods, meaning the column names are actually F1.50. and F2.50.. So if you want to use midpoints, be sure to do use those columns instead:
See Labov, Rosenfelder, & Fruehwald’s 2013 article in Language for details on these columns.
ggplot(my_vowels, aes(x = F2.50., y = F1.50.))
Side-side note. If you read your data in using read_csv (with an underscore) from the readr package (which is part of the “tidyverse”), it actually handles the real name of the column. However, you’ll have to put little ticks (that apostrophe-looking thing next to your “1” key) around them:
my_vowels_readr <- readr::read_csv("http://joeystanley.com/data/joey.csv")
ggplot(my_vowels_readr, aes(x = `F2@50%`, y = `F1@50%`))
We’ll stick with the basic F1 and F2 columns, but I thought you might find it handy to know what the different columns in your FAVE output mean.
Anyway, back to the scatterplot
All we need to do at this point is to add the scatterplot. We can do that by adding a separate layer to the ggplot function. To do this, just add a plus sign (+) at the end of the line, start a new line, and add the function geom_point, which is the function for making a scatterplot in ggplot2.
ggplot(my_vowels, aes(x = F2, y = F1)) +
geom_point()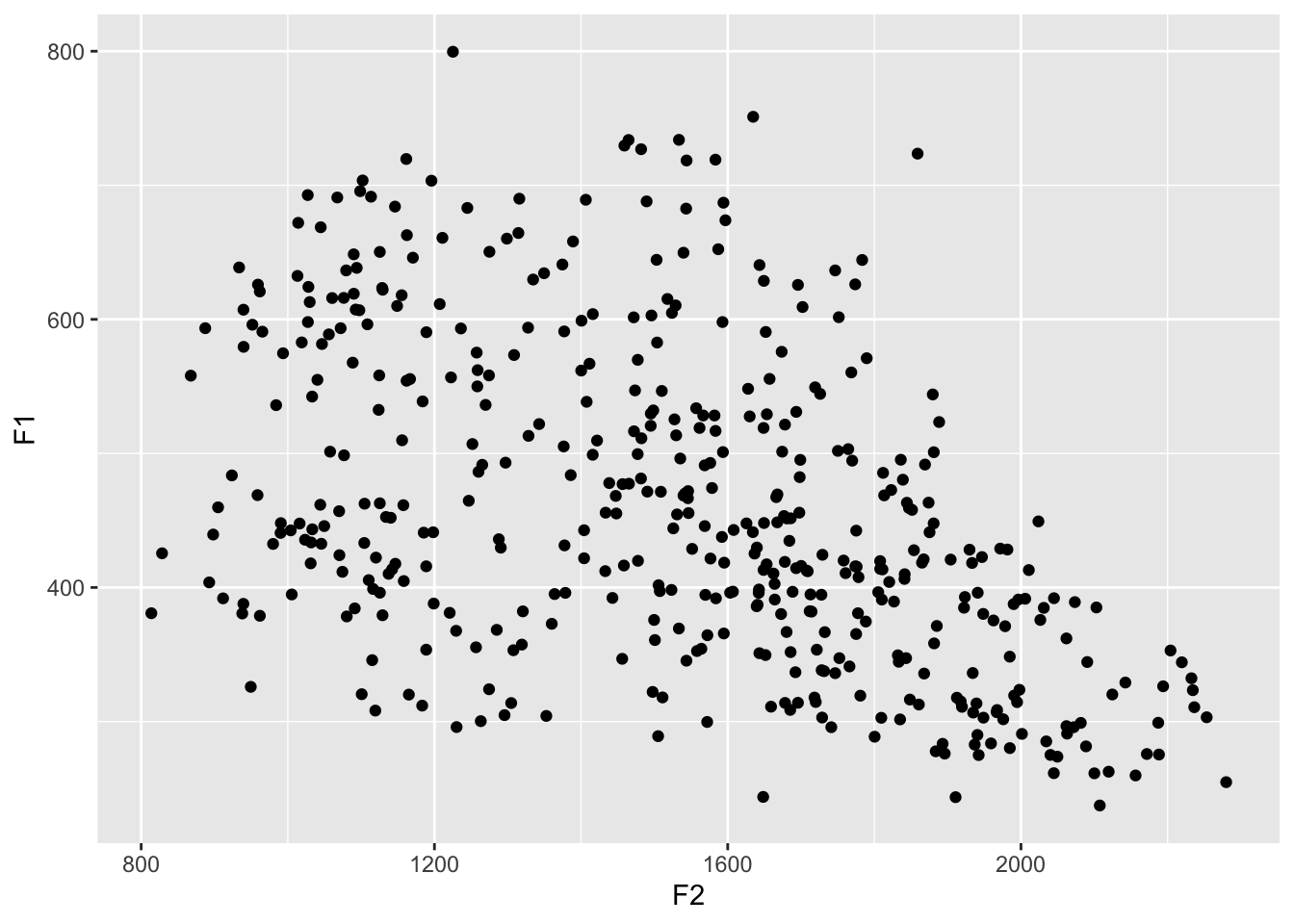
Aha! We now have a scatterplot! It’s not the most useful one because we can’t tell what vowel or word each point came from. But it is a start.
Themes
Right now, you might be wondering why we have a gray background. This is on purpose by the designers of ggplot2 because it makes colors pop out. You can change the overall look and feel of your plot using various theme functions. I like theme_bw(), theme_classic(), and theme_minimal() myself, so I’ll stick with theme_classic() for today.
You can explore the other themes by typing the command
?theme_classic and looking at the other options.ggplot(my_vowels, aes(x = F2, y = F1)) +
geom_point() +
theme_classic()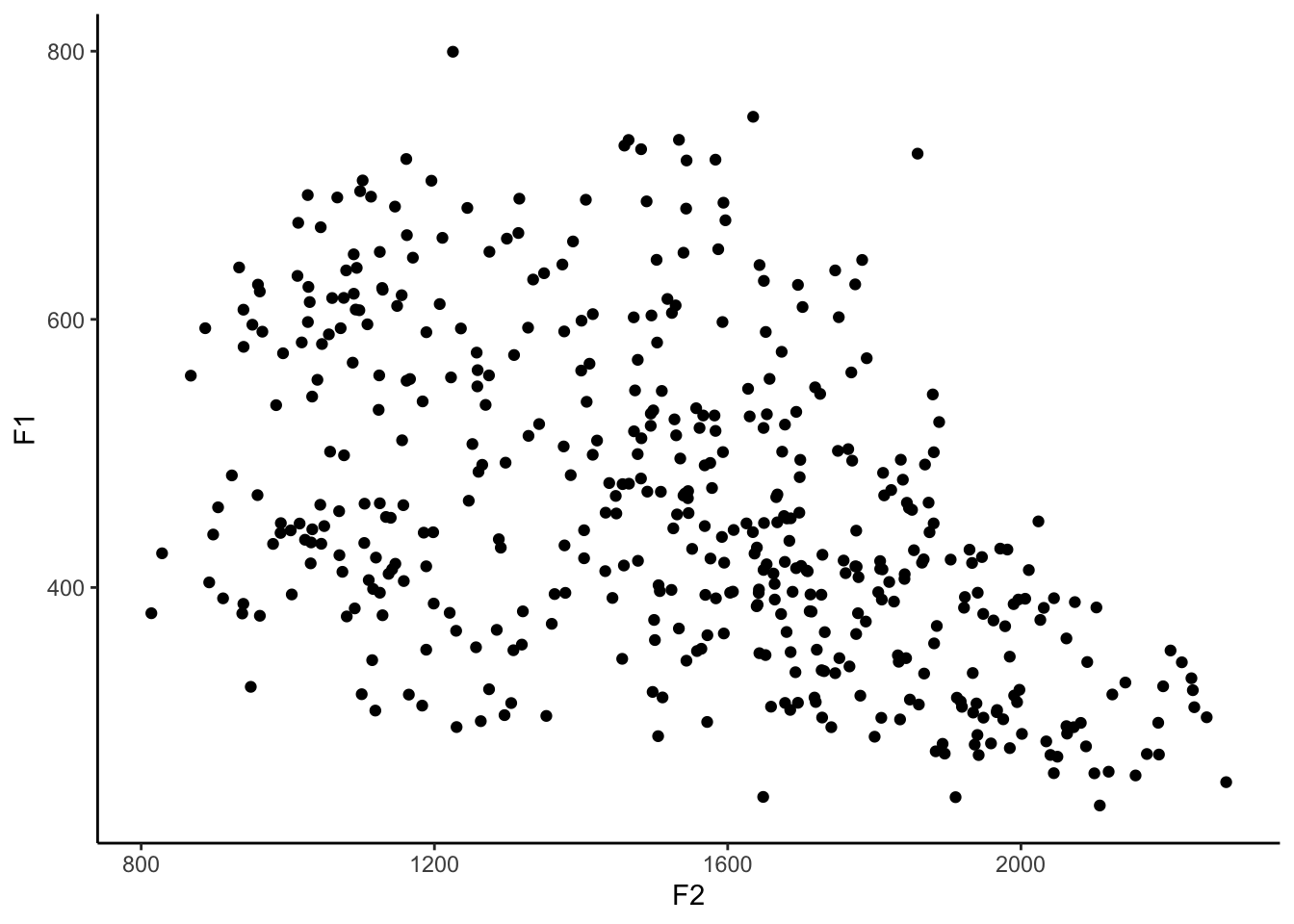
Coloring vowels
Because English has so many vowels, there’s no really good way to show them all on a plot. Typically, I use color, but it’s hard to get a set of 11 colors that are all easily distinguishable and easy on the eyes. There’s no real way to win here. For now, let’s just add the default colors and see how it looks.
So how do we add color? If you think about it, what we want ggplot to do is to change the color of the dot depending on what the vowel is. Since the vowel is stored in a column called vowel in our spreadsheet, in a practical sense we want to tell ggplot to simply change the color of the dot so that each value in the vowel column has its own color.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel)) +
geom_point() +
theme_classic()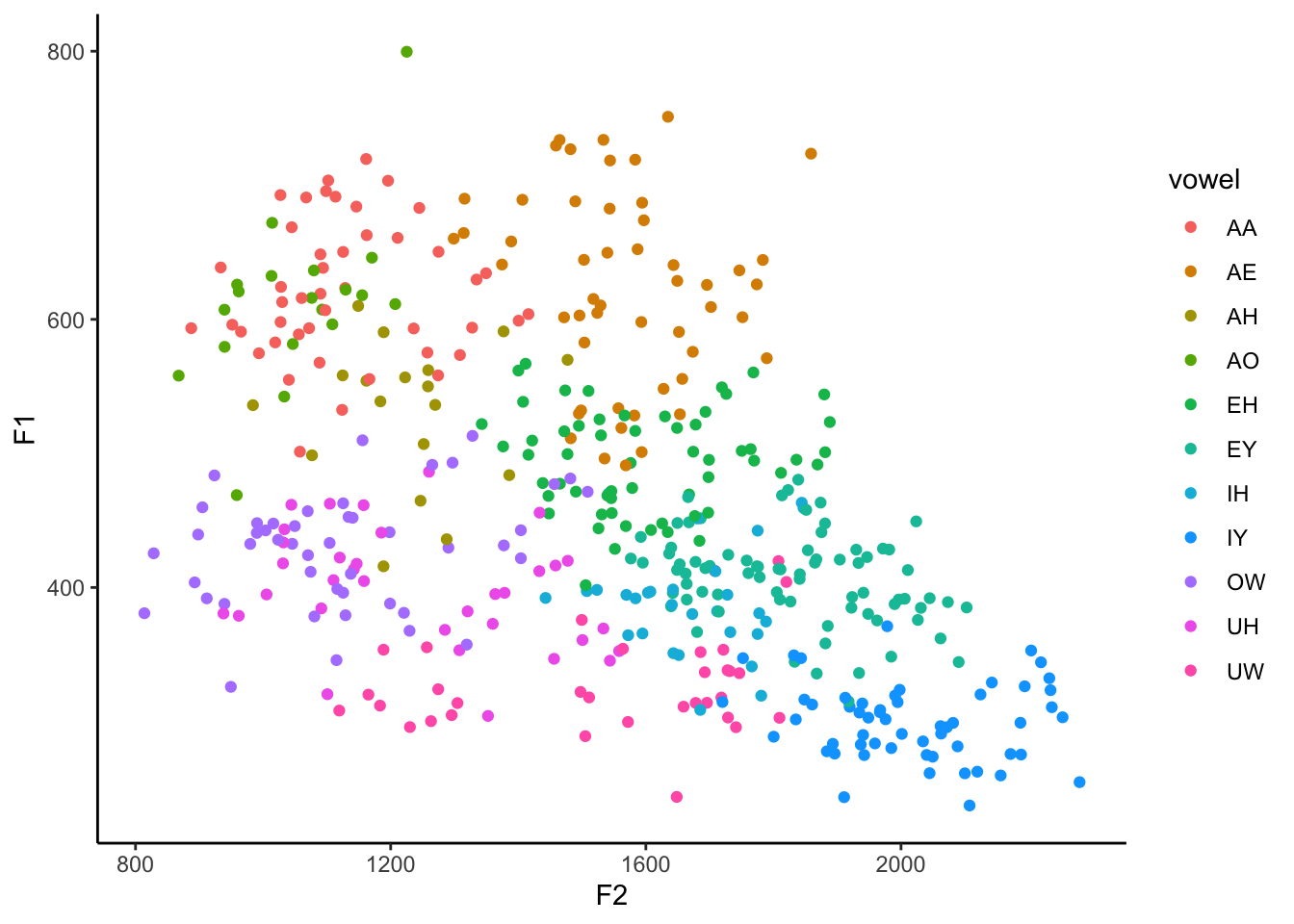
Okay, so let’s look at the result. The most obvious thing we see is that there is now color, but there’s also a legend too. Each unique vowel in our data is now represented in this legend, and the name of the column in our spreadsheet, vowel, is the title of that legend. One subtler change is that the plotting area is actually a little bit narrower to make room for the legend.
How is this color assigned? First, it puts all the vowels in alphabetical order. But keep in mind that this is based on the ARPABET notation, which might not be the order you want. In IPA, it ends up being /ɑ, æ, ʌ, ɔ, ɛ, e, ɪ, i, o, ʊ, u/. It then takes that order and, going around the color wheel from red to pink, picks 11 equidistant, maximally-distinct colors. Because of the nature of how color works, there are several shades of blue and green, but not very many warm colors. We’ll see how to fix the order of these colors, as well as the specific color values, in just a sec.
Tangent: reversing the axes
Now wait a second. The high front vowel /i/—represented by the digraph “IY”—is in the bottom right of the plot when it traditionally is in the top left. Vowel plots typically reverse both the x- and the y-axes so that high vowels are at the top, and front vowels are on the right. This is just convention but it has to do with the inverse relationship with the actual formant values and our perception of sounds. Anyway, the functions you’re looking for are scale_x_reverse() and scale_y_reverse(), which should each be added as their own layer. (Unlike most other layers, I typically put these on one line.)
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel)) +
geom_point() +
scale_x_reverse() +
scale_y_reverse() +
theme_classic()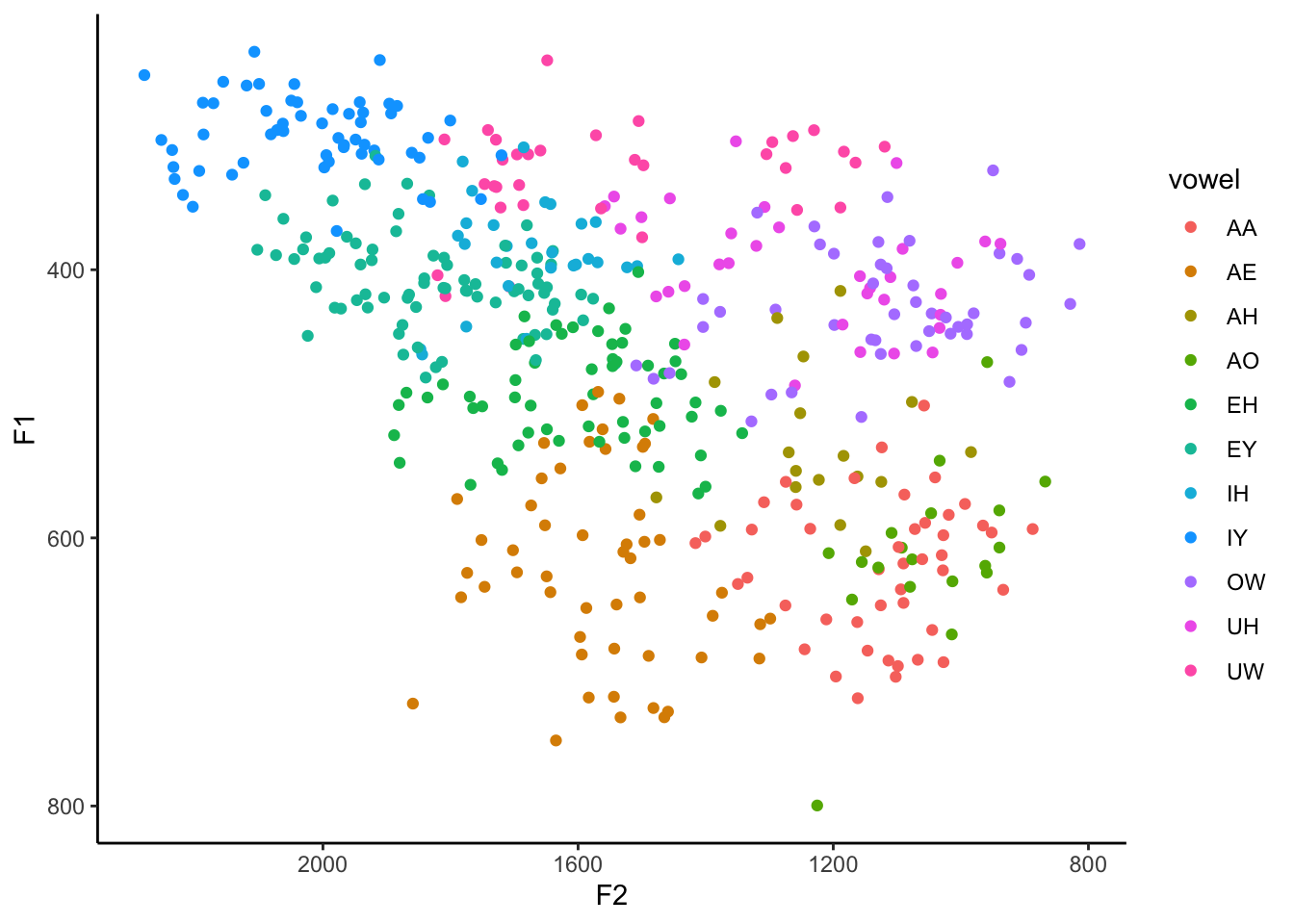
Okay, much better. Now we can see that the bright blue IY vowel is in the top left, the pink UW is in the top right-ish, and my unmerged AA and AO (/ɑ/ and /ɔ/, as in cot and caught) are in the bottom right.
