

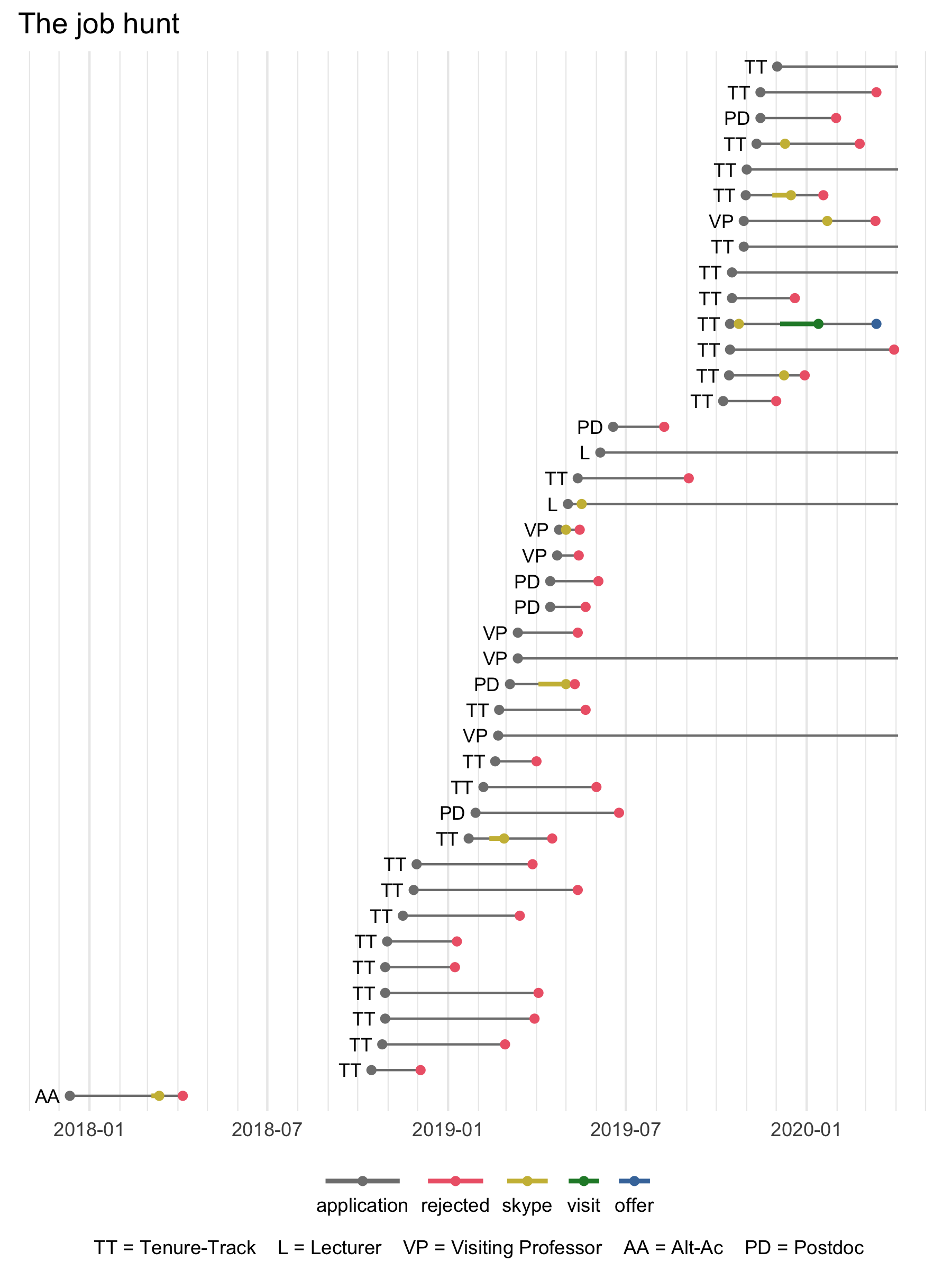
LSA and ADS 2025
Conferences
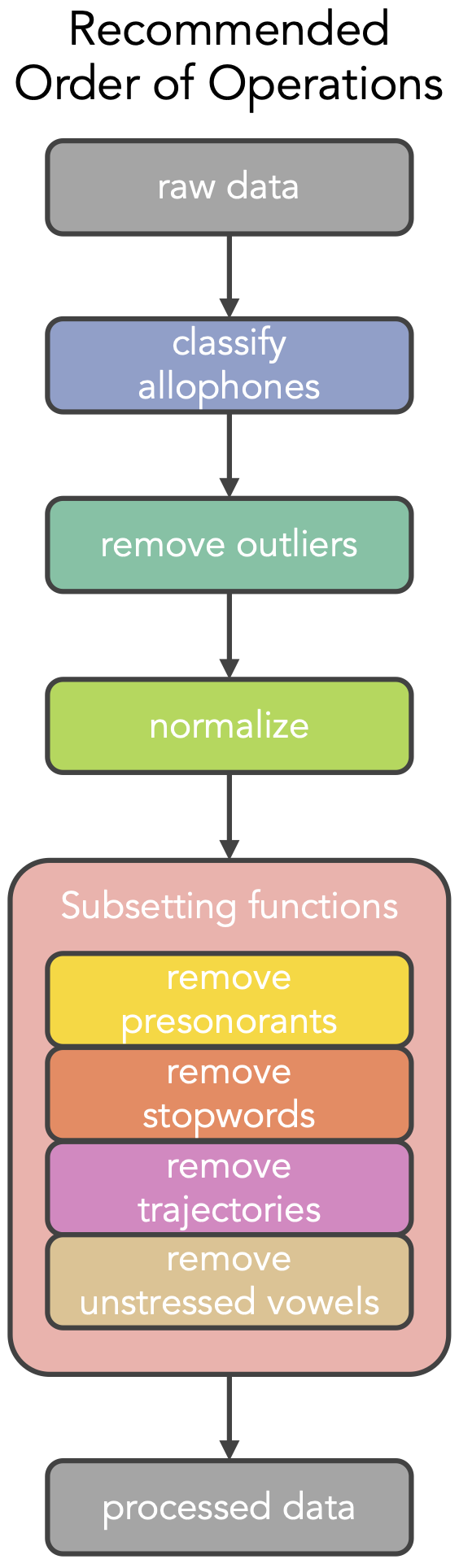
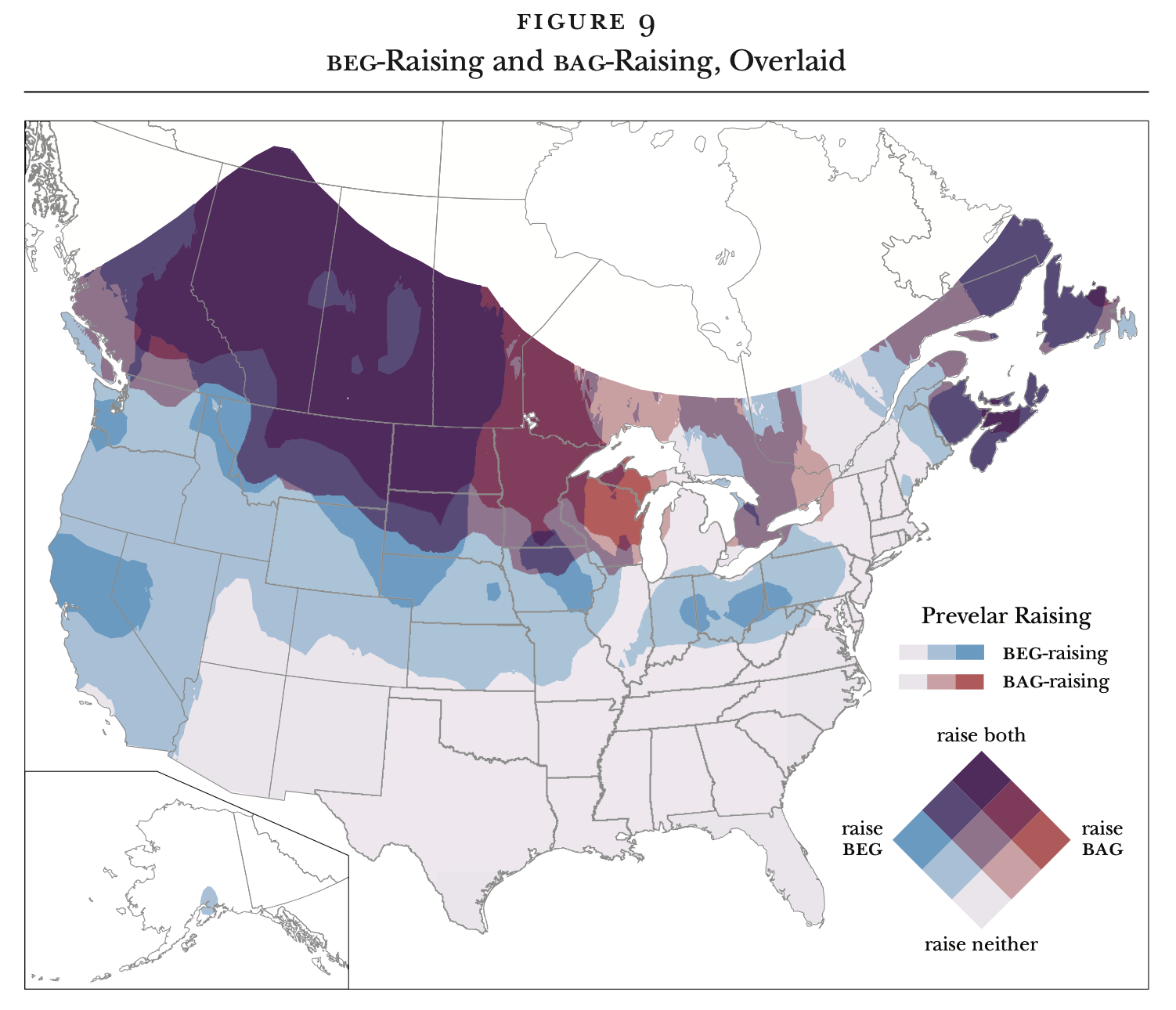
Kohler Tapes
Methods
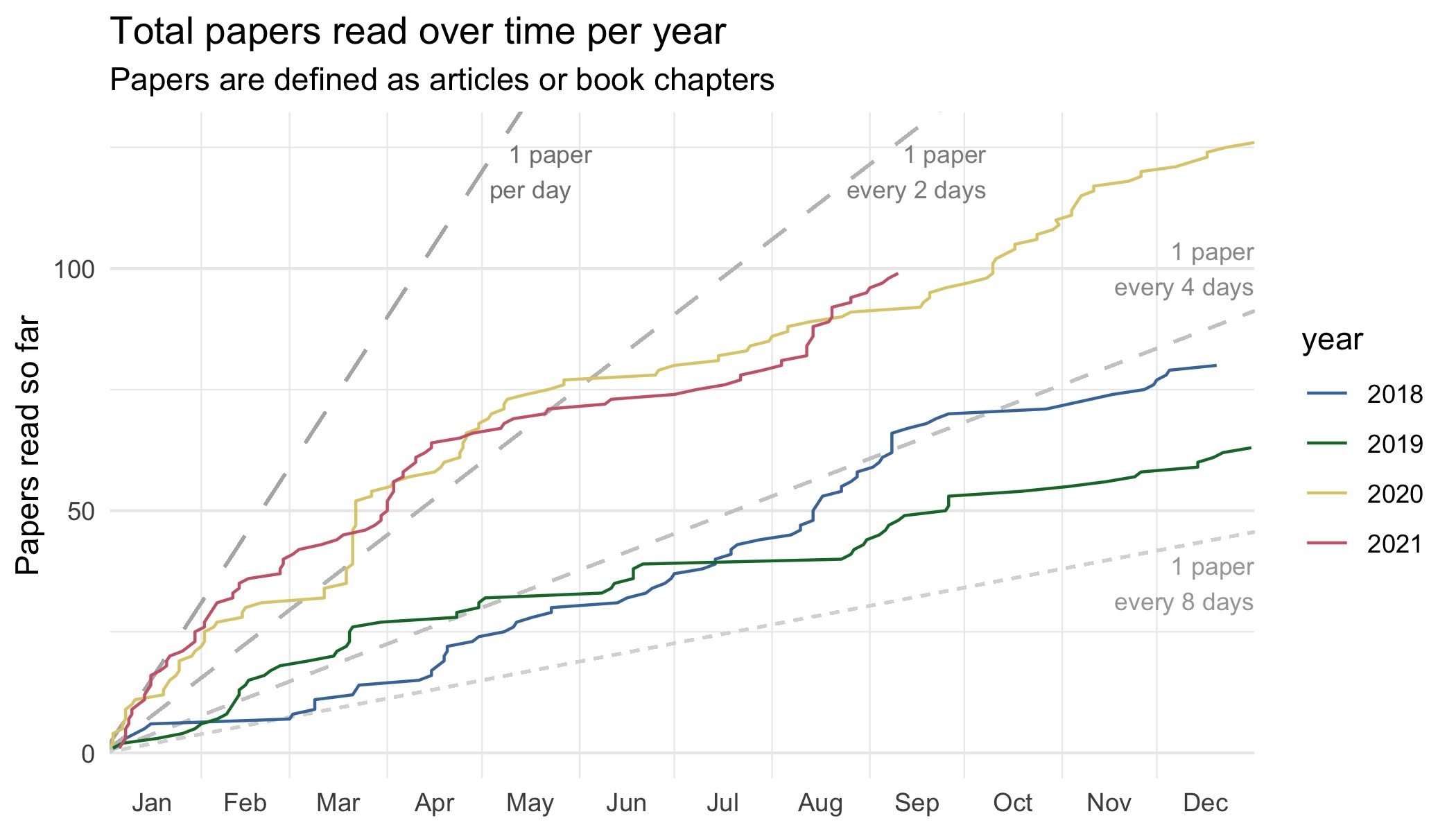
Presentations
Research
Students
Utah


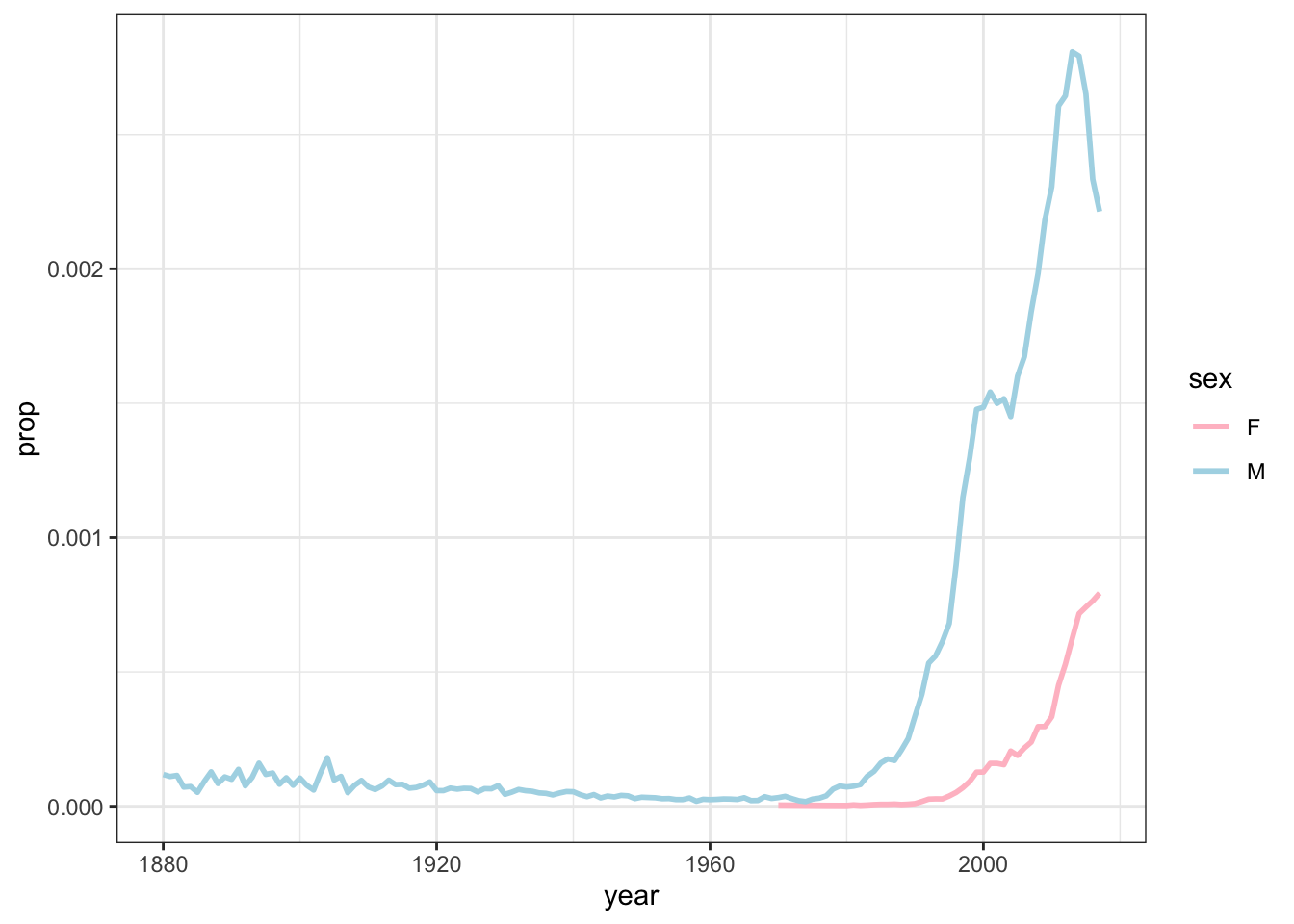
New publication on Missionary Voice in Proceedings of the Linguistic Society of America
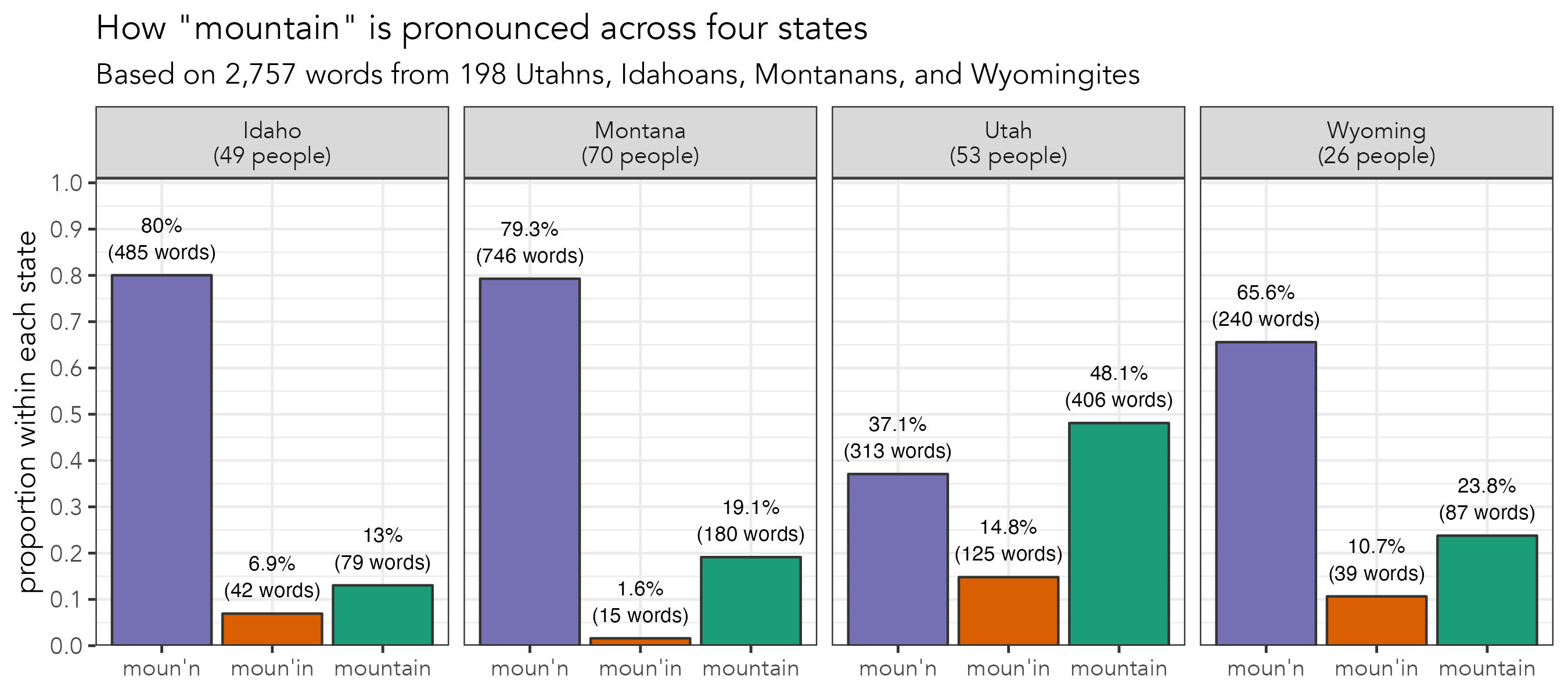
Mormonese
Research
Publications
Students

LSA and ADS 2024
Conferences
Presentations
Research
Students
Utah
SoSy
Conferences
Presentations
Research
Students
LSA and ADS 2023
Conferences