Changing the order
If you want to change the order of the colors and the order in the legend, there are two ways to do that. The first is by leaving your underlying data alone and making superficial changes only within ggplot itself. This is a useful thing to know how to do, but I won’t cover that here. If you’re interested, I’d highly recommend this page on that, or you can peruse one of the ggplot2 workshops I did.
At least for the order of the vowels, what I think is the most useful option is to actually modify your dataset and then plot the modified version. The way to do this to overwrite the vowel column in our my_vowels dataset, and, using the factor function, manually specifying the order you want them to be in. The actual data itself doesn’t change, but what we’re doing is modifying how R treats this column under the hood. This is the order that I typically do, but you’re of course free to do whatever you want.
my_vowels <- my_vowels %>%
mutate(vowel = factor(vowel,
levels = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")))
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel)) +
geom_point() +
scale_x_reverse() +
scale_y_reverse() +
theme_classic()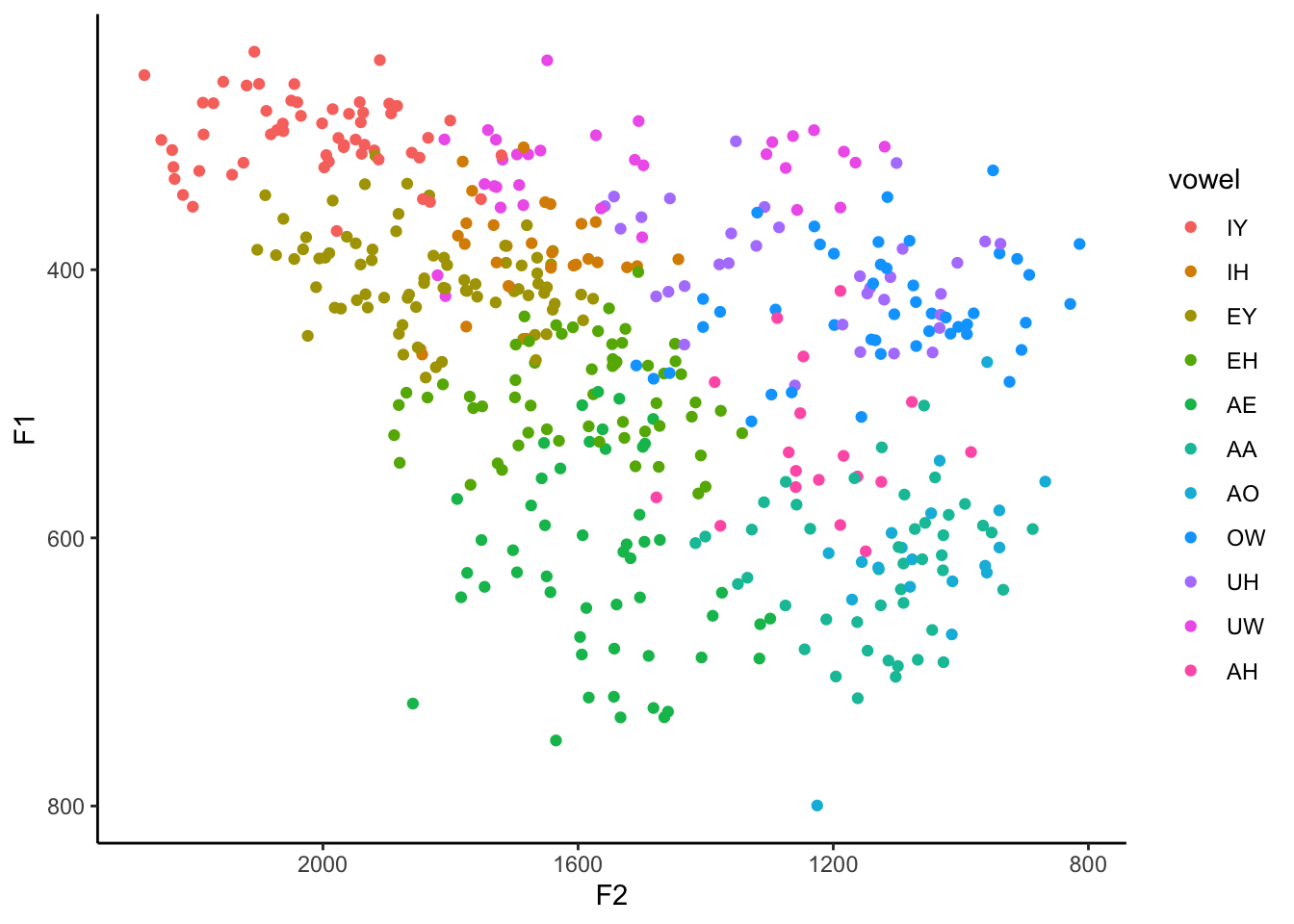
The benefit to this is that now the vowels are in a somewhat logical order in the legend. The downside is that the colors of each vowel are very close to other vowels near them in the vowel space. What would be better is to have vowels near each other to be different visually.
Just for funsies, I tried a different order essentially by just choosing every third vowel.
my_vowels <- my_vowels %>%
mutate(vowel = factor(vowel,
levels = c("IY", "EH", "AO", "UH", "IH",
"AE", "AH", "UW", "EY", "AA", "OW")))
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel)) +
geom_point() +
scale_x_reverse() +
scale_y_reverse() +
theme_classic()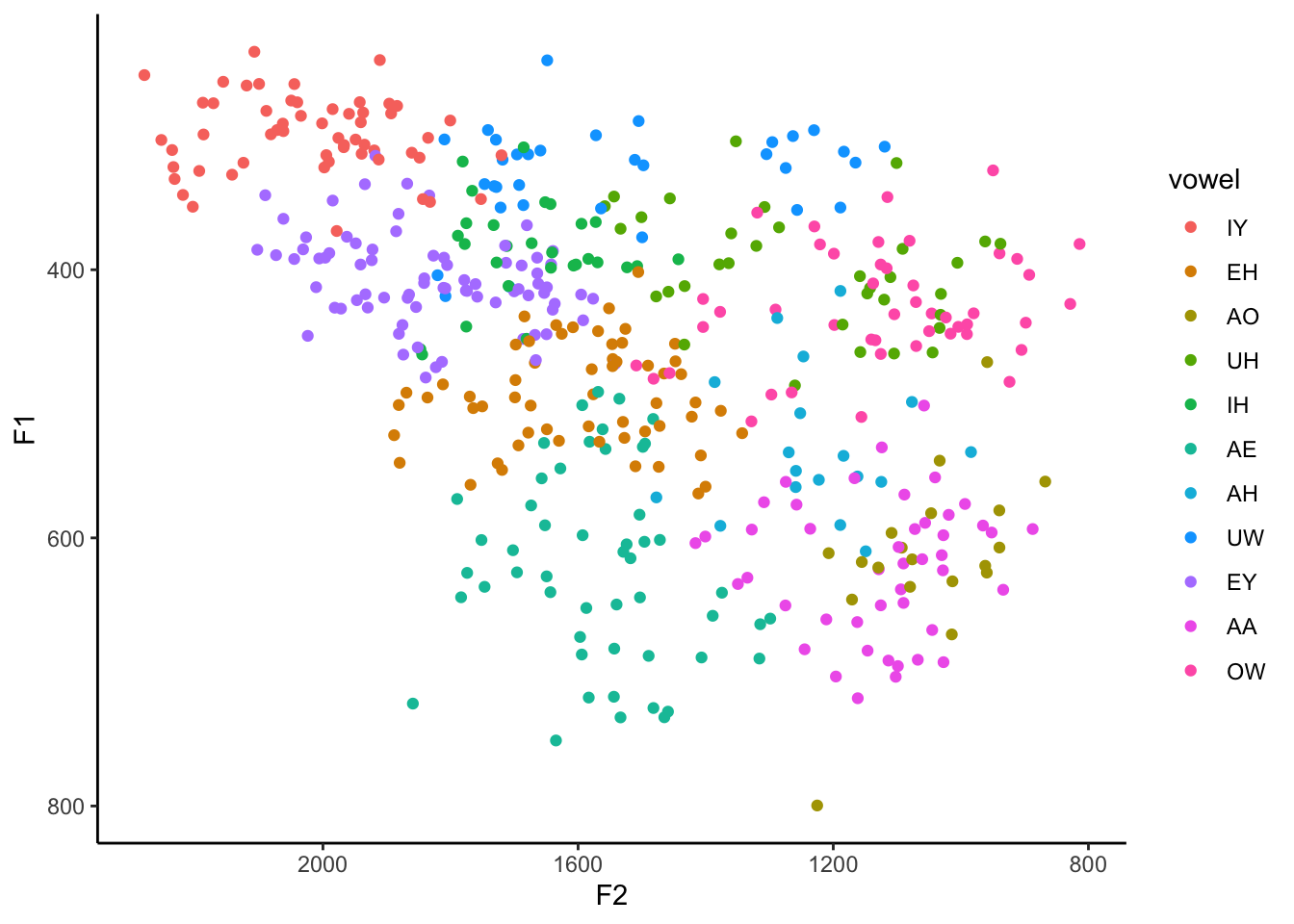
This is the first time I’ve done this and I kinda like it. I’ll stick with it. The good part is that the vowels are for the most part relatively easy to distinguish from their neighbors. The major downside is that the legend is the exact order I specified, which is useless for finding something. What we need to do is actually modify the legend order. We can do that with the scale_color_discrete function added to our growing stack of ggplot code and then supply the order you want it to be in as the breaks argument.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel)) +
geom_point() +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
theme_classic()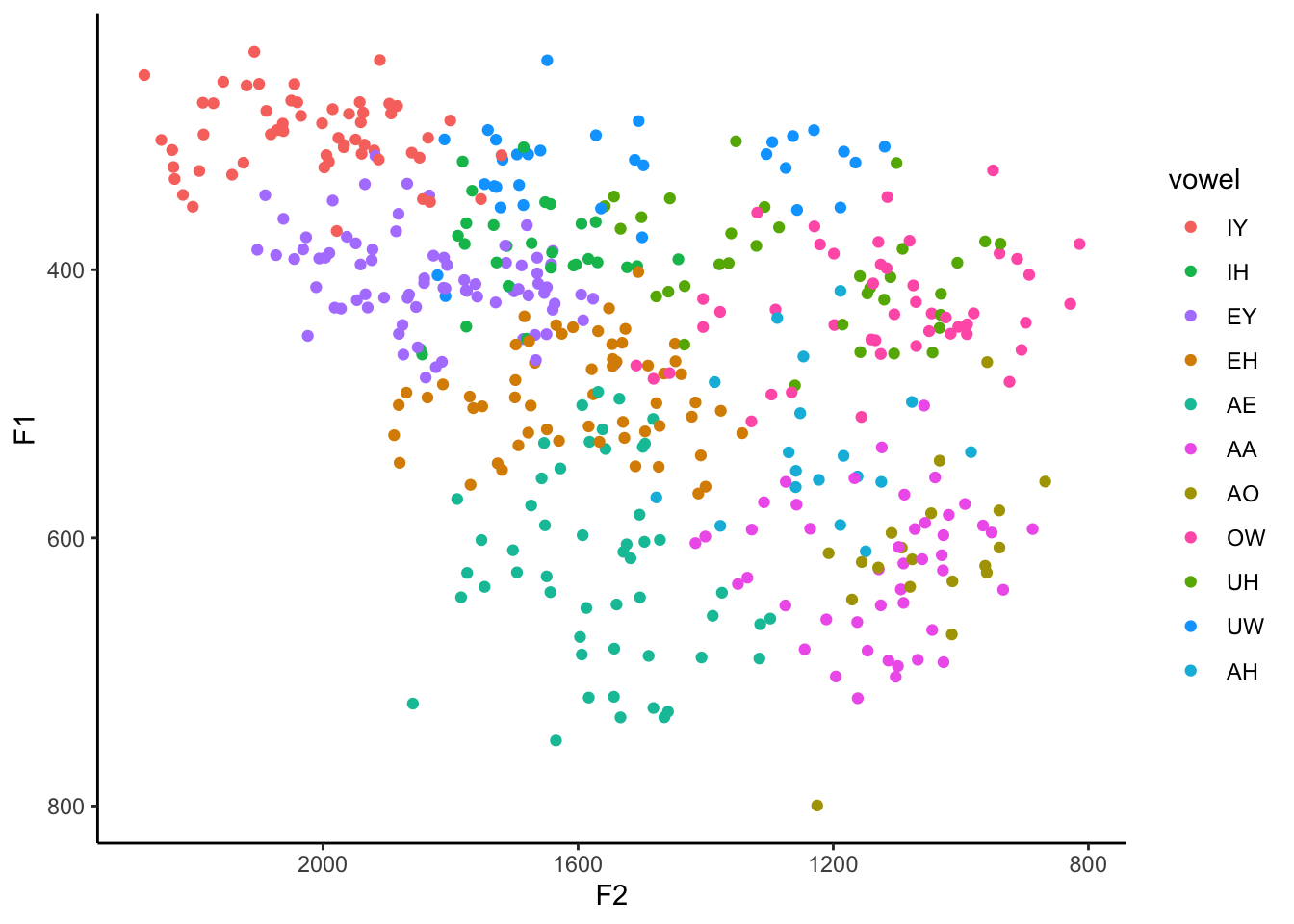
Great. Now the colors are distinct from one another and the order of the legend is back to an order we might expect.
Adding vowel means
The problem with the plot the way it is, is you still have to constantly check back and forth between the legend and the plot to see what vowel you’re looking at. An easier solution would be to plot the name of the vowel itself inside of its cluster.
One solution that I think I’ve seen before is to use the stat_summary function. Supposedly this works, and if you know how to use it, by all means go for it. I’ve never gotten it to work and I found a workaround that I like that I think offers more flexibility anyway. It involves creating a separate dataset and essentially overlaying a second scatterplot over the main one.
To create this, I pull out some black magic from the dplyr package. First, I start with the my_vowels dataset. I then “pipe” it (the %>% function) to the summarise function. This function makes it easy to get summary statistics from your data. We’re creating a new, arbitrarily-named column called mean_F1, which is calculated as the mean of the values in the F1 column. Same thing for mean_F2. However, as it is, we’ll end up with two numbers: the average F1 and F2 of all your data, which would probably be somewhere near the middle of your vowel space.
means <- my_vowels %>%
summarise(mean_F1 = mean(F1),
mean_F2 = mean(F2)) %>%
print() mean_F1 mean_F2
1 457.5832 1528.889What we actually want is the mean F1 and F2 per vowel. So, what we do is insert the group_by function just before summarise. By itself, group_by doesn’t really do much except change some stuff about the dataframe under the hood. But these changes are especially useful when that is then “piped” (%>%) to summarise. Because I did group_by(vowel) first, whatever summary information you want from your dataset will apply to each vowel independently. So, instead of the average overall, you’re getting the average per group. The result is a new dataframe that we’re calling means, that has all the information we want. (I’m then piping it to a print function so we can see the output.)
means <- my_vowels %>%
group_by(vowel) %>%
summarise(mean_F1 = mean(F1),
mean_F2 = mean(F2))
# Here's a shortcut using more modern code
means <- my_vowels %>%
summarise(mean_F1 = mean(F1),
mean_F2 = mean(F2),
.by = vowel)
print(means) vowel mean_F1 mean_F2
1 AA 621.6889 1130.740
2 AE 622.7078 1565.124
3 EY 407.6831 1827.070
4 EH 494.6517 1598.229
5 IY 299.7768 2018.850
6 IH 386.6250 1673.486
7 UH 399.4735 1246.662
8 AO 612.7316 1051.511
9 UW 328.4848 1537.948
10 AH 531.0722 1227.483
11 OW 428.7913 1124.385This new dataset, means, is a perfectly good, stand-alone dataset that we can plot by itself. Note that because we called the columns mean_F1 and mean_F2, we’ll have to use those in the ggplot2 function.
ggplot(means, aes(x = mean_F2, y = mean_F1)) +
geom_point() +
theme_classic()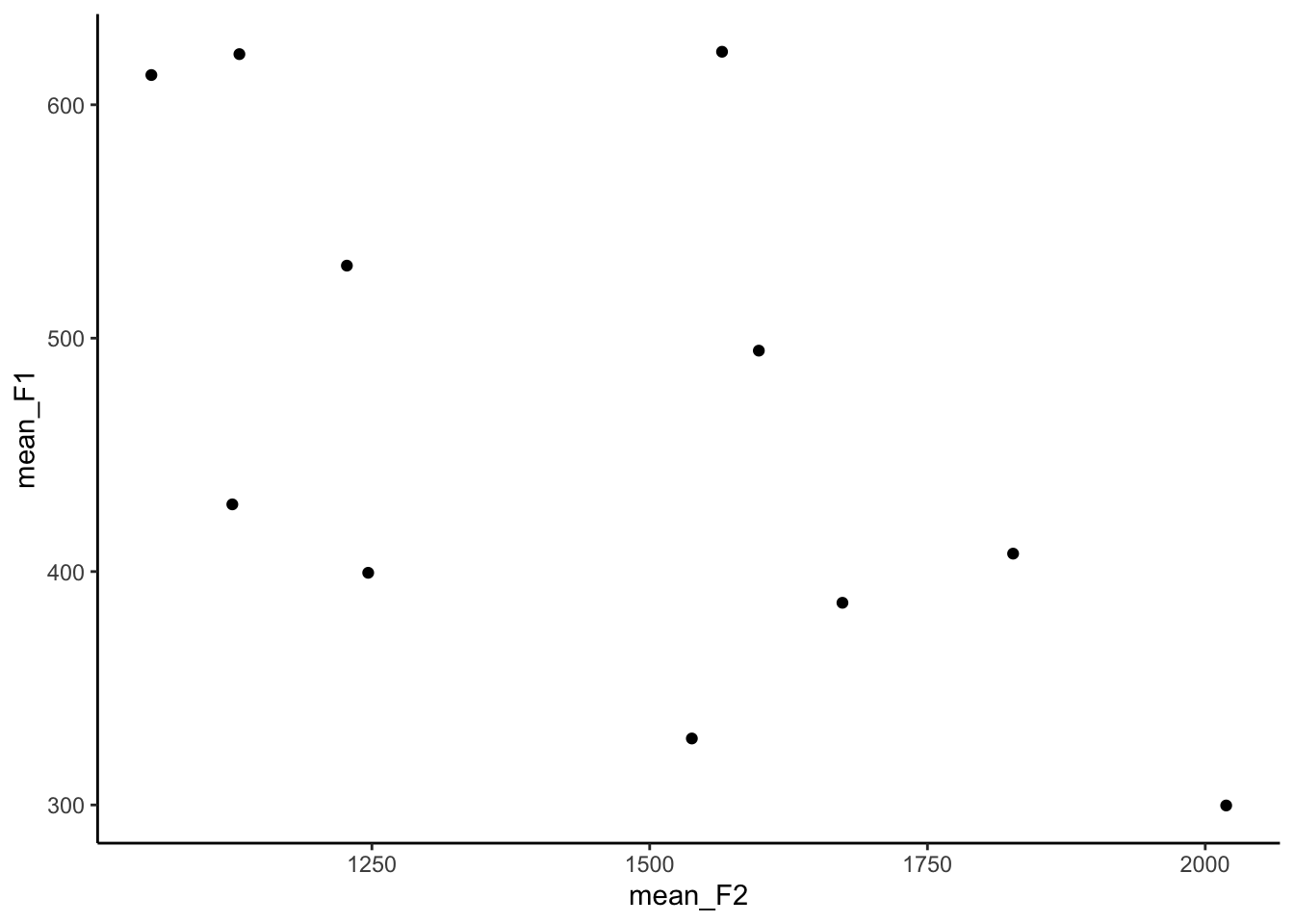
The points themselves aren’t very enlightening. To add some pizzazz, I’m going to use geom_label. This is essentially the same thing at geom_point because it makes a scatterplot, but instead of dots it’ll print these nice little labels. Of course, you have to tell ggplot what text to use for these labels, so we’ll tell it to use the text in the vowel column in the means dataset.
ggplot(means, aes(x = mean_F2, y = mean_F1, label = vowel)) +
geom_label() +
theme_classic()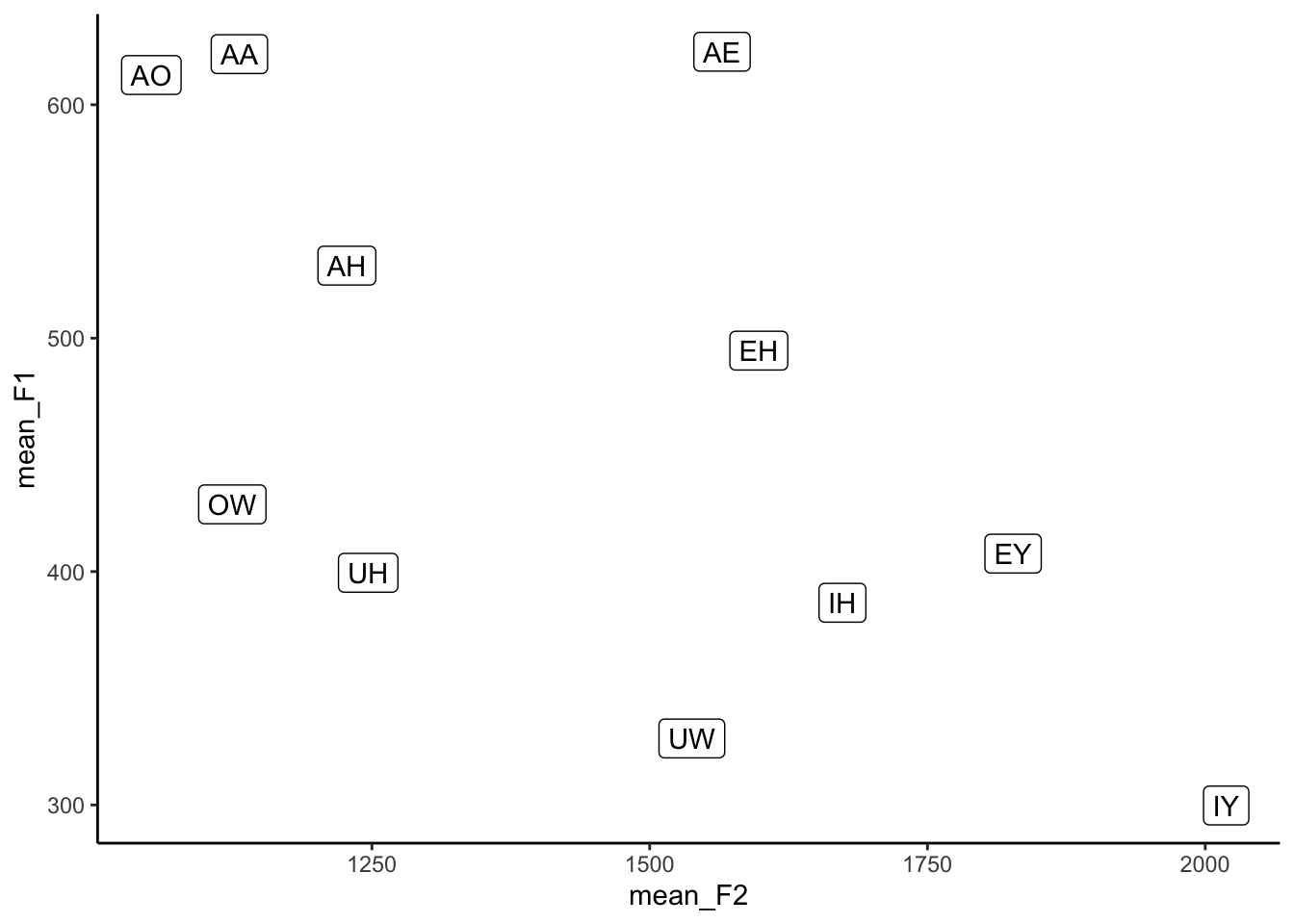
Ooh! Okay, so now we’re getting somewhere. Here it becomes obvious that we need to reverse the x- and y-axes. Let’s do that too.
ggplot(means, aes(x = mean_F2, y = mean_F1, label = vowel)) +
geom_label() +
scale_x_reverse() +
scale_y_reverse() +
theme_classic()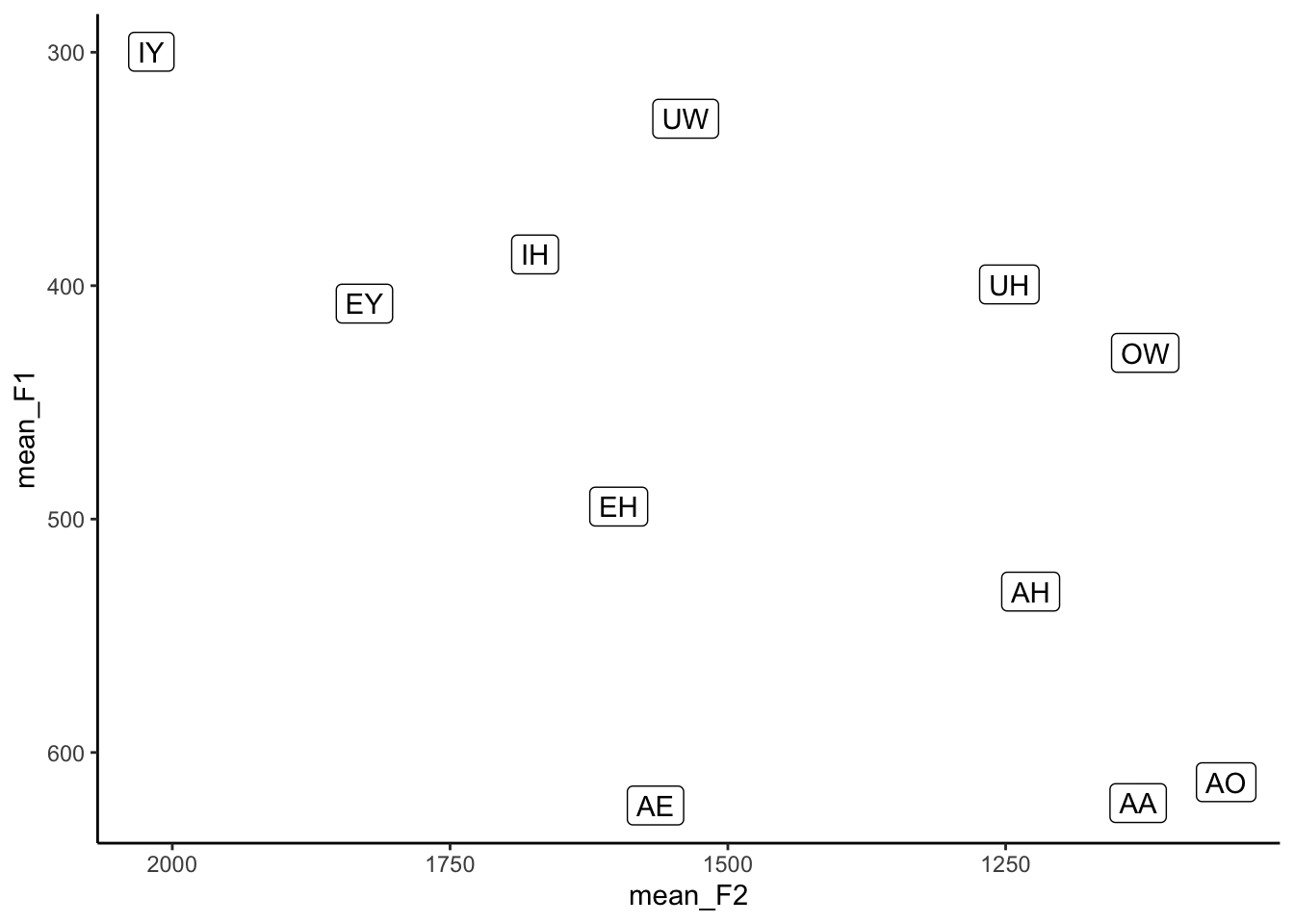
Perfect. So we’ve seen how to plot the points themselves, and now we’ve seen how to plot the means. Now comes the fun part of actually overlaying them into one plot.
It’s perfectly possible to plot two (or more) different datasets in a single visualization, but you’ll have to be careful about the aes() functions. Anything in the ggplot(aes()) function will apply to all other layers, unless they’re overridden. That’s why we didn’t need to provide any additional information in geom_point because it inherited all its information (the data, the axes, the color) from ggplot.
If we want to add the means, we’re using a different dataset, so that right off that bat has to be overridden in our geom_label function:
# Don't plot this yet...
...
geom_label(data = means) +
...Because we’re using geom_label, we’re going to need to put label = vowel somewhere. You can put it in the main ggplot(aes()) function with everything else and that’ll work out fine:
# Don't plot this yet...
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
...
geom_label(data = means) +
...However, we’re going to have to supply our own aes() function within geom_label. The reason for that is because right now we’ve got x = F2 and y = F1 as global settings. Our new means dataframe doesn’t have columns with those names. So we’ll have to override these by adding a second aes() function, this time within geom_label:
# Still don't run this.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
...
geom_label(data = means, aes(x = mean_F2, y = mean_F1)) + Add all the other pieces to the plot, and let’er rip.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
geom_label(data = means, aes(x = mean_F2, y = mean_F1)) +
scale_x_reverse() + scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
theme_classic()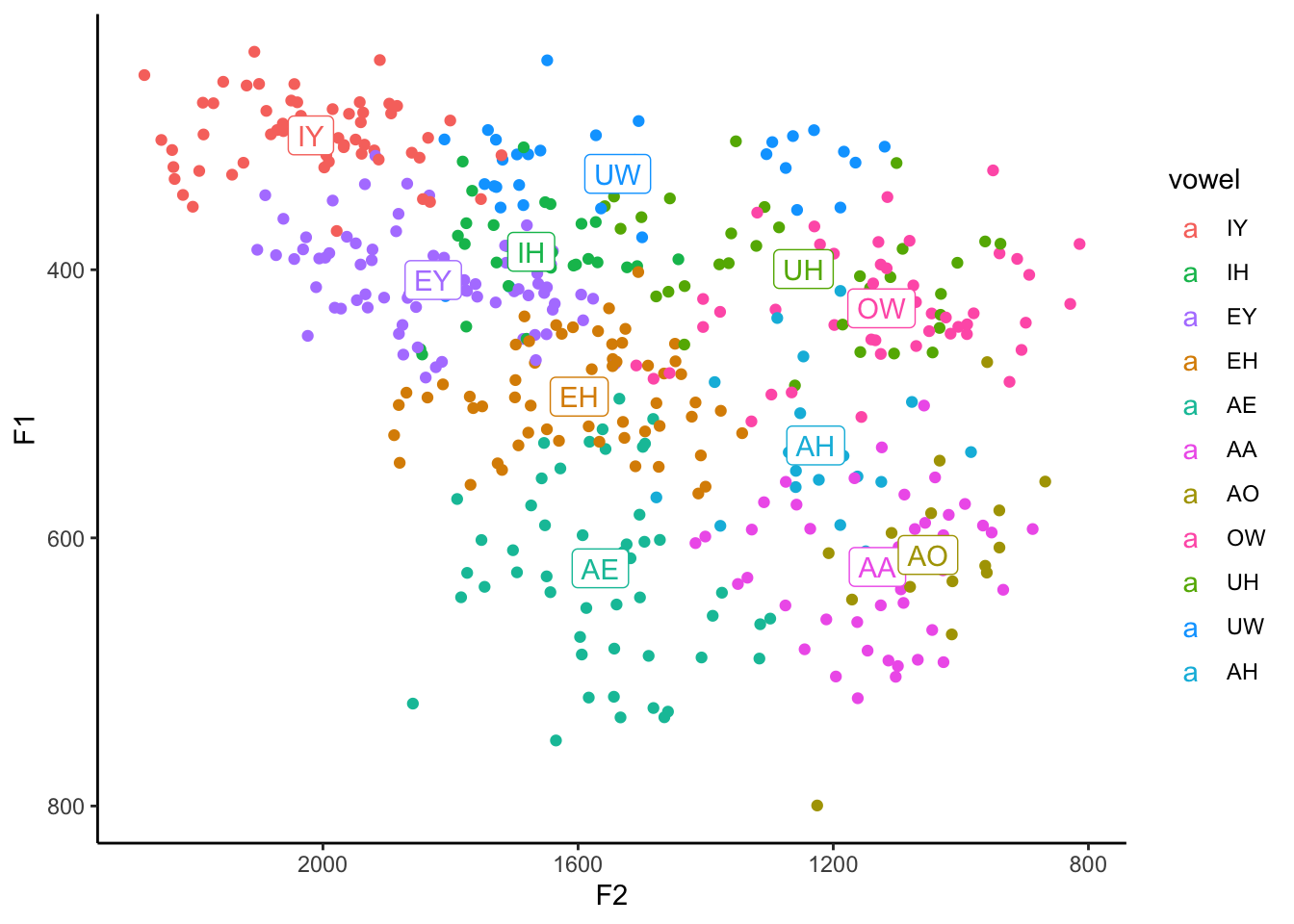
Aha! So now we have a vowel plot that has the points, and on top of them it has the labels for these vowels right where the averages are. Pretty cool.