Presentations
Research
Students
Utah
West
NWAV50
Conferences
Methods
Phonetics
Presentations
Research
Simulations
Statistics
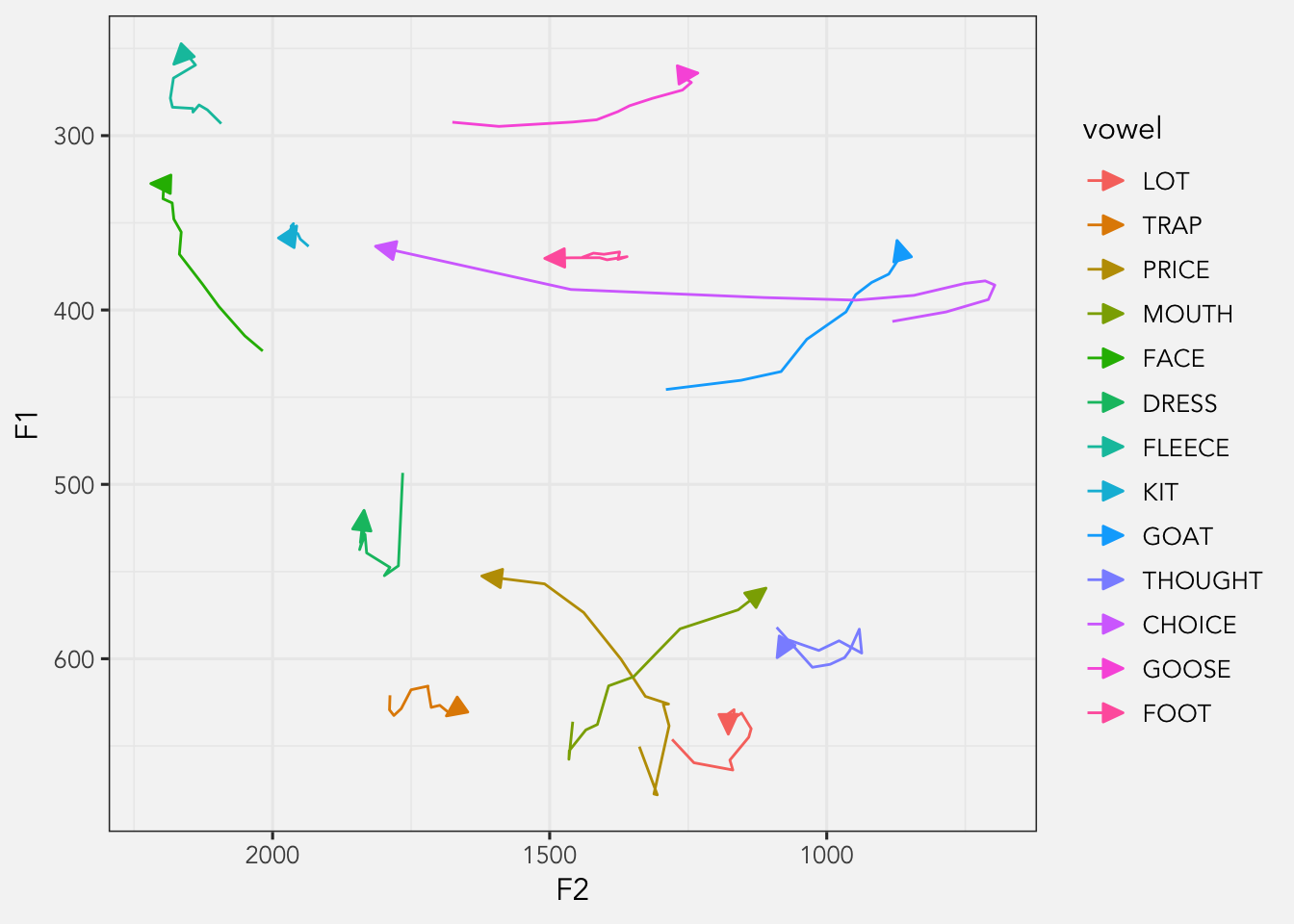
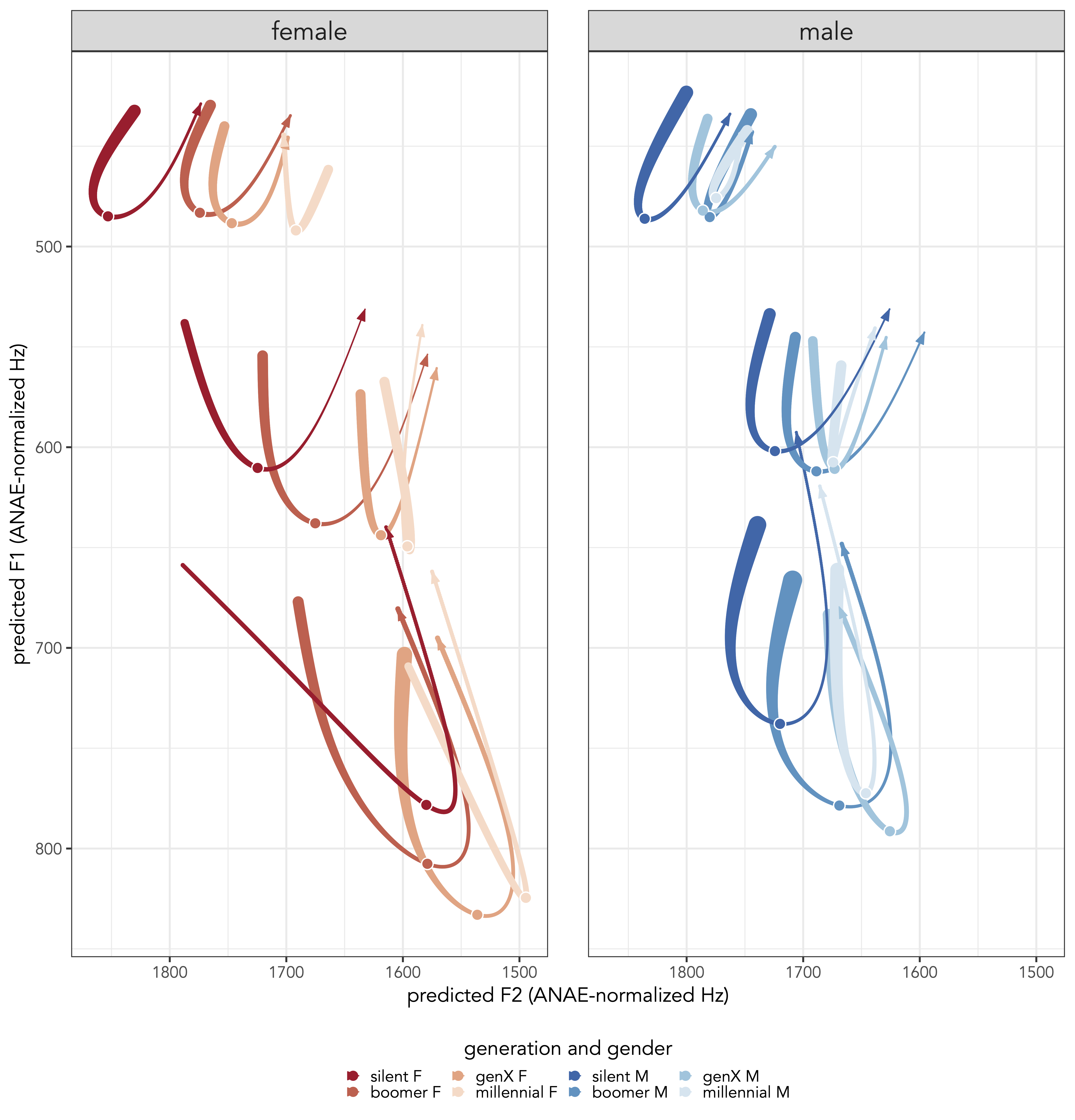
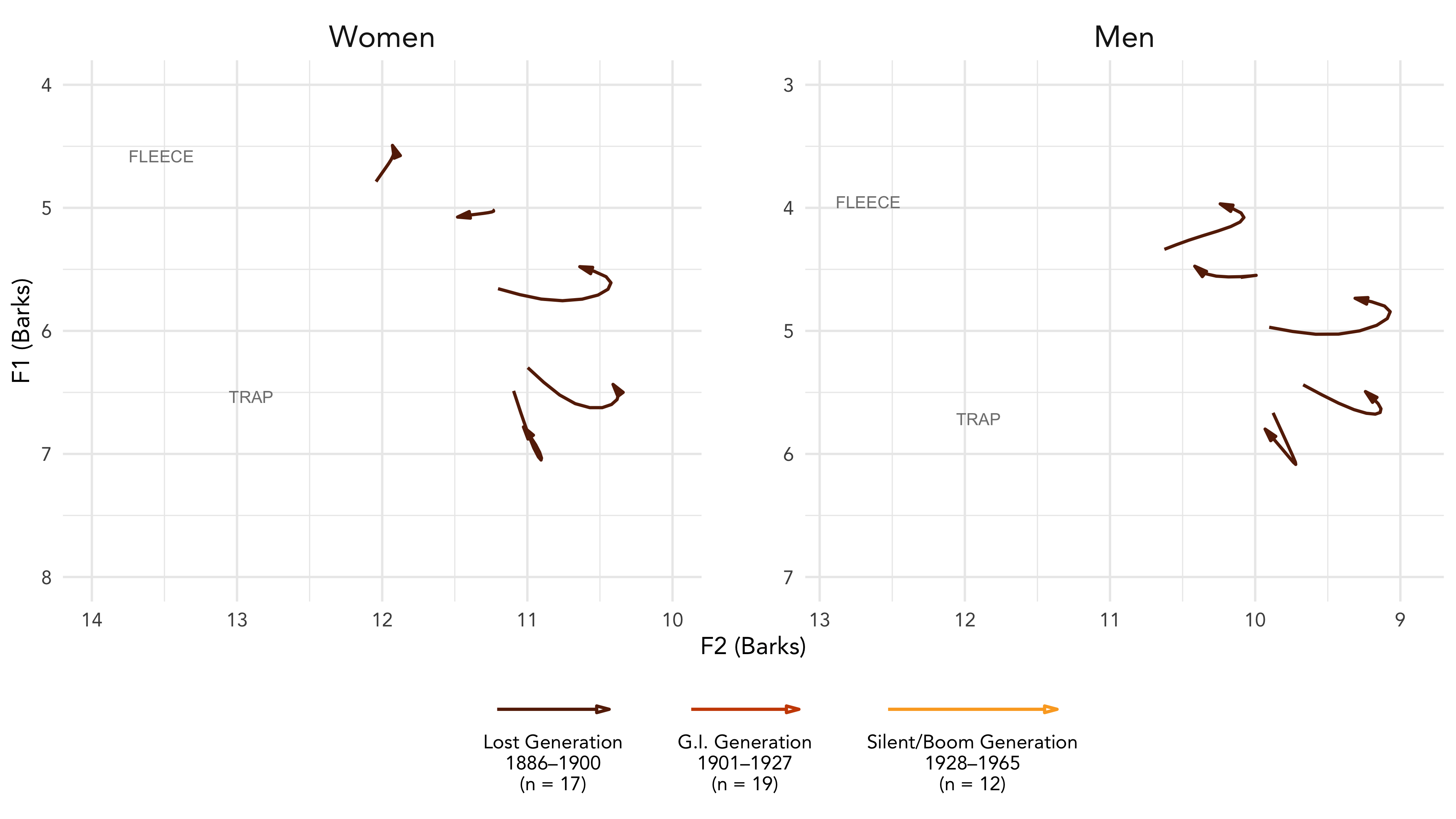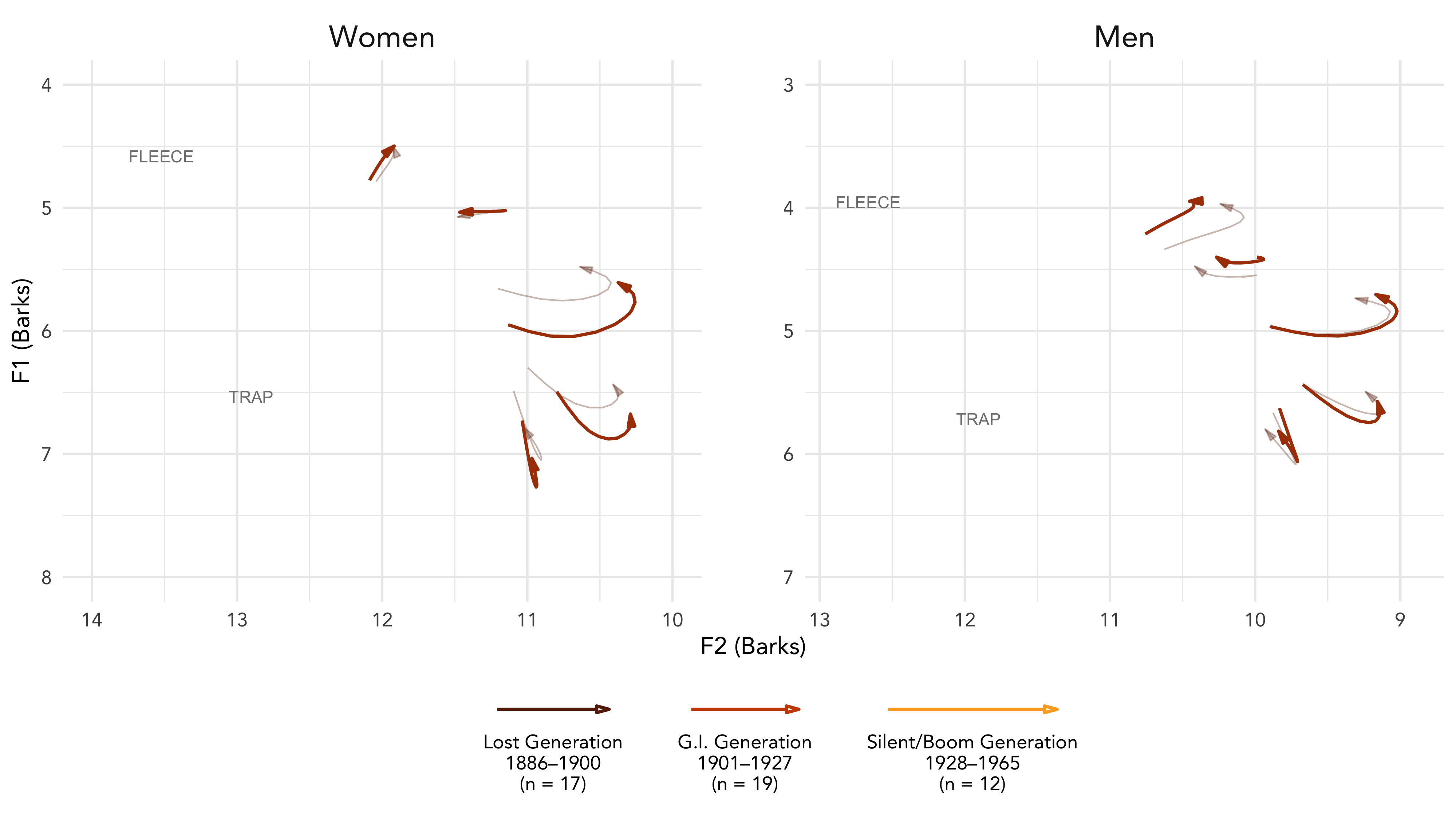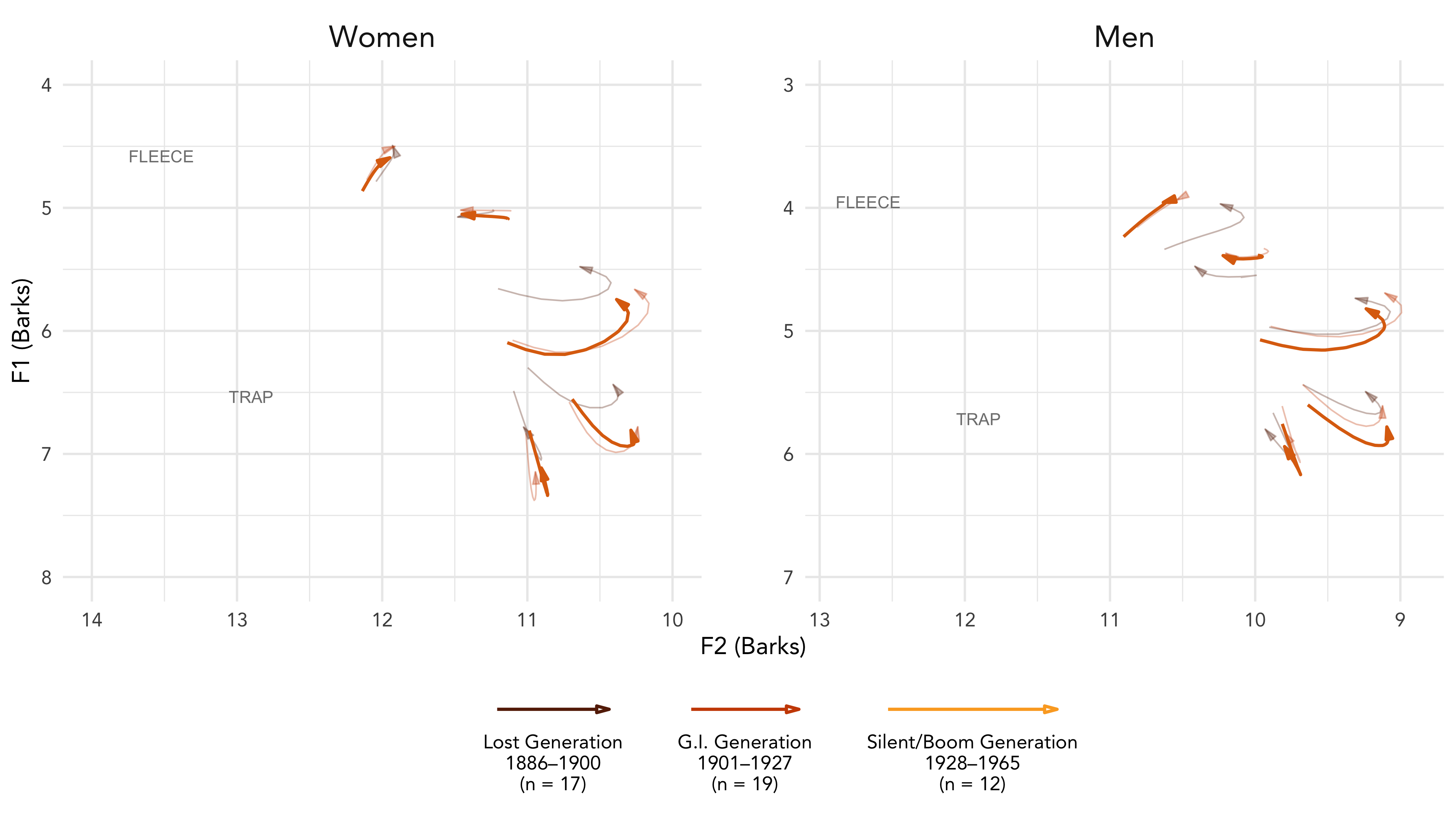