A couple things to note here. In the legend, notice that the dots have now all turned into little a’s. This is because we’re using geom_label now. You can change them back to dots if you’d like by adding show.legend = FALSE to the geom_label() function. A better solution though is to actually remove the legend entirely because now it’s not providing any additional clarity. We can do that with guides(color = FALSE).
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
geom_label(data = means, aes(x = mean_F2, y = mean_F1)) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.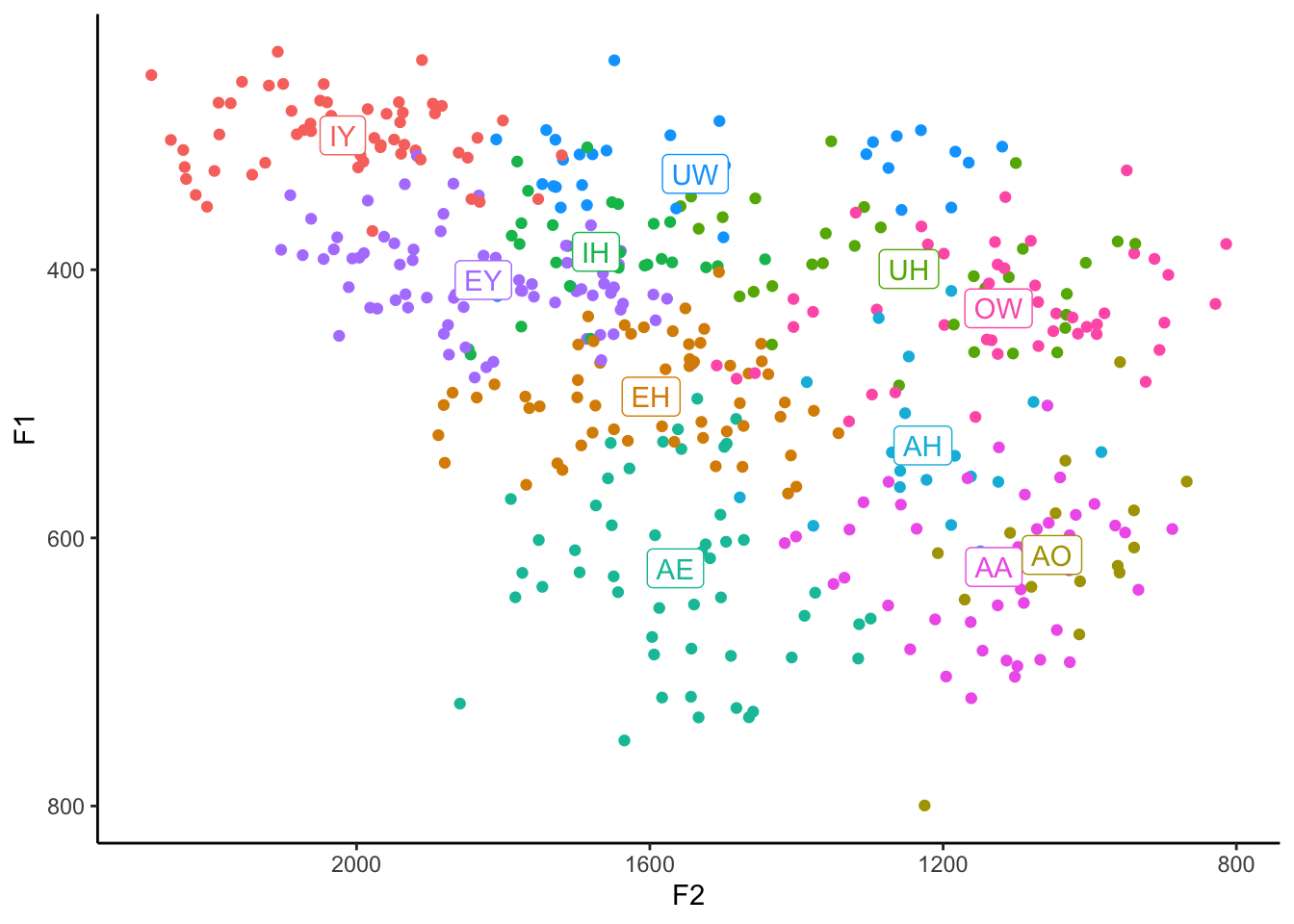
Another thing to notice is that the labels are automatically colored the same as the vowels! How did it do that? We’ll, as it turns out, geom_label inherited the color = vowel argument from the main ggplot(aes()) function. It worked because it just so happens that the column vowel exists in both the means and the my_vowels datasets. Pretty cool. If you want to override it, perhaps by making them all black, you can certainly do so. Just put it within geom_label but not inside of aes:
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
geom_label(data = means, aes(x = mean_F2, y = mean_F1), color = "black") +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()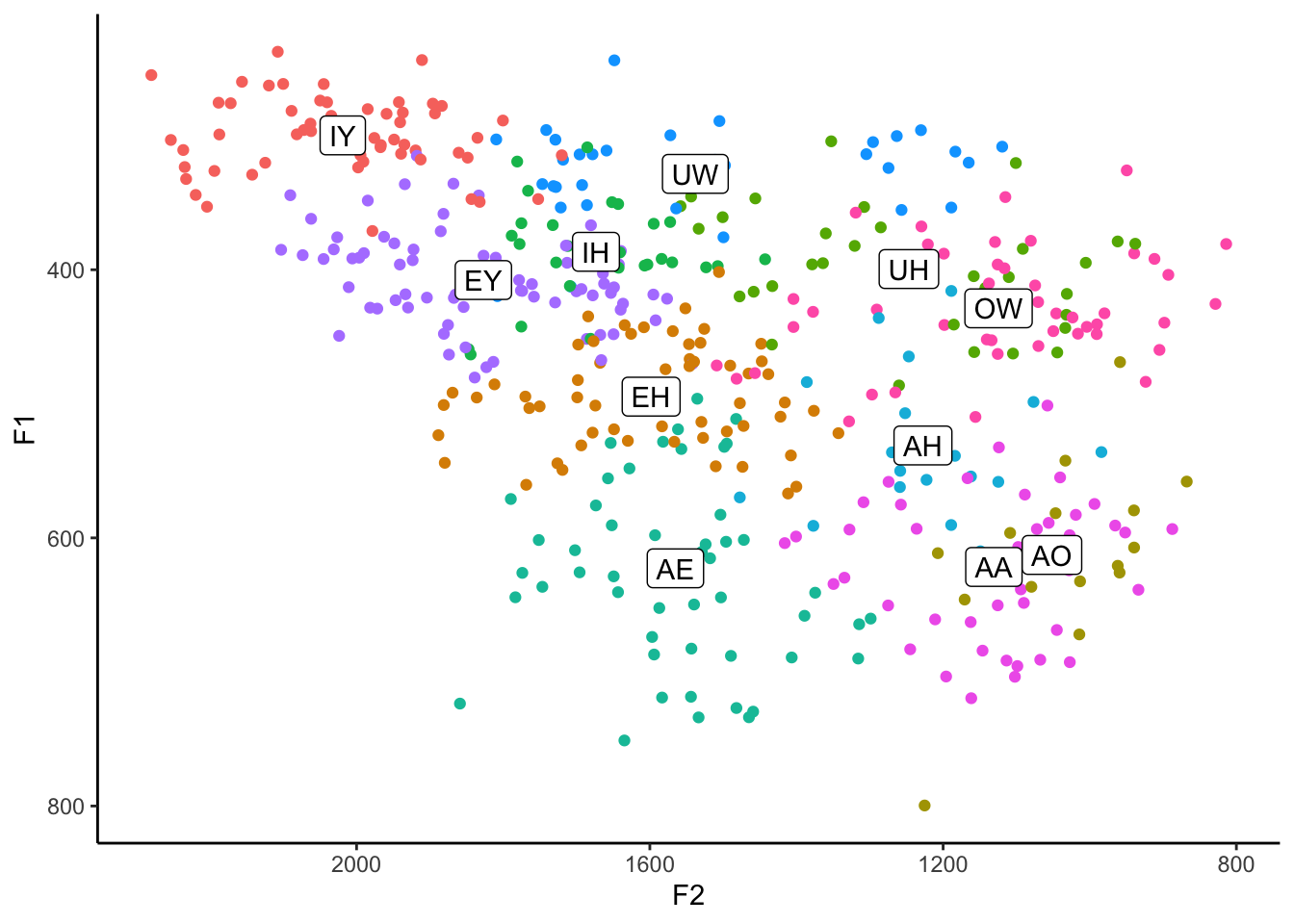
If course, now it’s not quite as clear which cluster the labels belong to. It’s up to you.
Tangent: An alternative approach
Side note, we could have saved ourselves some headache by planning ahead. When we created the means dataframe, we could have called the new columns F1 and F2 to match the columns in my_vowels. By doing that, we wouldn’t need to override the x and y arguments. All of that code would look like this.
means <- my_vowels %>%
group_by(vowel) %>%
summarise(F1 = mean(F1),
F2 = mean(F2))
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()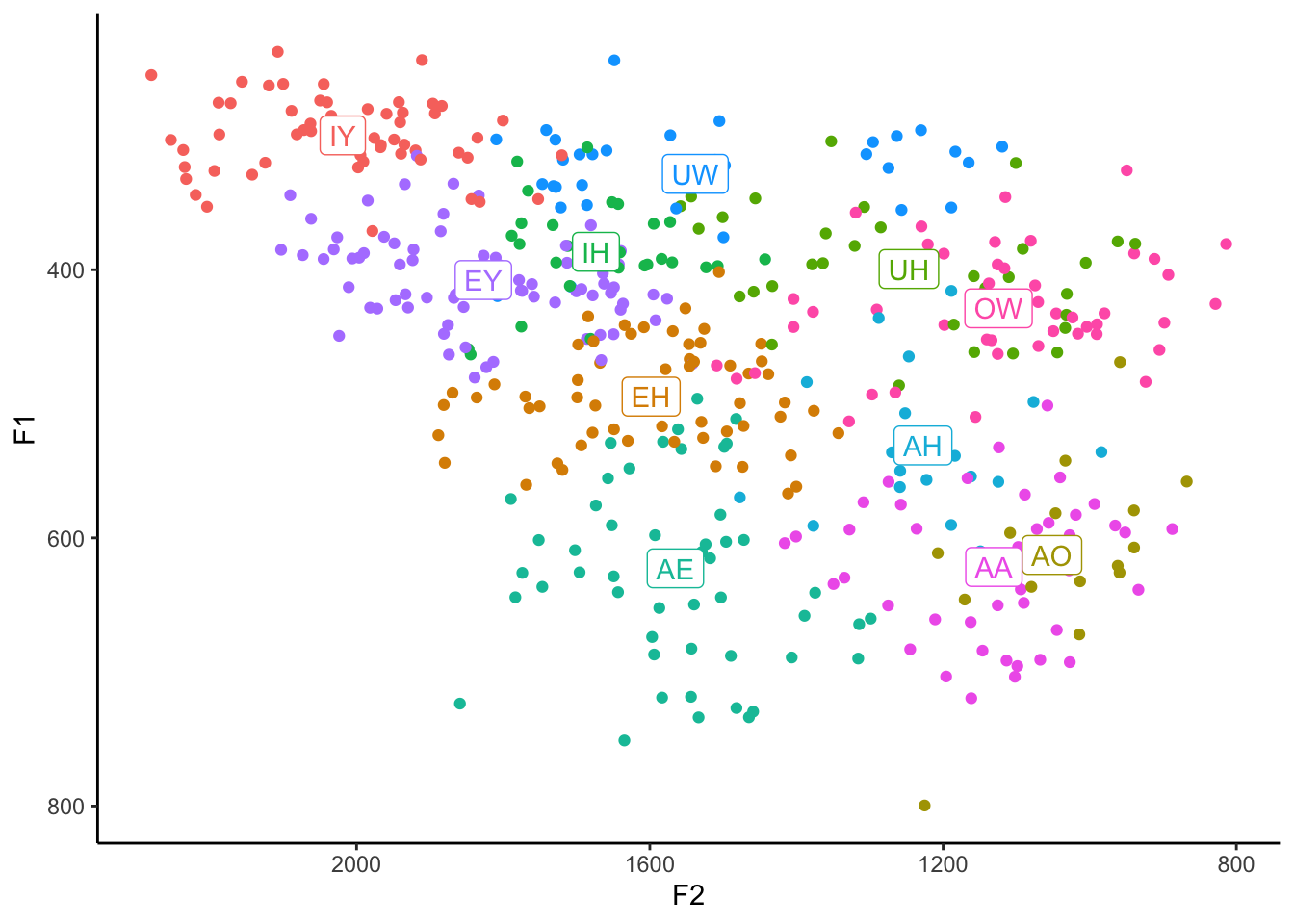
I’ll use this version of the means dataset moving forward since it’s closer to what I do in my actual code and because it makes everything a little easier.
Ellipses
One final thing that would be good to show in a vowel plot are ellipses. These are often used to get an idea of the distribution of the vowels or to show degree of overlap. Fortunately, they’re pretty easy to implement (a lot easier than means at least). The main function that takes care of these is stat_ellipse.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
geom_label(data = means, color = "black") +
stat_ellipse() +
scale_x_reverse() + scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()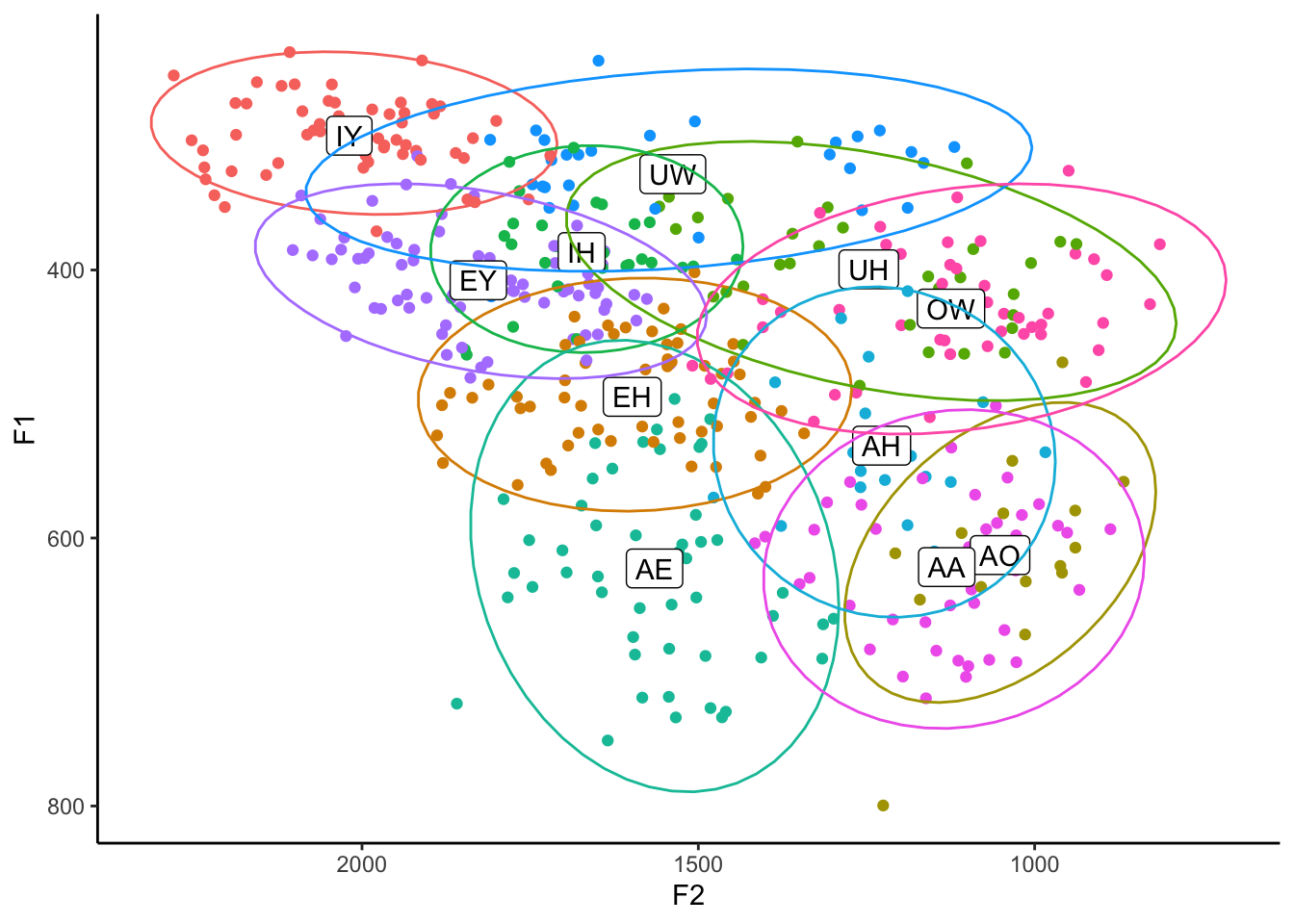
Easy-peasy. By default, these ellipses cover about a 95% confidence interval (or approximately two standard deviations) around the means of each vowel. We can change that to whatever we want using the level function. I usually set mine to 0.67, which corresponds to about one standard deviation. This only changes the size of the ellipses, leaving shape/orientation the same.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
geom_label(data = means, color = "black") +
stat_ellipse(level = 0.67) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()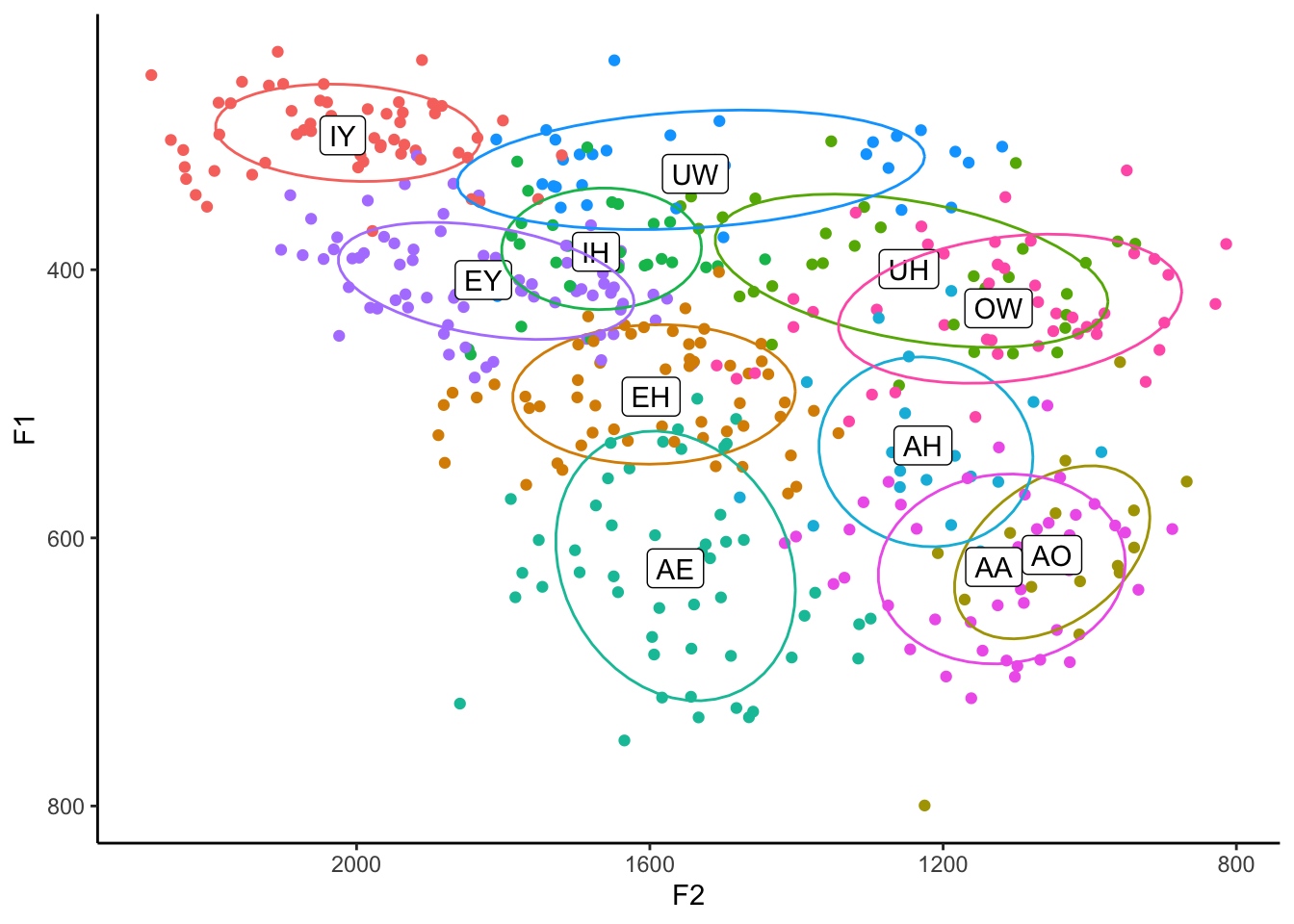
Tangent: Ordering
You might be wondering why I order the layers in the block of code the way I do. For the most part, the order doesn’t matter, but for some things it does. So if you look carefully at the above plot, you’ll see that the ellipses lines actually cover the labels. The reason for that is simply because the stat_ellipse function came after geom_label. I think it looks better with the labels on top, so you can switch those.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point() +
stat_ellipse(level = 0.67) +
geom_label(data = means, color = "black") +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()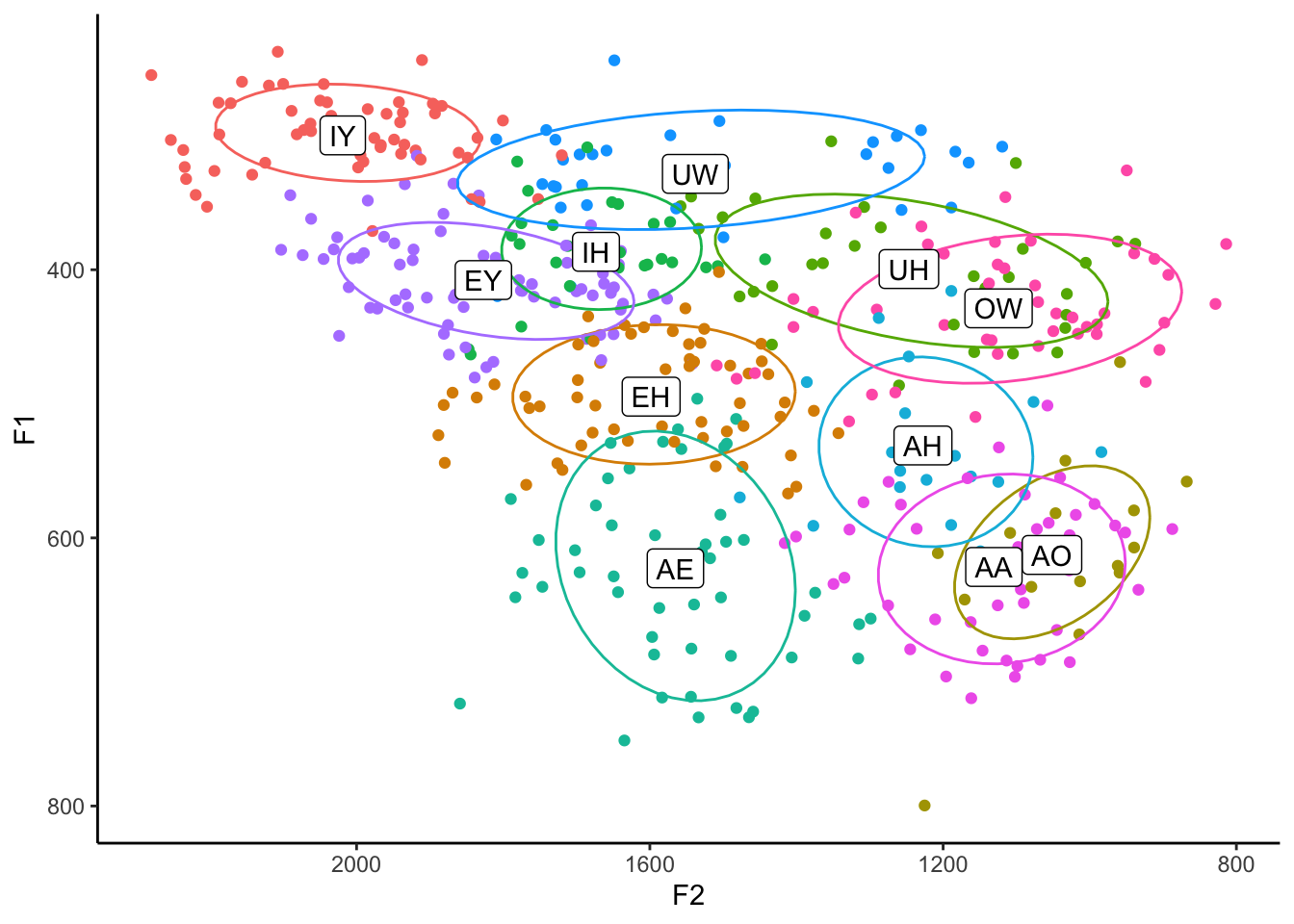
As far as I can tell, many of the other things like scale_x_reverse, scale_y_reverse, and scale_color_discrete can go anywhere. Generally, I order my block with the important things first (like geom_point since this is a scatterplot after all), then the small cosmetic changes (like scale_x_reverse), and then any themes.
Making the ellipses the focus
Sometimes, you just have too much data and you lose the forest for the trees with all those points. You can easy remove them and leave just the means and the ellipses by removing (or just commenting out) the geom_point line.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
#geom_point() +
stat_ellipse(level = 0.67) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()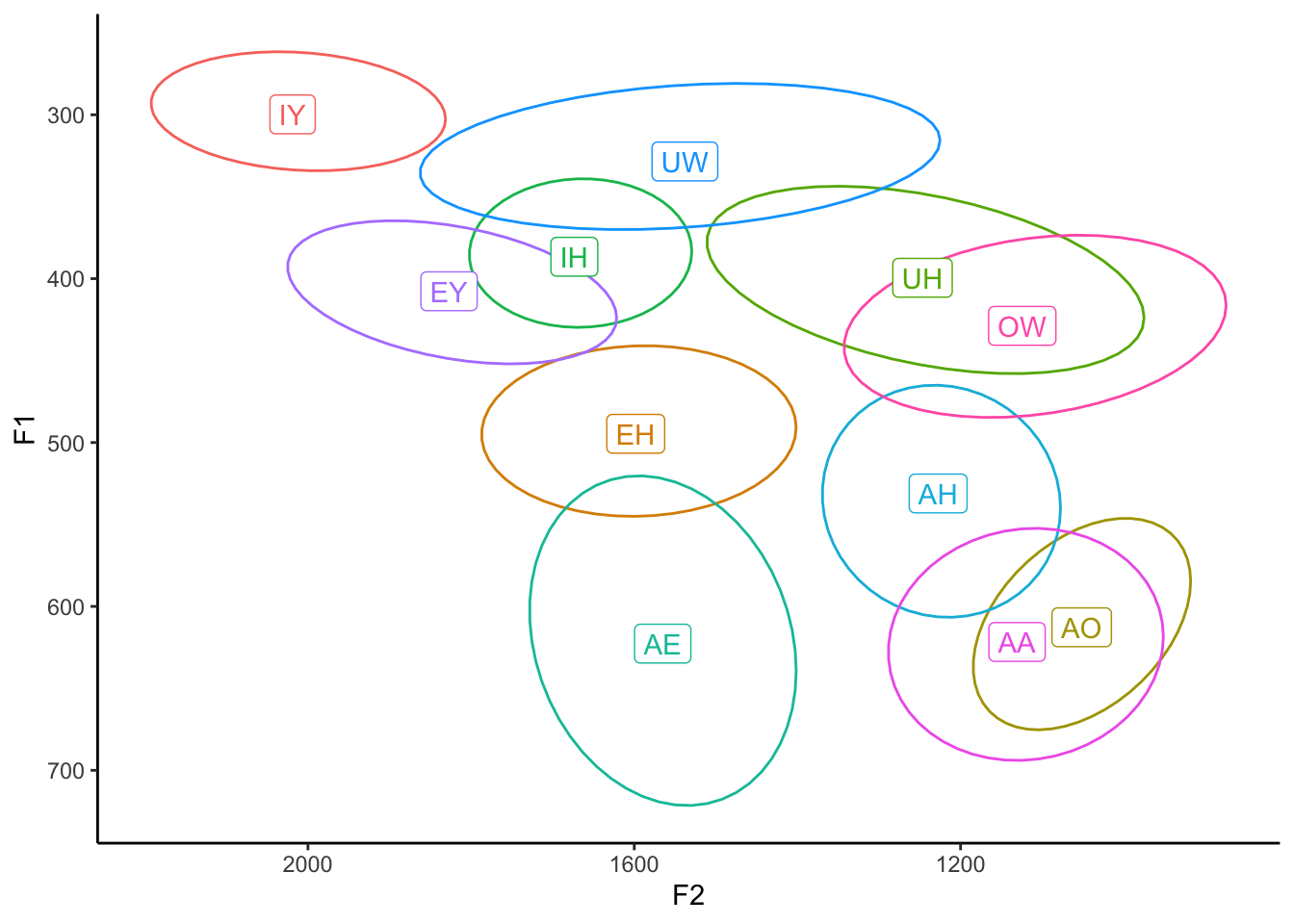
That’s one way to clean it up. We could also keep them but make them a bit transparent by adding the alpha argument. The range of values for alpha is from 0 to 1, with 1 being completely opaque and 0 being invisible. An alpha level of 0.2 means that it takes 5 (0.2 = 1/5) overlapping points to become completely opaque. In other words it’s only shaded in 20%.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point(alpha = 0.2) +
stat_ellipse(level = 0.67) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()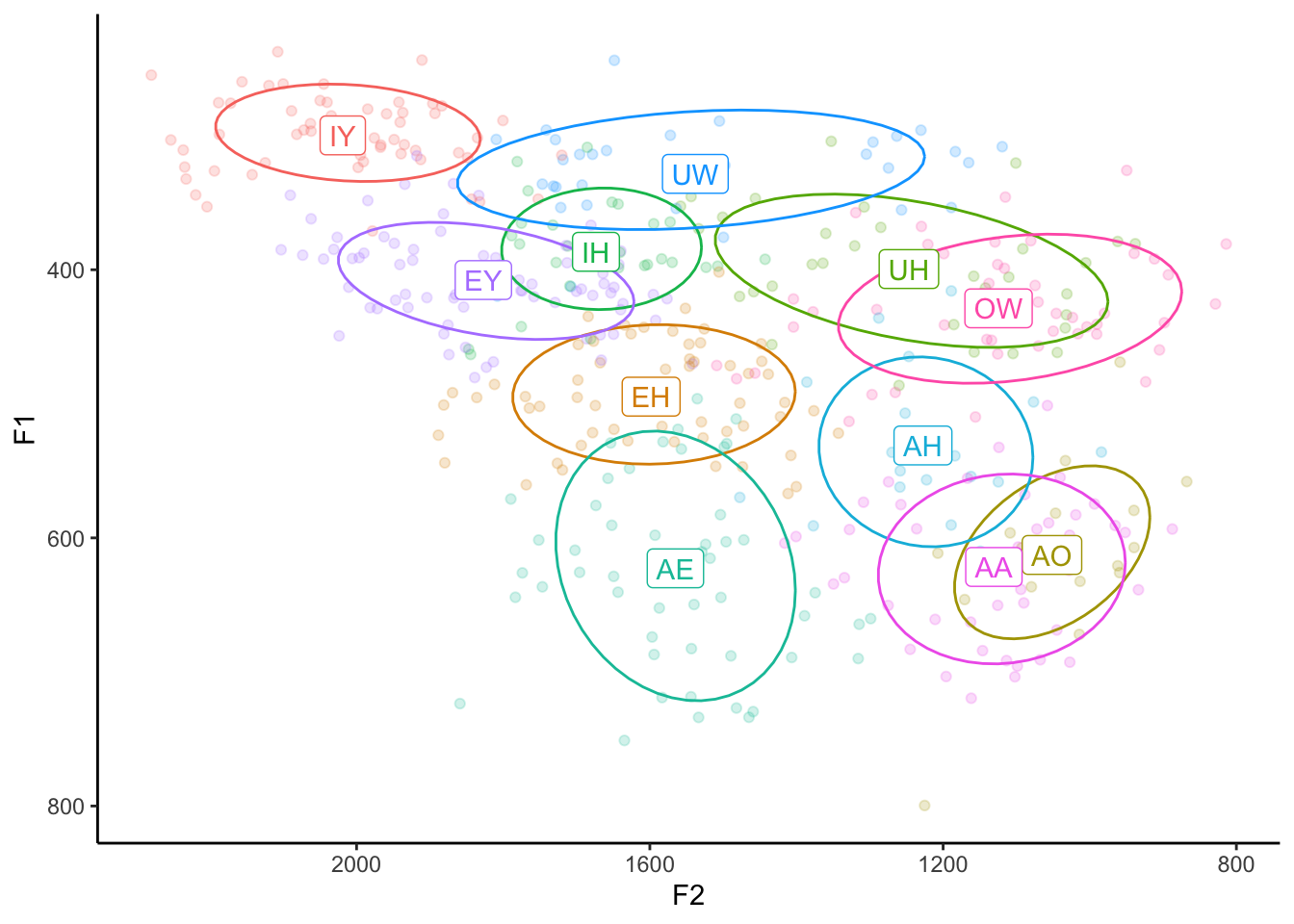
We could also change the size so that they’re smaller. I’ve found that the exact size depends on how much data you’re displaying, but if you make it smaller than the default of 1.5, you might have a slightly cleaner plot. I’ll make mine about half the default size by adding size = 0.75 within geom_point.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point(size = 0.75) +
stat_ellipse(level = 0.67) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()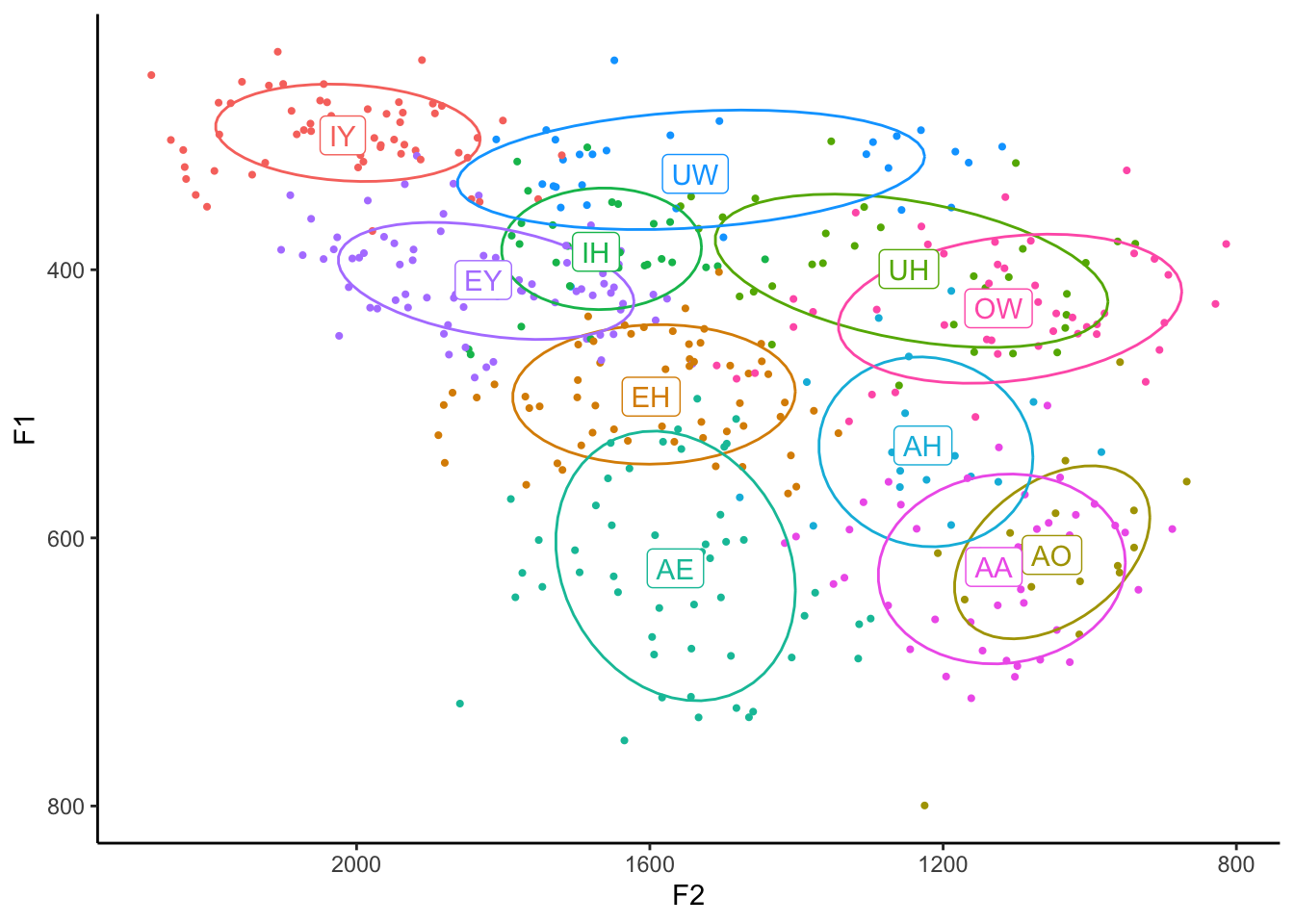
You could even change the size to a lot smaller, like 0.1 or even 0.01. You could also keep them relatively large but change the transparency as well (size = 2, alpha = 0.5). The sky’s the limit!