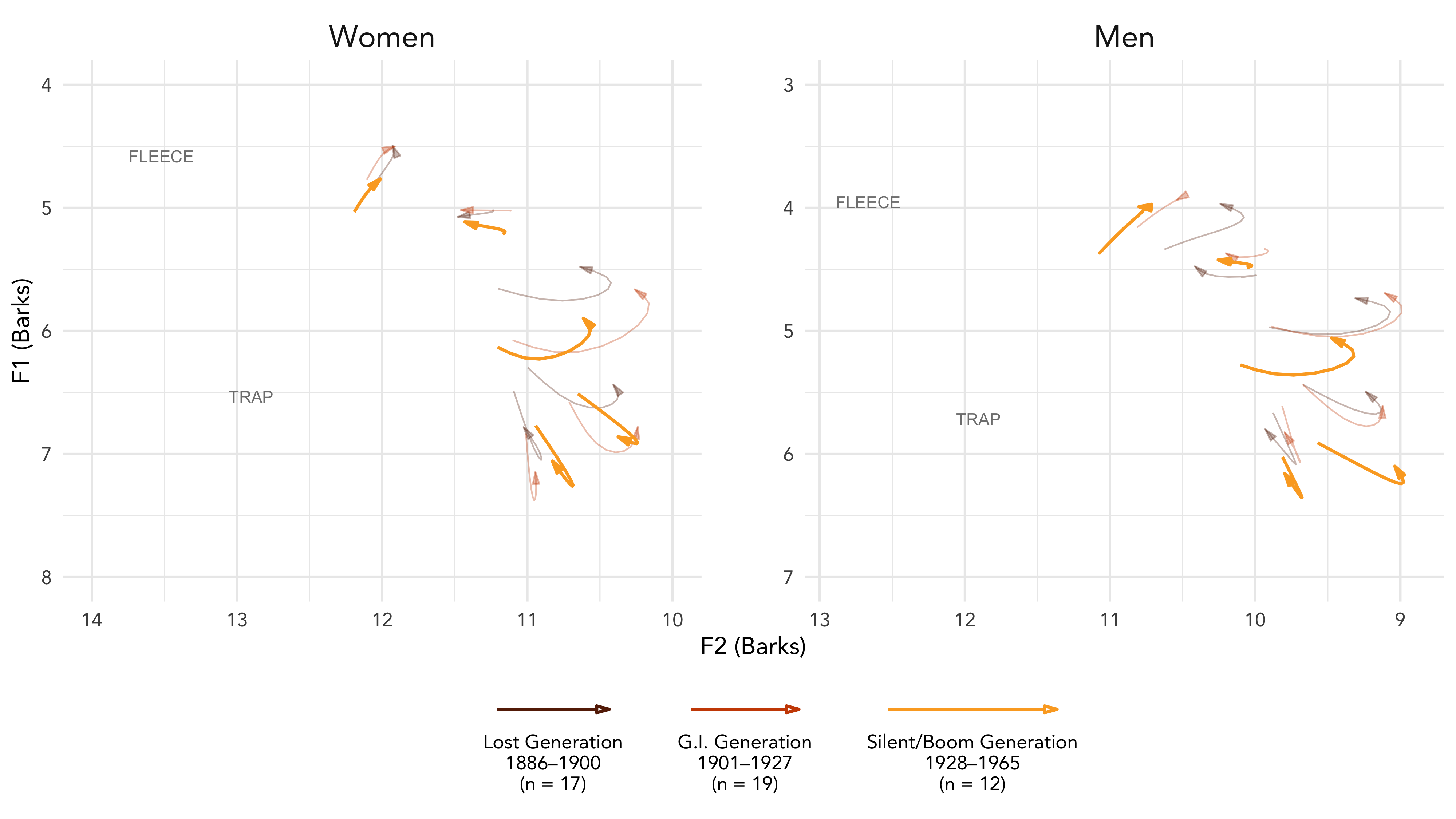
Vowel Overlap
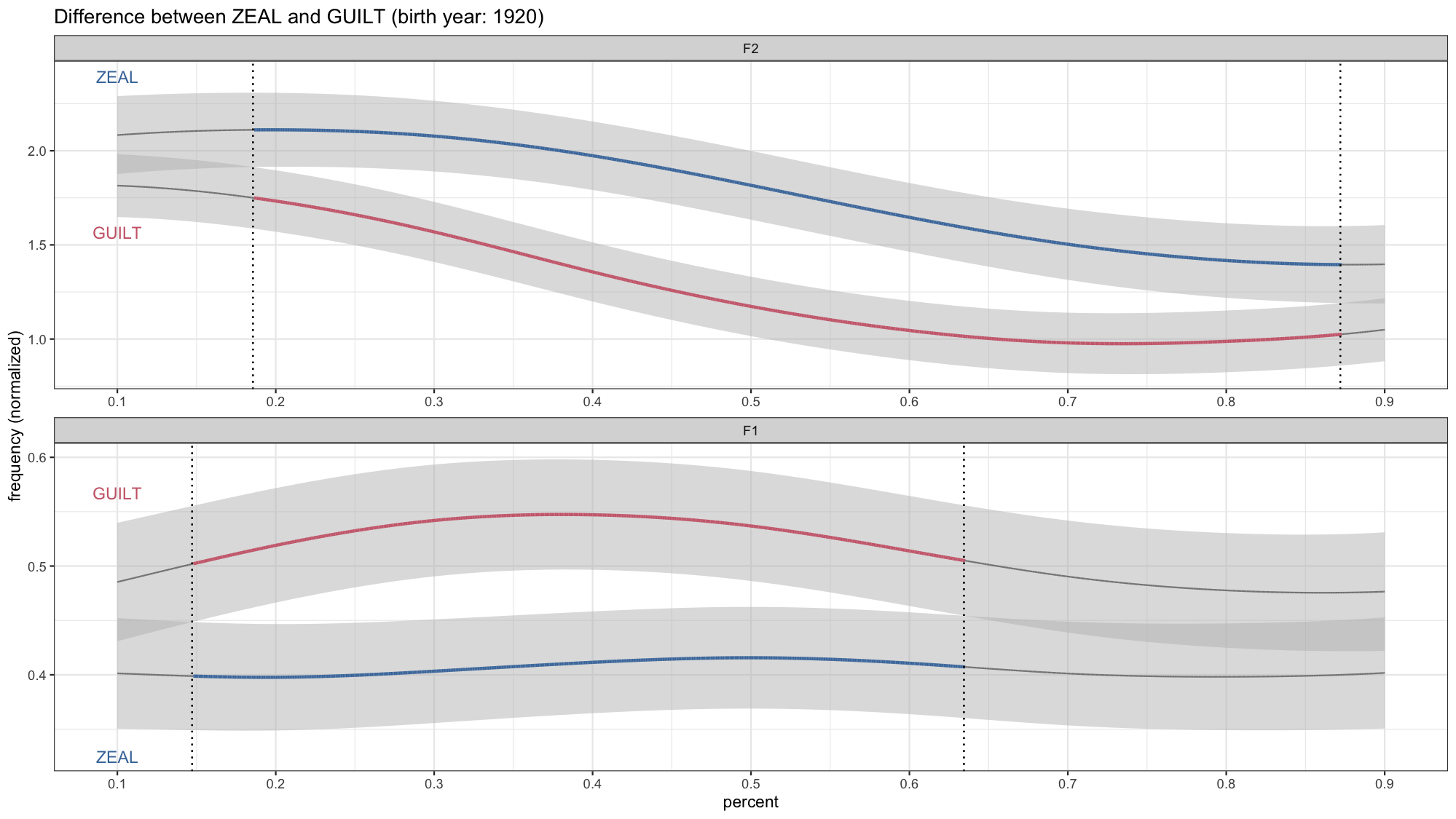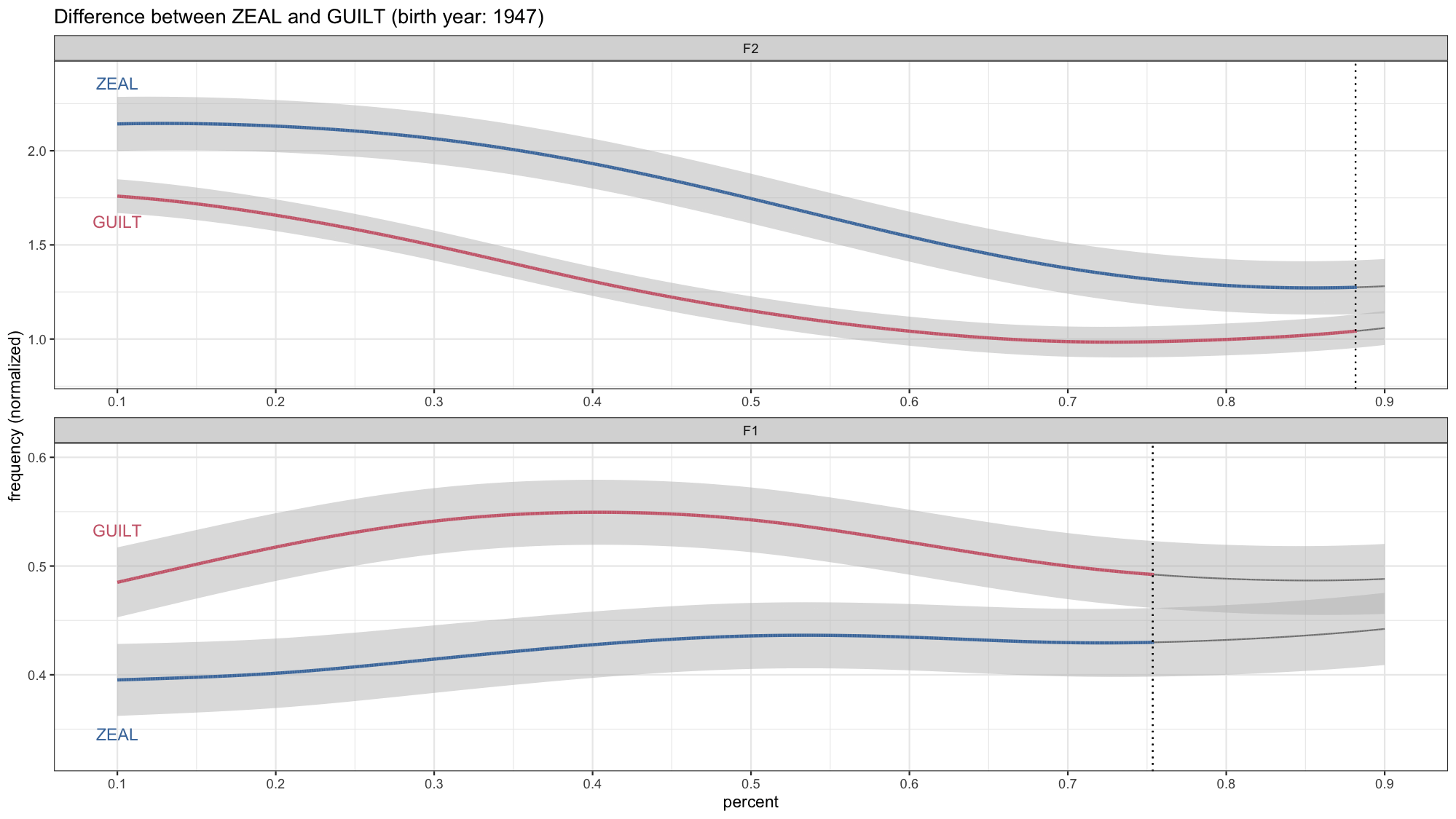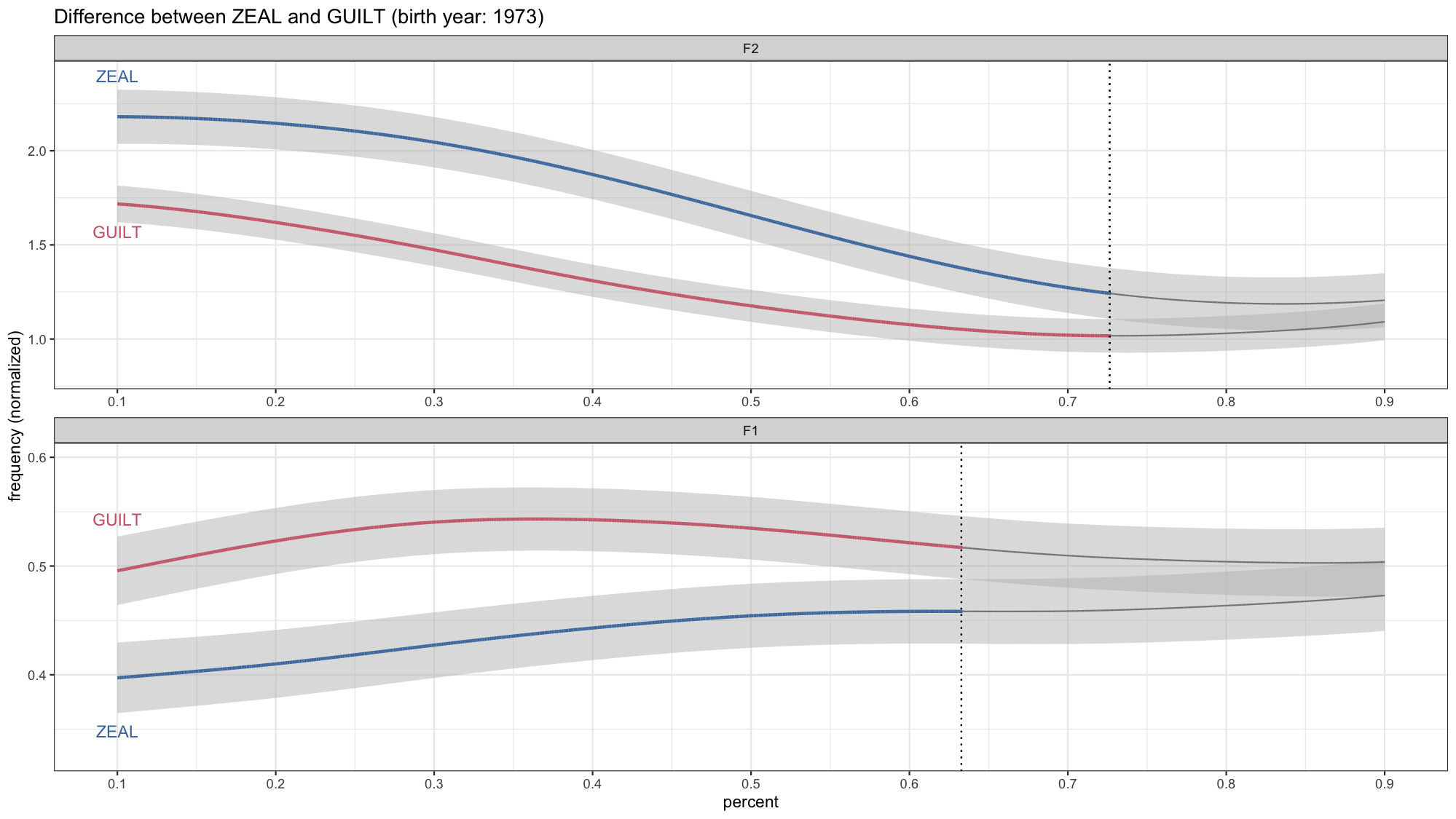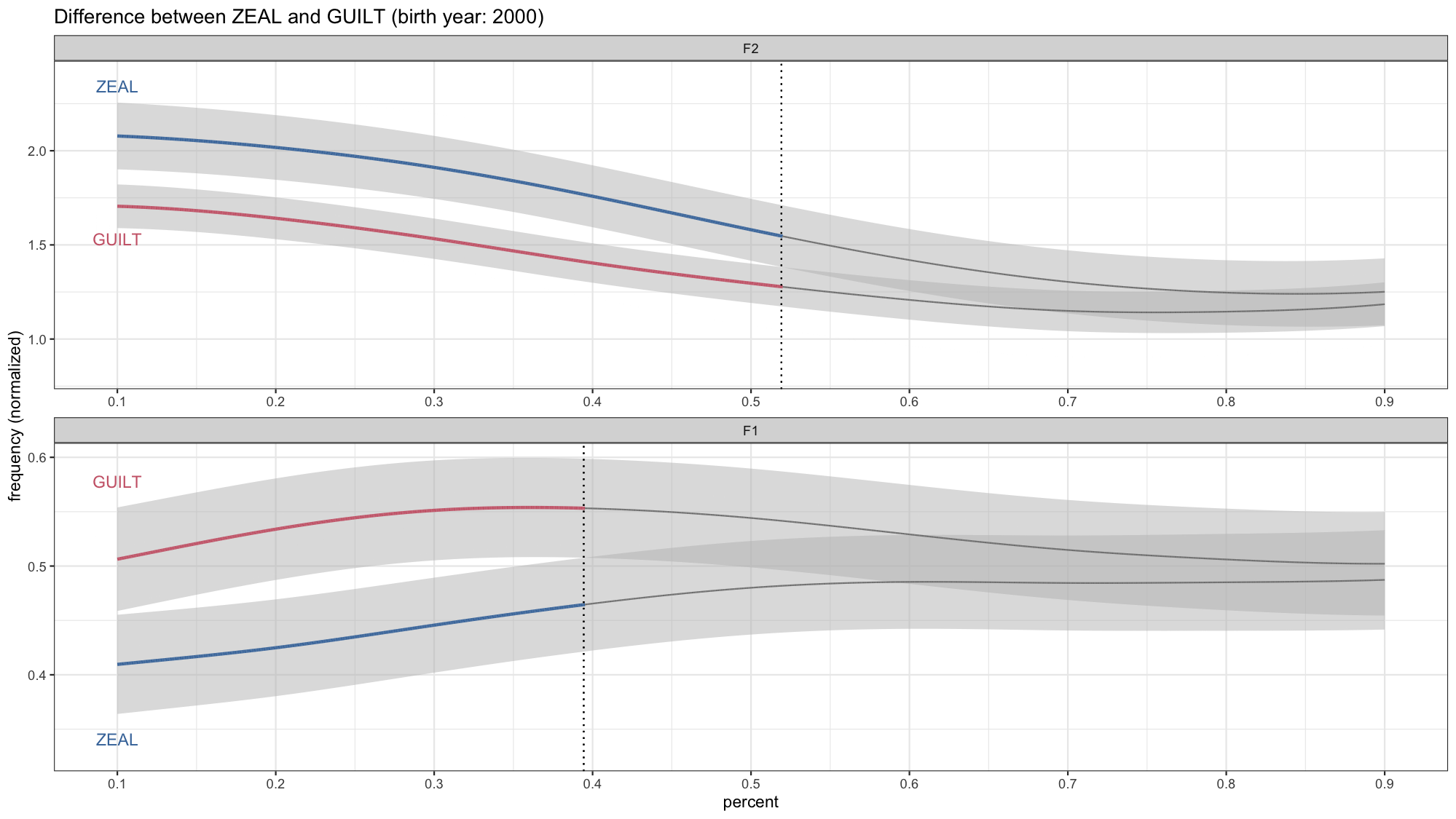
Animating Formant Trajectories
Animations
Data Viz
How-to Guides
R
Skills
Vowel Overlap
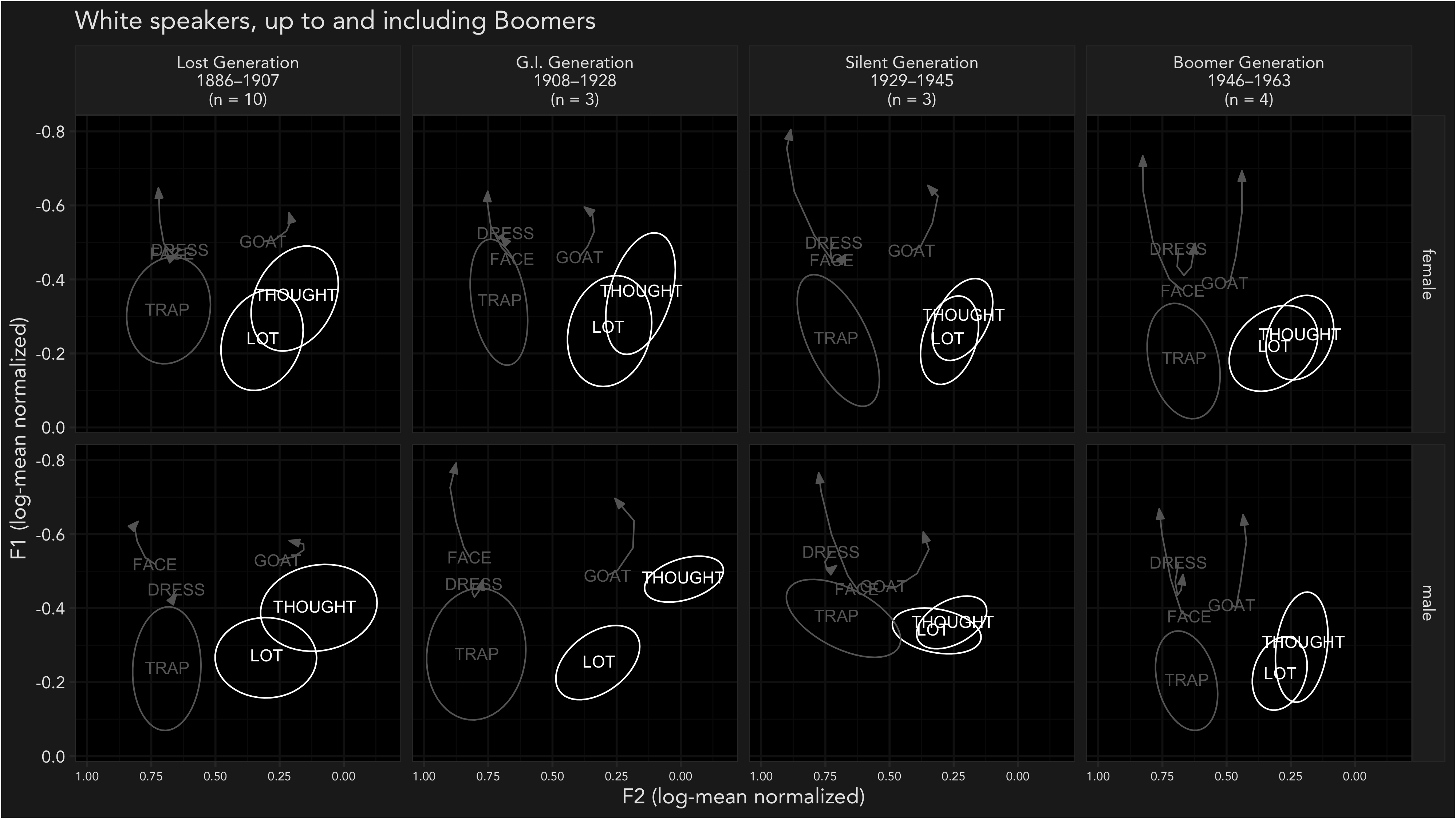
ADS and LSA 2022
Animations
Conferences
Data Viz
MTurk
Phonetics
Presentations
R
Research
South
Students
Utah
Vowel Overlap
West
ASA181
Conferences
Dissertation
Methods
Pacific Northwest
Phonetics
Presentations
R
Research
Simulations
Statistics