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
geom_point(size = 1, alpha = 0.5) +
stat_ellipse(level = 0.67) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()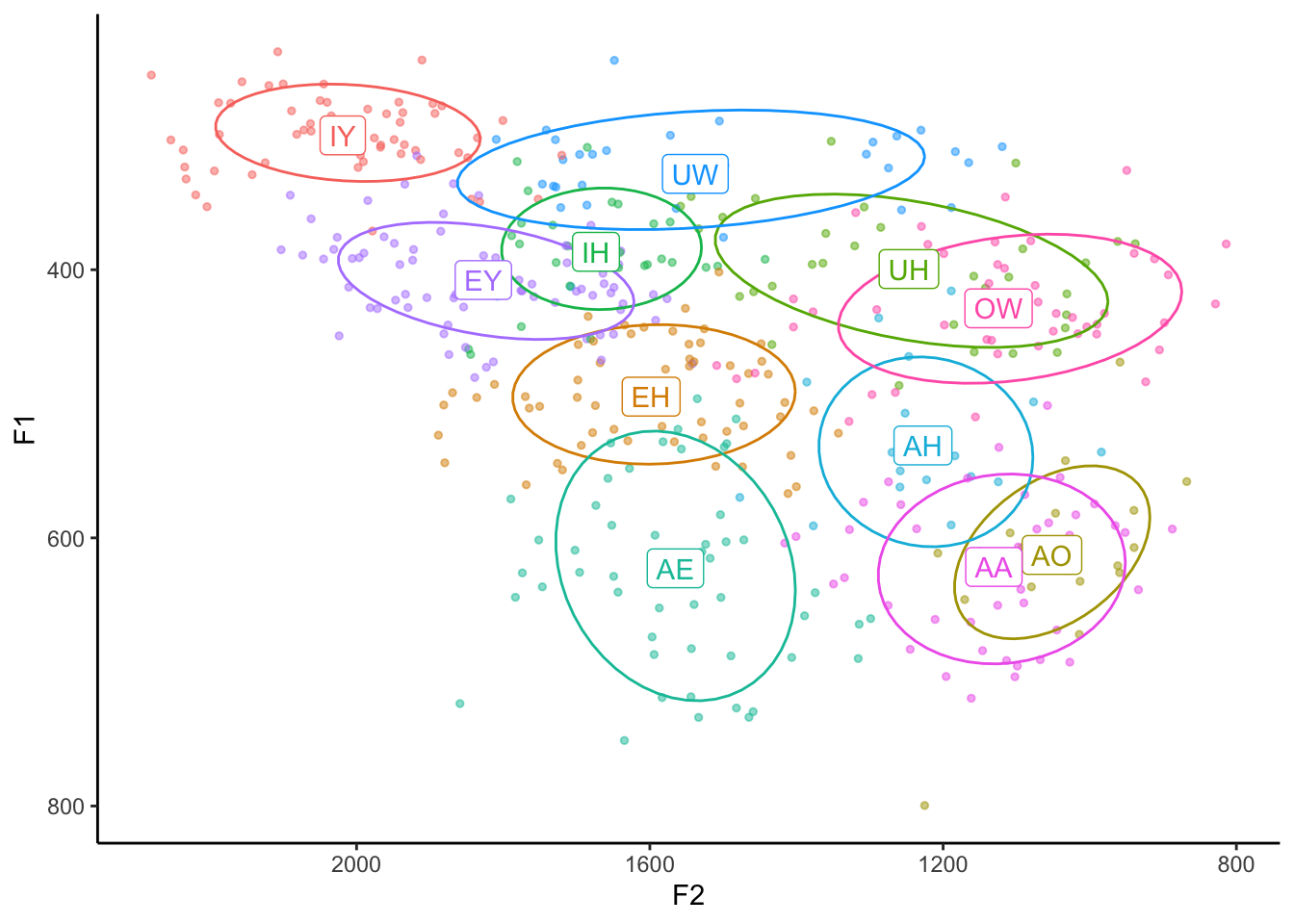
Shaded ellipses
I want to touch on how to shade the ellipses in. This takes slightly more finagling within stat_ellipse, but the result is pretty cool.
The main argument that you need to add is geom = "polygon" within stat_ellipse. Try that and see what the result is:
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
stat_ellipse(level = 0.67, geom = "polygon") +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()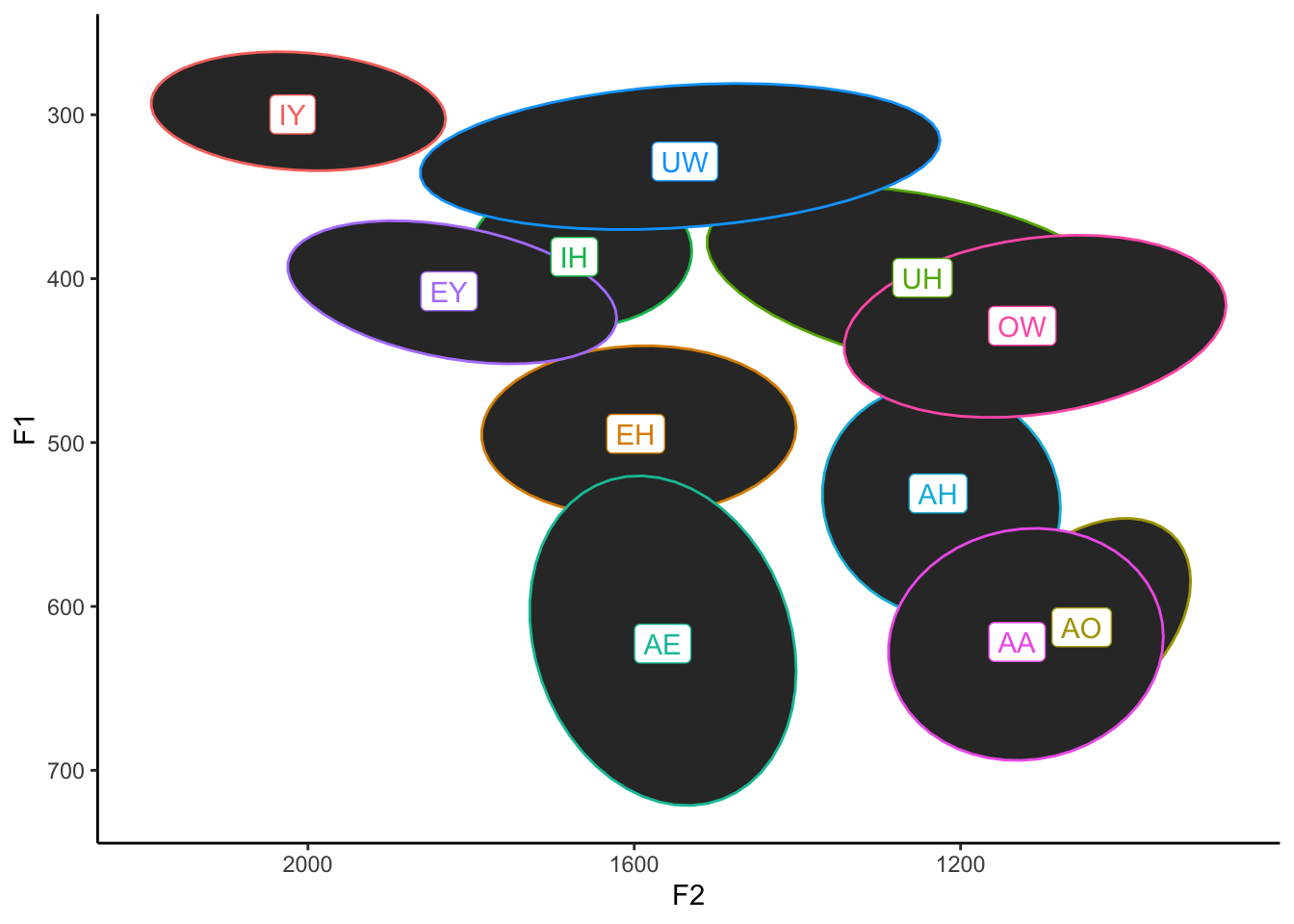
Okay, so that has the effect of filling them all in black. That’s probably not what we had in mind. Let’s make them all a bit transparent by adding the alpha = 0.2 argument as a part of stat_ellipse.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()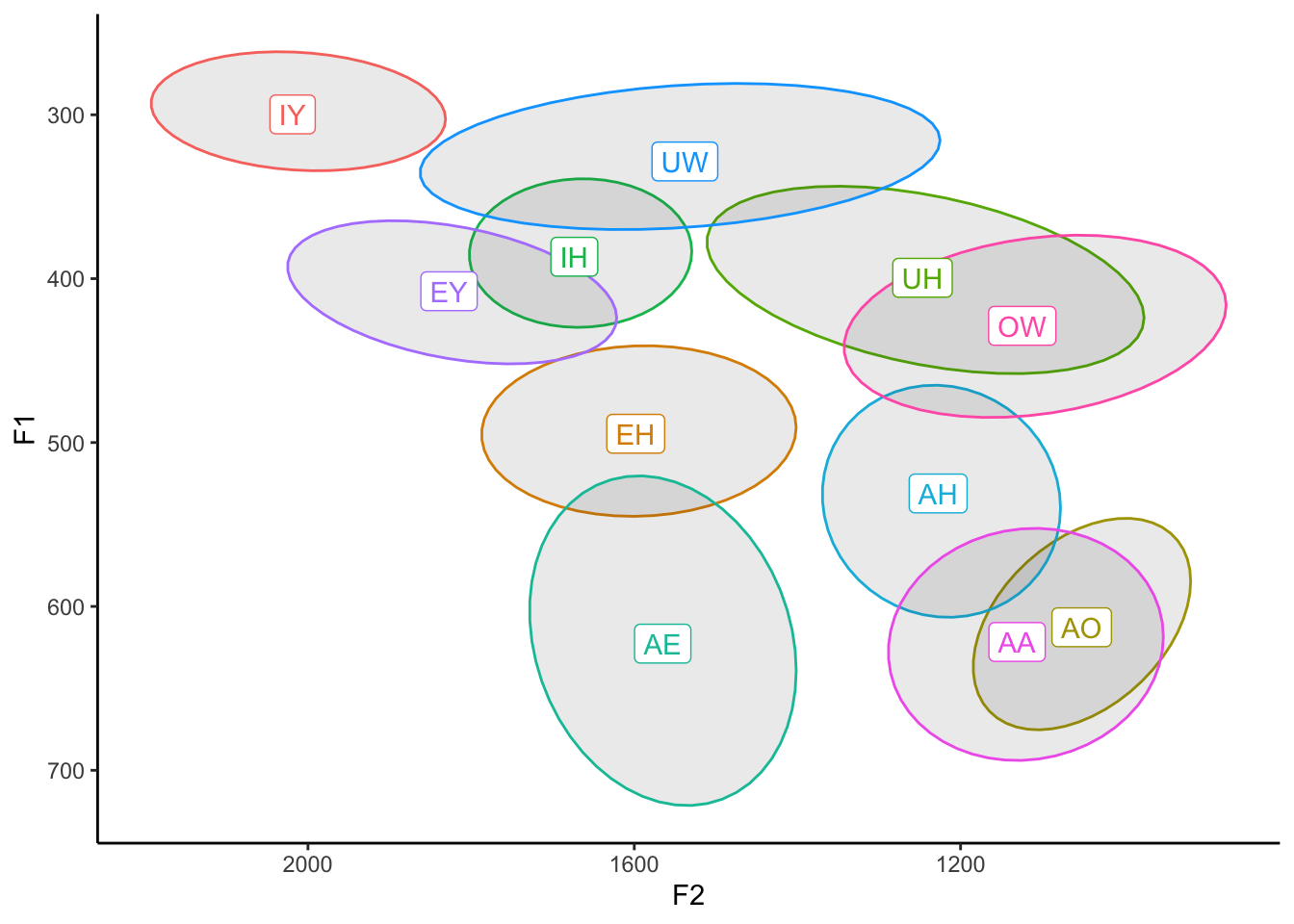
Finally, we can actually color these ellipses based on the vowels themselves by adding fill = vowel to our aes function:
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel, fill = vowel)) +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()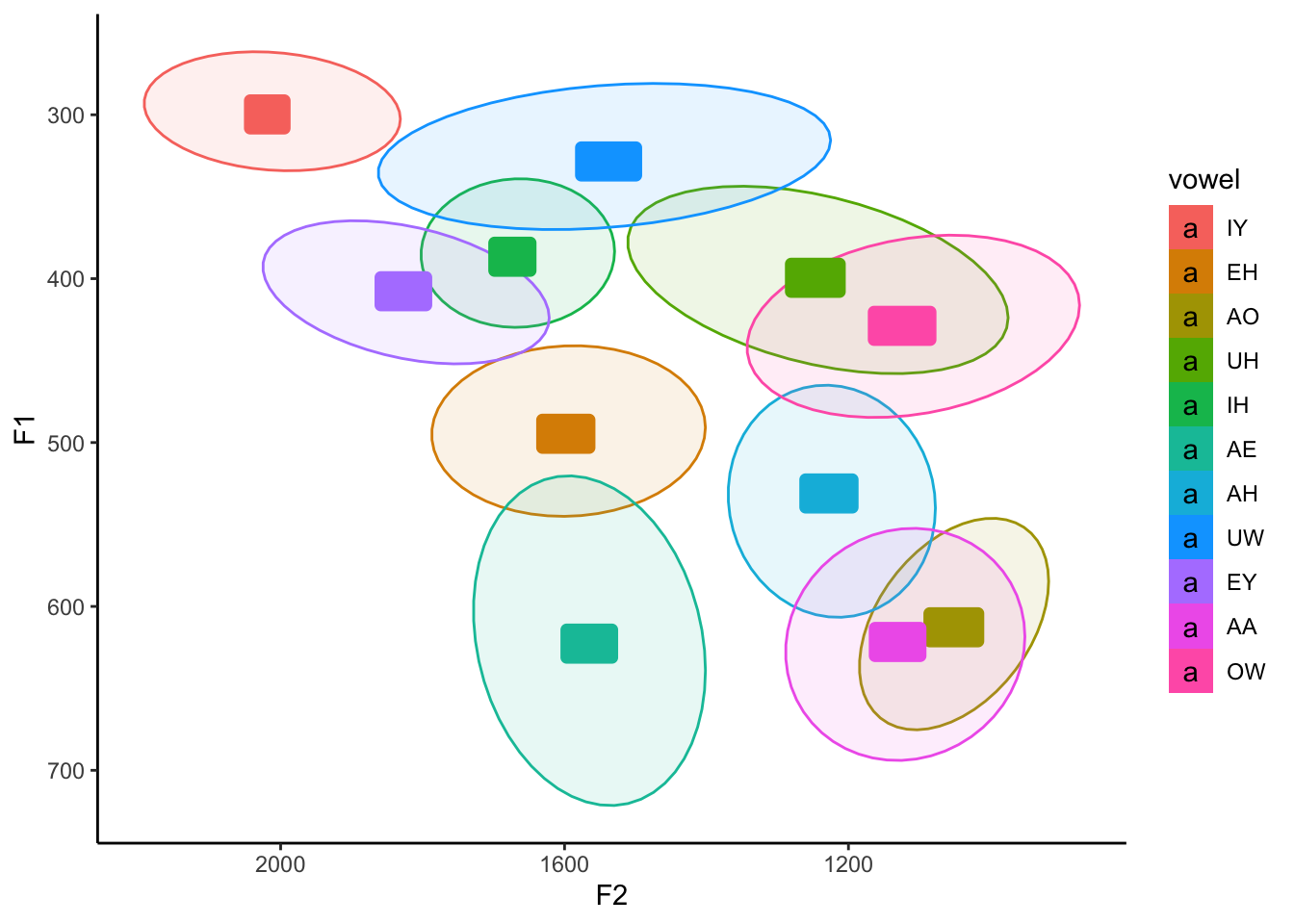
Whoops! What did that do? Yes, the ellipses are shaded in correctly, but now the labels are too! Turns out, in geom_label, the fill argument also modifies the background color, which is normally white. We could either override the fill on geom_label and set it to "white", or, better yet, let’s just add aes(fill = vowel) just to stat_ellipse to prevent any other potential bugs.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE) +