Vowel Overlap
NWAV49
Conferences
Methods
Presentations
Research
Simulations
South


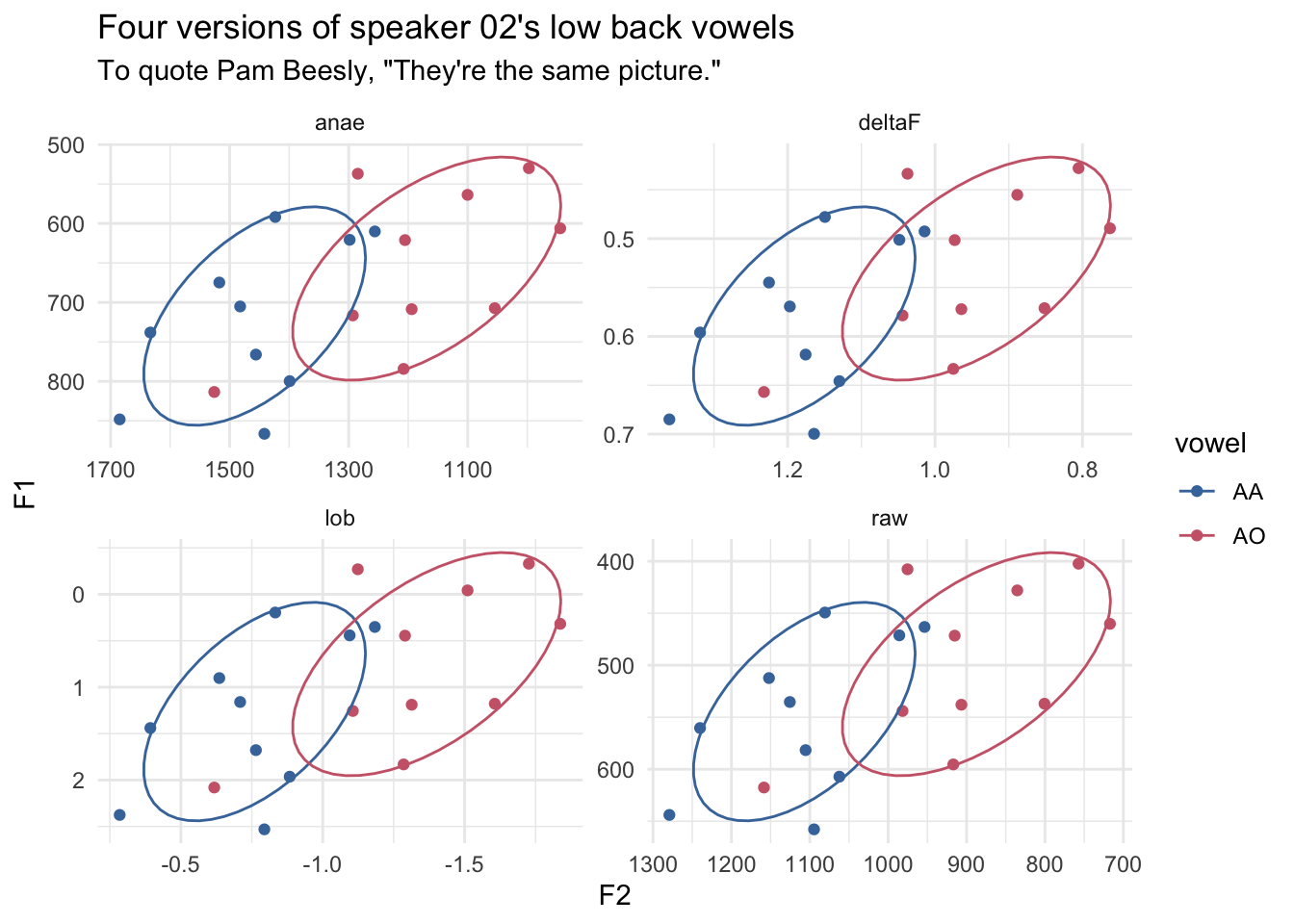
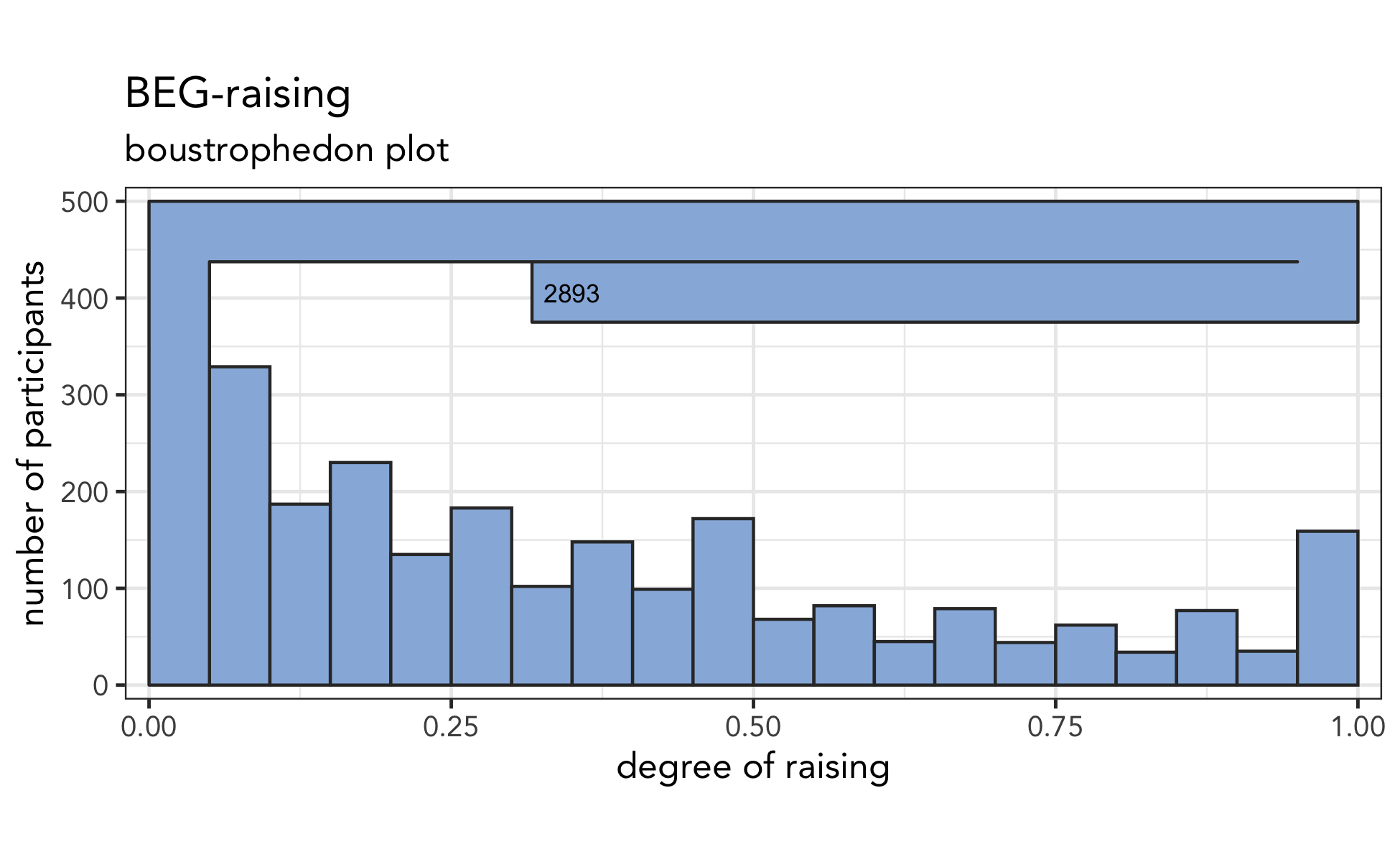
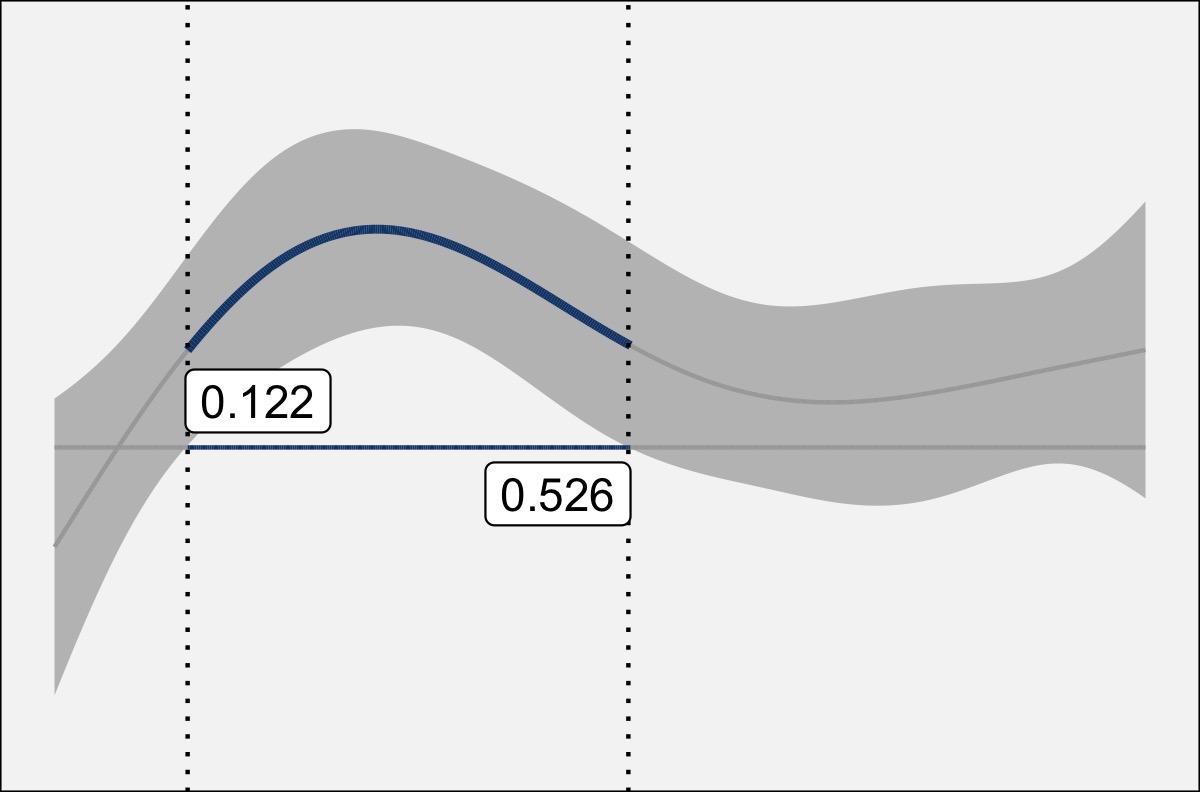
Pillai scores don’t change after normalization
How-to Guides
Methods
Phonetics
R
Skills
Vowel Overlap