theme_classic()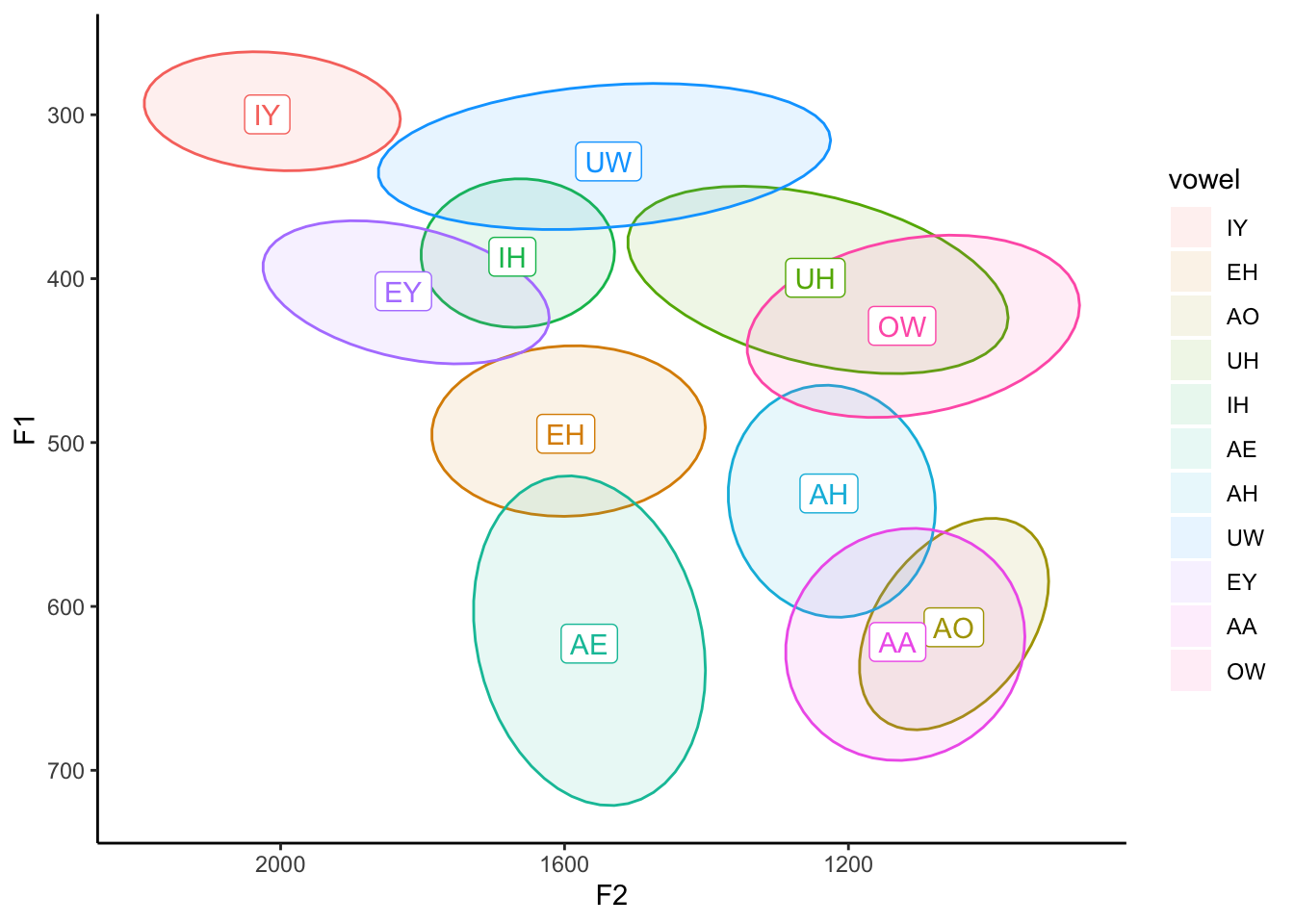
Aha. Now we get the desired result. Note though that our legend is back. This is because we told ggplot2 to not display a legend as it relates to color using guides(color = FALSE), but we didn’t say anything about this new fill aesthetic. We can just add fill = FALSE there and it’ll take it out.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
guides(color = FALSE, fill = FALSE) +
theme_classic()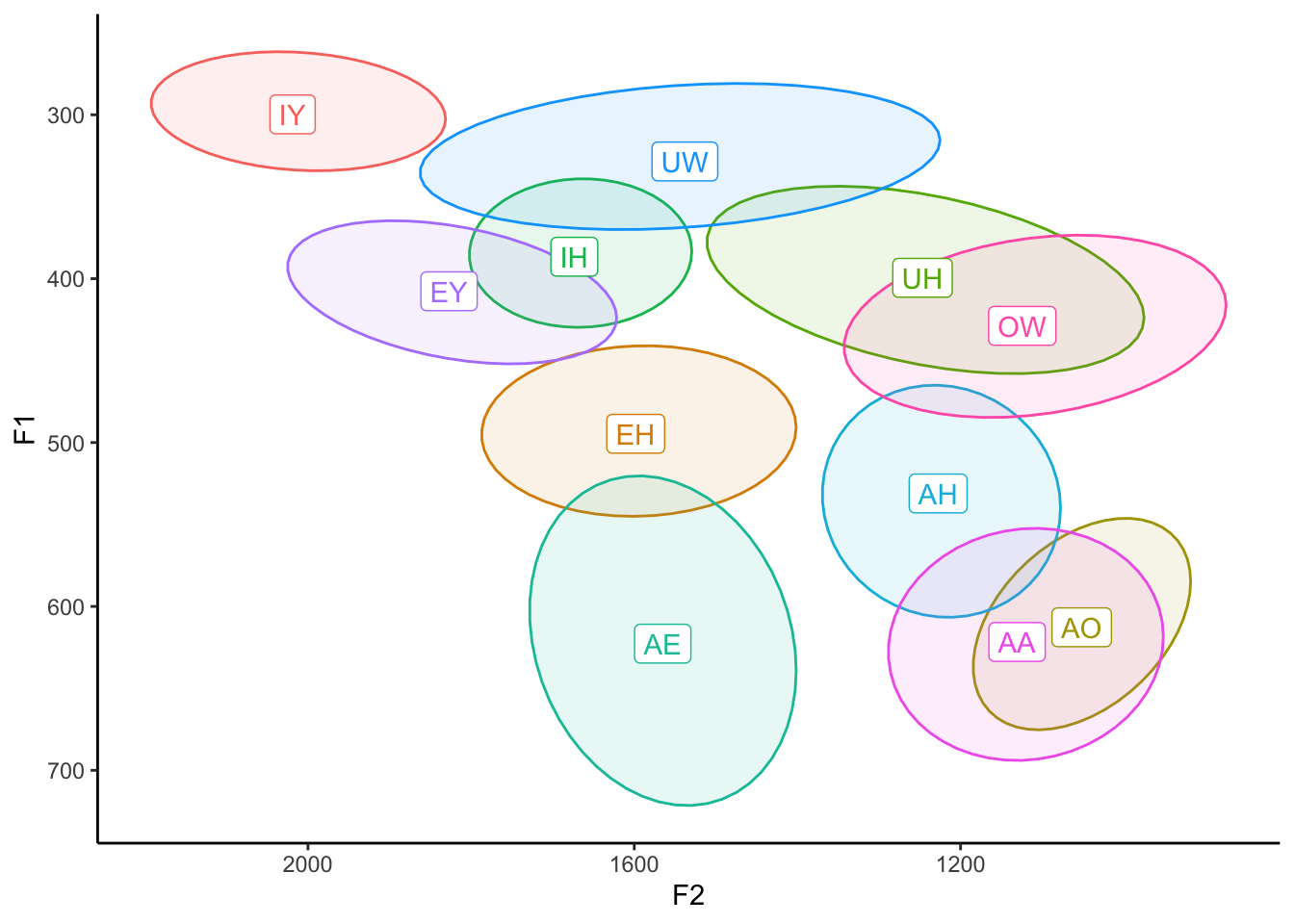
Really though, the guides option is only good if you want to remove specific aspects of the legend but not all of it. Alternatively, we can just use theme(legend.position = "none") instead and that’ll remove the legend no matter what else we add to the plot. However, this has to come after any themes you might apply to the plot.
ggplot(my_vowels, aes(x = F2, y = F1, color = vowel, label = vowel)) +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "IH", "EY", "EH", "AE",
"AA", "AO", "OW", "UH", "UW", "AH")) +
theme_classic() +
theme(legend.position="none")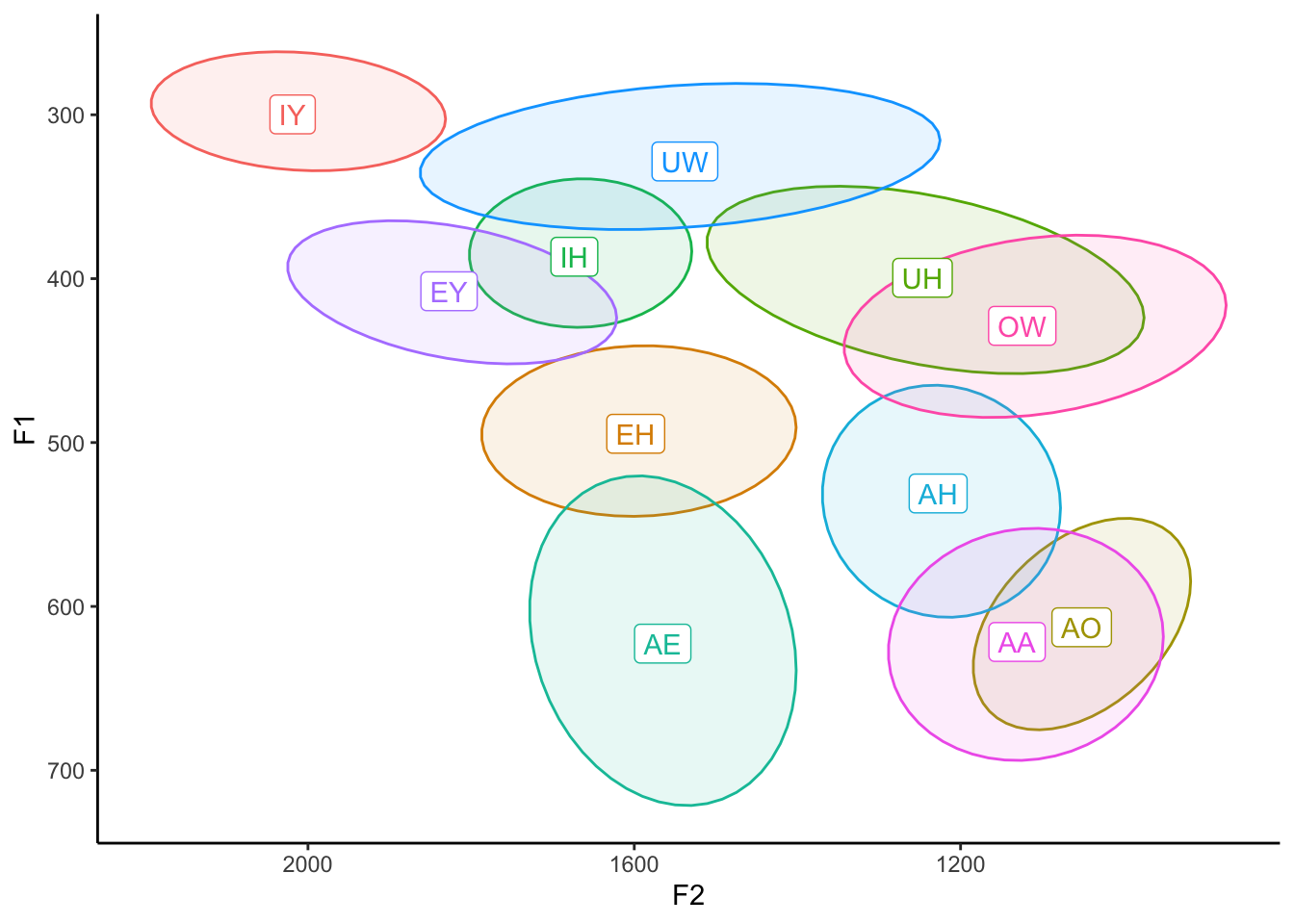
So shaded ellipses are cool, but because we have so many vowels in English they can get a little muddy. If you’re only working with a subset of English vowels or a language with fewer vowels, it’ll look a little crisper, even if you add the points back in. I’ll just take five vowels and plot them, and I’ll even add shape in there too for fun. (Can you see how I did that?)