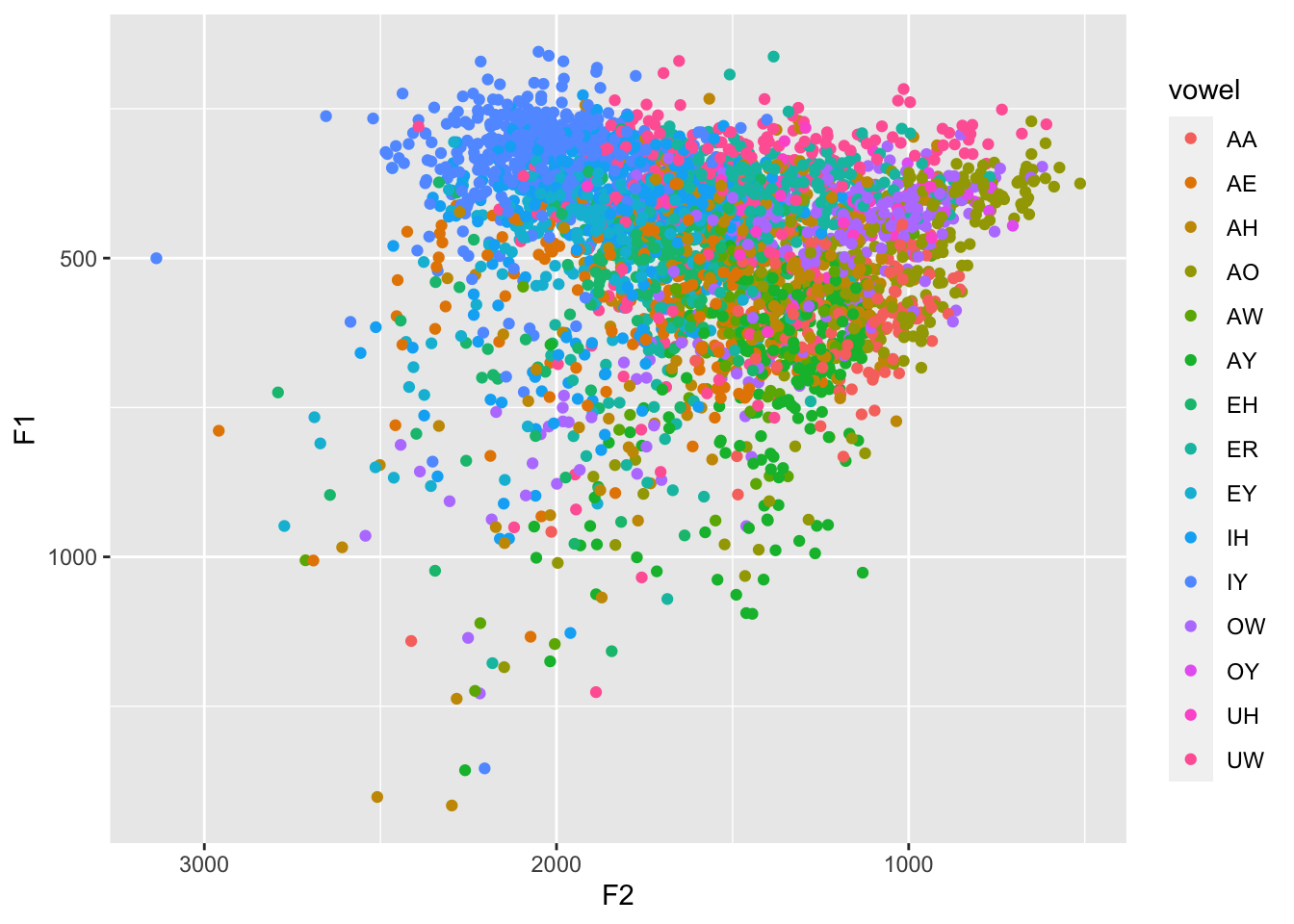
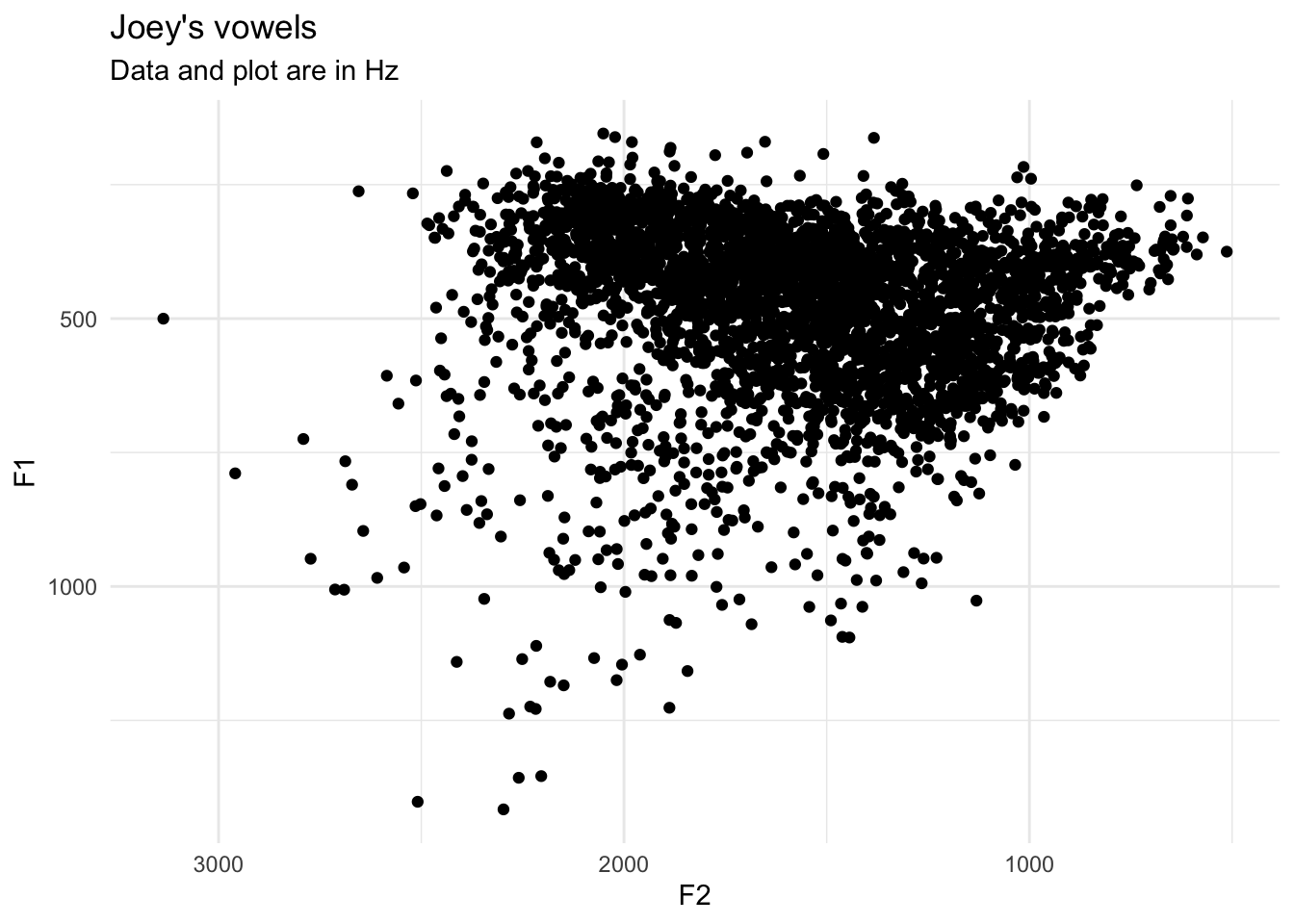
joeysvowels: An R package of vowel data
Github
Methods
Phonetics
R
R Packages
Side Projects
Teaching
West
barktools: Functions to help when working with Barks
Data Viz
Github
How-to Guides
Methods
Phonetics
R
R Packages