my_five_vowels <- my_vowels %>%
filter(vowel %in% c("IY", "EH", "AA", "OW", "UW"))
five_means <- my_five_vowels %>%
summarise(F1 = mean(F1),
F2 = mean(F2),
.by = vowel)
ggplot(my_five_vowels, aes(x = F2, y = F1, color = vowel, label = vowel, shape = vowel)) +
geom_point() +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = five_means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("IY", "EH", "AA", "OW", "UW")) +
theme_classic() +
theme(legend.position="none")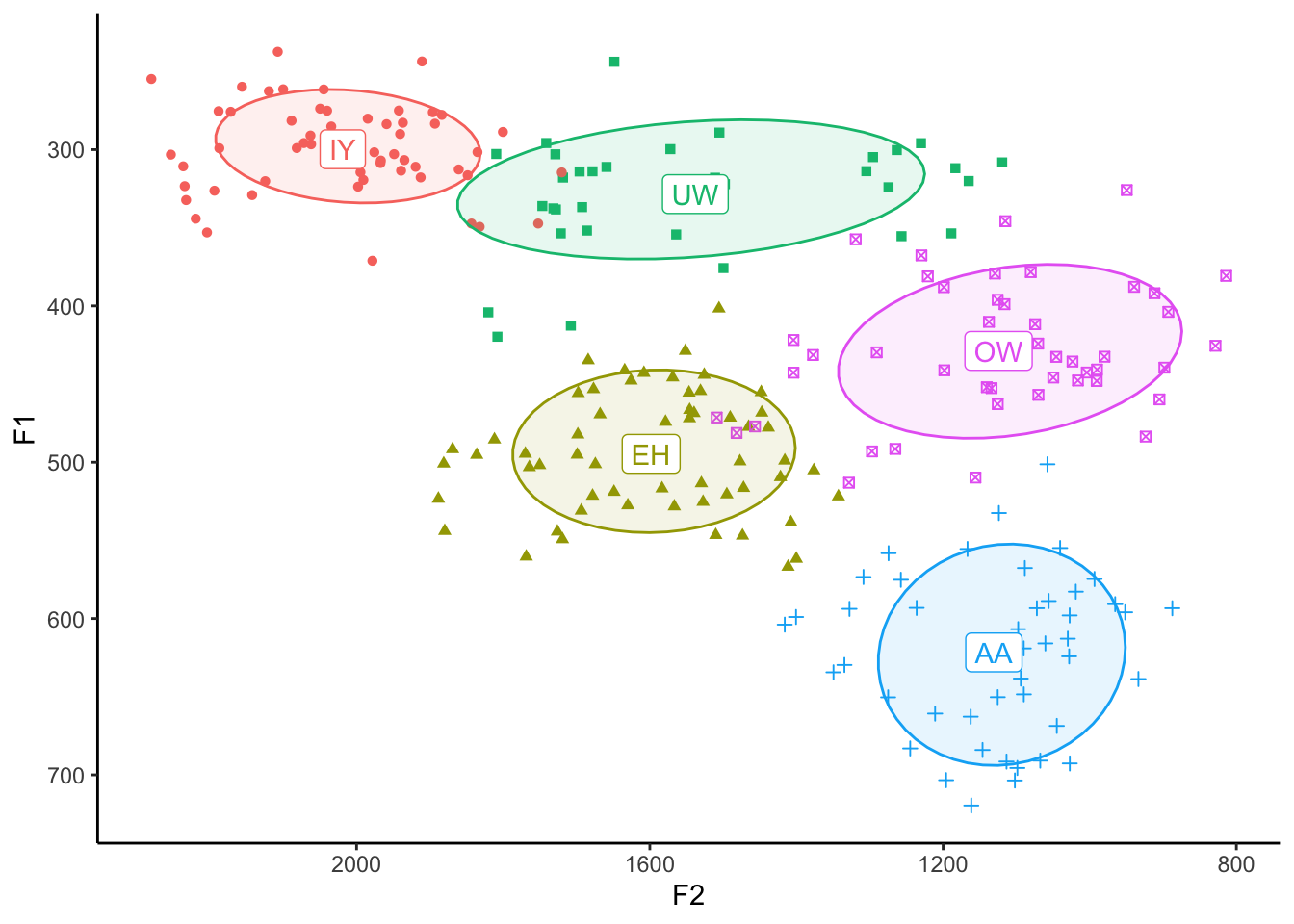
Text instead of points
Okay, last thing, I promise. If your dataset is relatively small, a really slick trick is to plot the words themselves rather than points. We saw how to do this above when we were plotting the means, but let’s apply that to the regular data. For this example, I’ll just zoom in on my “AA” and “AO” vowels (except for the ones before /ɹ/) because I’ve been reading about the cot-caught merger recently.
cot_caught <- my_vowels %>%
filter(vowel %in% c("AA", "AO"),
fol_seg != "R")
cot_caught_means <- cot_caught %>%
group_by(vowel) %>%
summarise(F1 = mean(F1),
F2 = mean(F2))So here’s what this would look like with points.
ggplot(cot_caught, aes(x = F2, y = F1, color = vowel, label = vowel, shape = vowel)) +
geom_point() +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = cot_caught_means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("AA", "AO")) +
theme_classic() +
theme(legend.position="none")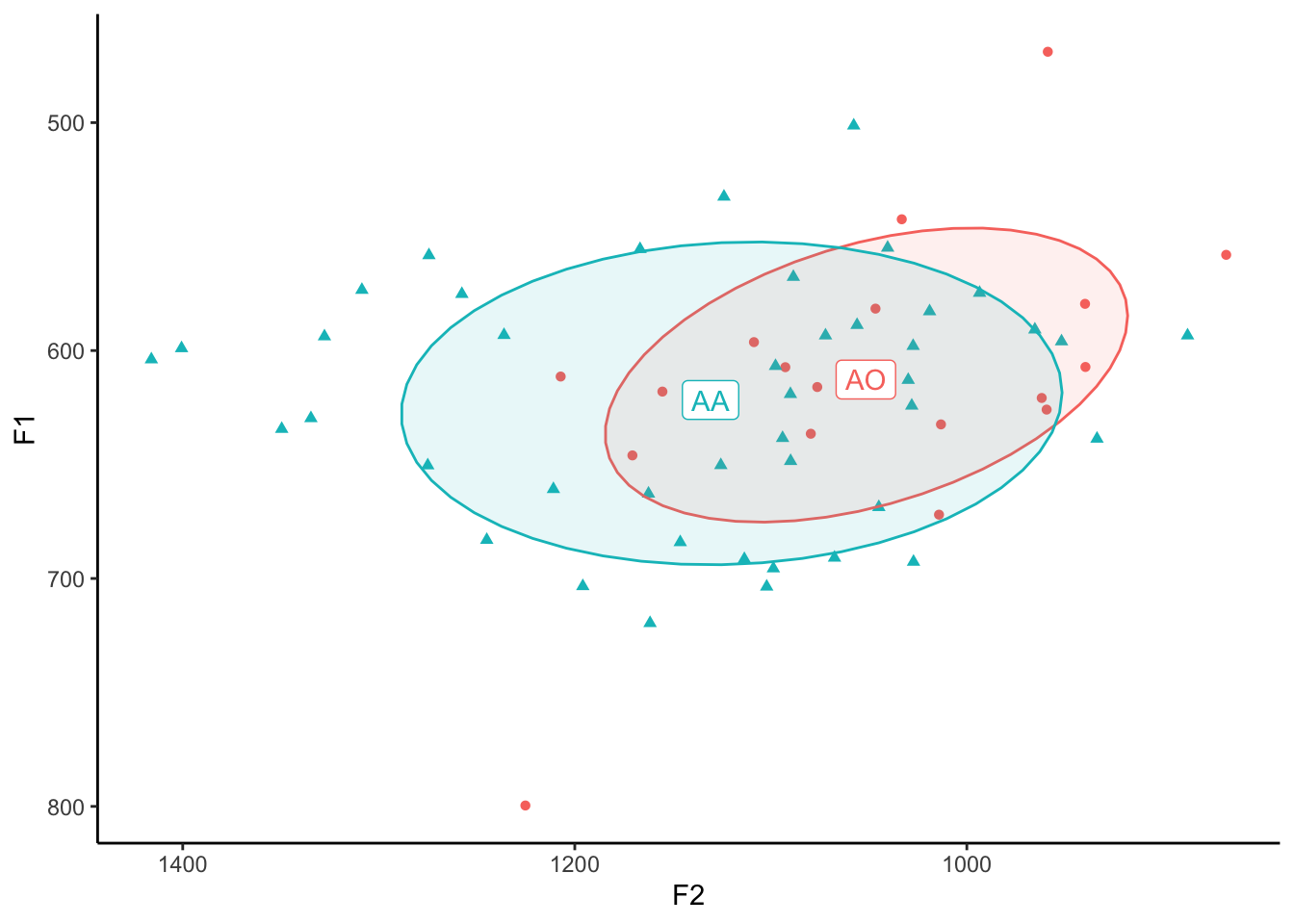
The trick here is to use geom_text instead of geom_point. Note that geom_text is very similar to geom_label, which is what we used for the means. The only difference I’ve been able to see is that there’s a nice little box around geom_label and not one for geom_text.
ggplot(cot_caught, aes(x = F2, y = F1, color = vowel, label = vowel, shape = vowel)) +
geom_text() +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = cot_caught_means) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("AA", "AO")) +
theme_classic() +
theme(legend.position="none")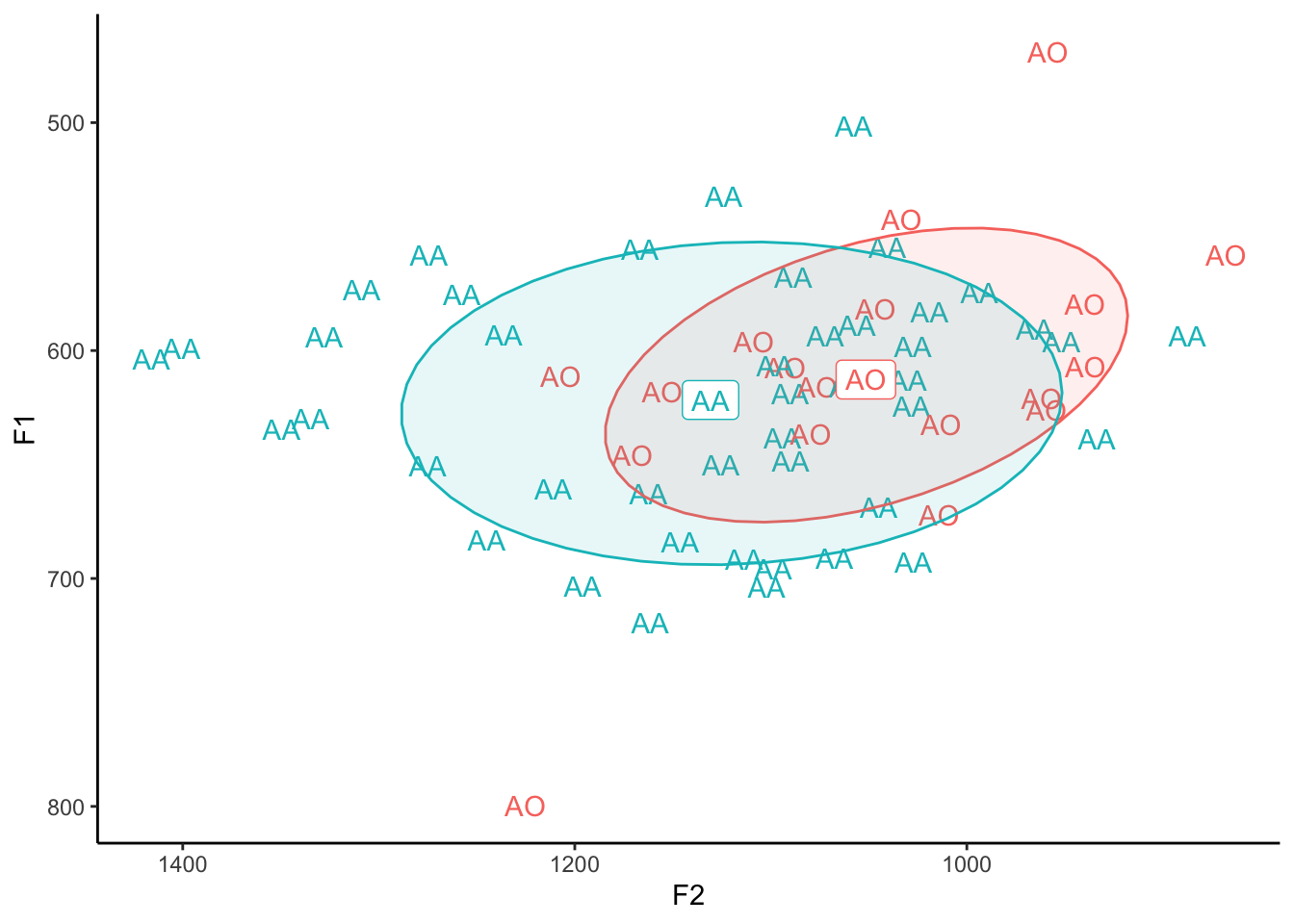
Oops! That’s not what we wanted! For the means, yes, we want the vowel. But for the points we want the actual word. This means we have to add label = word to our code somewhere. For clarity, I’ll move label = vowel out of ggplot(aes() and into geom_label(aes()). That way there is no default label and every time we call geom_text or geom_label we need to specify label individually. (Also, I’ll get rid of shape = vowel since that’s not being used anymore.)
ggplot(cot_caught, aes(x = F2, y = F1, color = vowel)) +
geom_text(aes(label = word)) +
stat_ellipse(level = 0.67, geom = "polygon", alpha = 0.1, aes(fill = vowel)) +
geom_label(data = cot_caught_means, aes(label = vowel)) +
scale_x_reverse() +
scale_y_reverse() +
scale_color_discrete(breaks = c("AA", "AO")) +
theme_classic() +
theme(legend.position="none")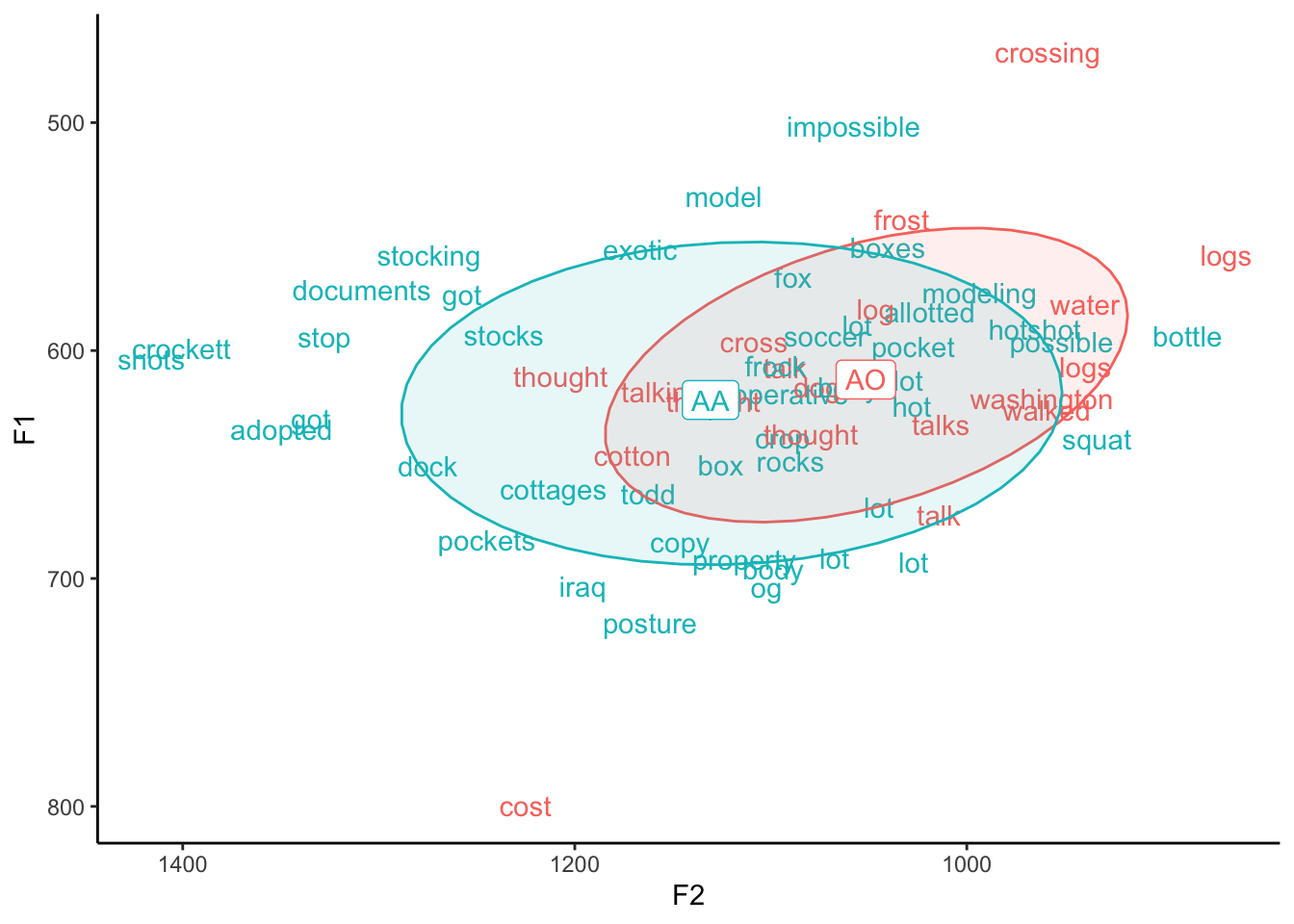
Aha! There we go. So this is a way to make a plot look cooler. Especially if individual lexical items are part of your analysis and particularly if you don’t have a lot of data to show at once. If you want, try it with the full dataset just to see how not helpful it is, but be aware that it can be slow to render if you have a lot of data to show.
Final remarks
The way you present your data is all up to you. I often prefer a set of settings when I’m playing around with my data, but then switch to a different set when I want to copy and paste into a presentation or paper. It’s good to be comfortable enough with ggplot2 so that you know what is going on and what changes you can make. Hopefully this post made a few things clearer.
If you’re interested in plotting trajectories, feel free to look at Part 2 of this tutorial. In the future, I’d like make some other posts on some slightly more advanced topics in vowel plots. I hope this one at least has helped you and your research.