Side Projects
Skills

UGA Linguistics Colloquium 2020
Animations
Dissertation
Pacific Northwest
Presentations
Research
LSA and ADS 2020
Animations
Conferences
Linguistic Atlas
Research
South

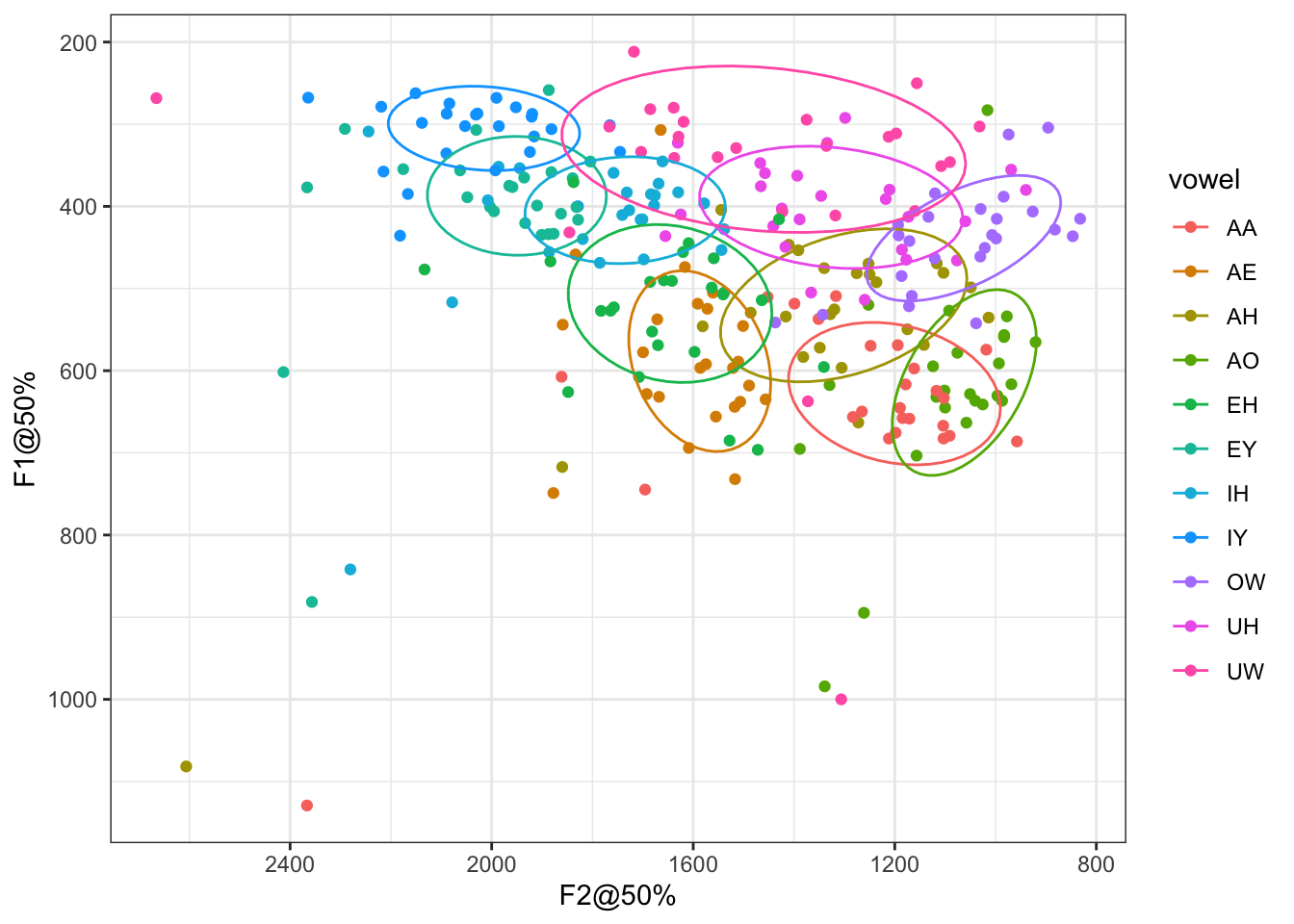
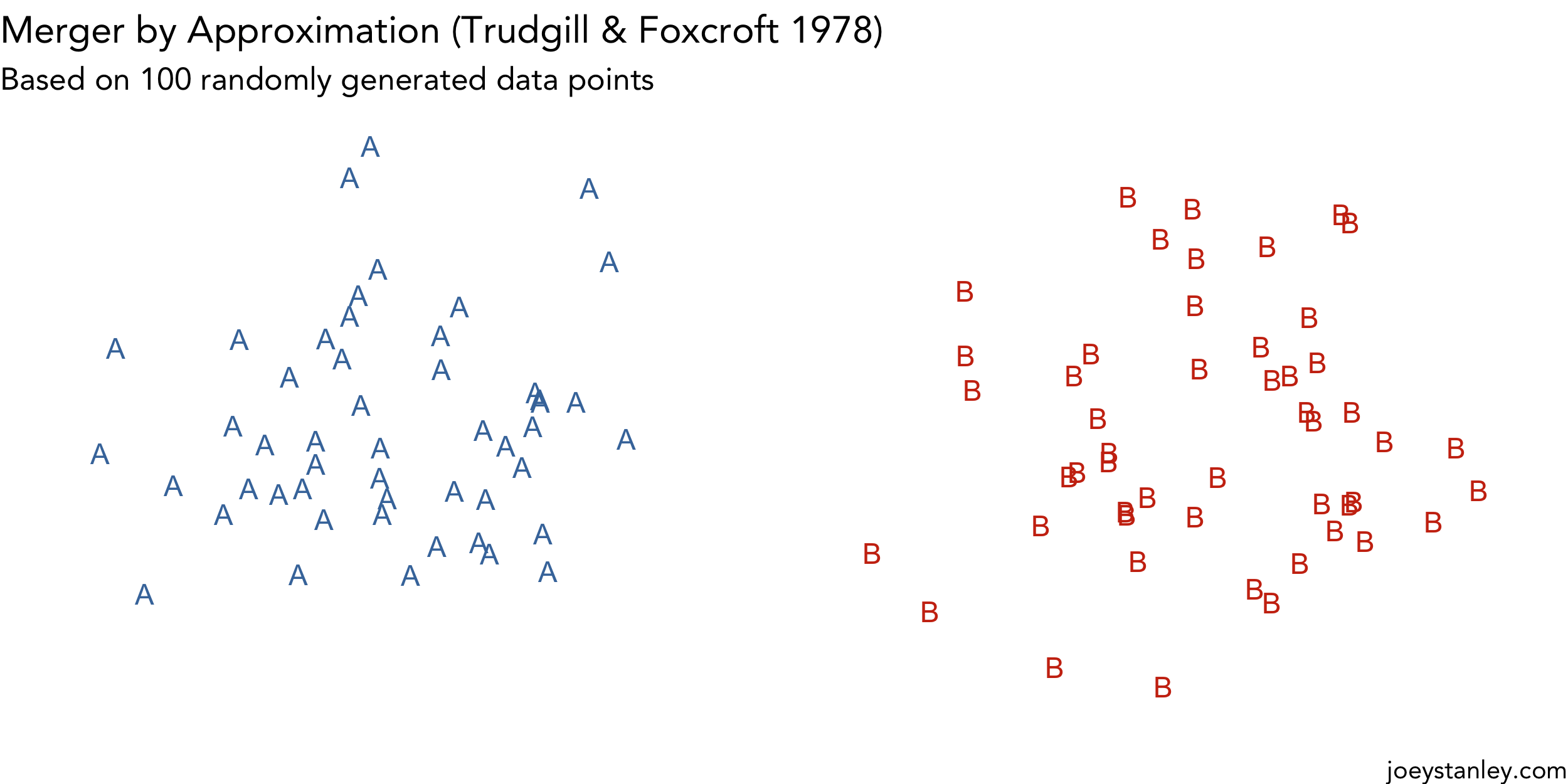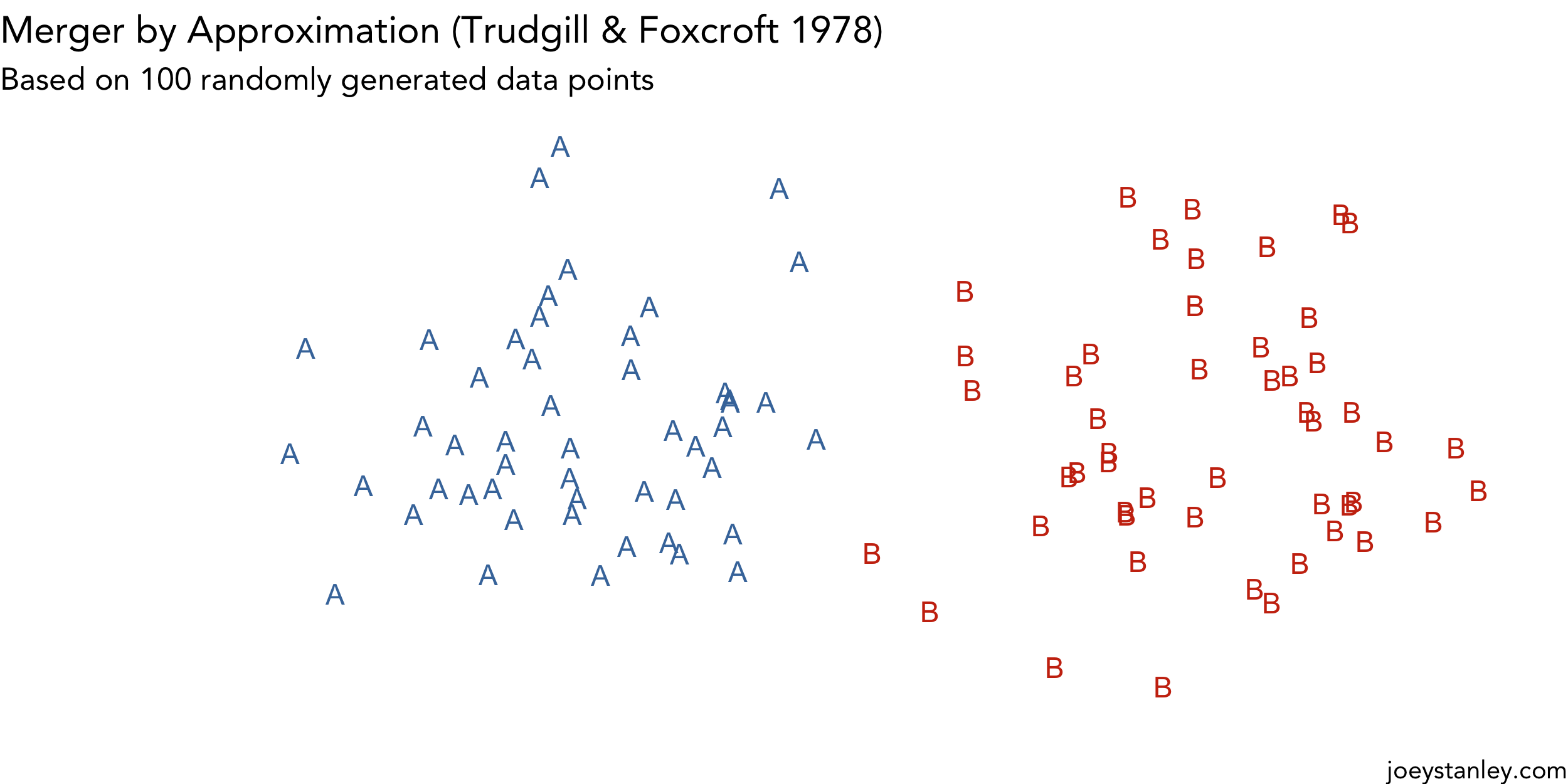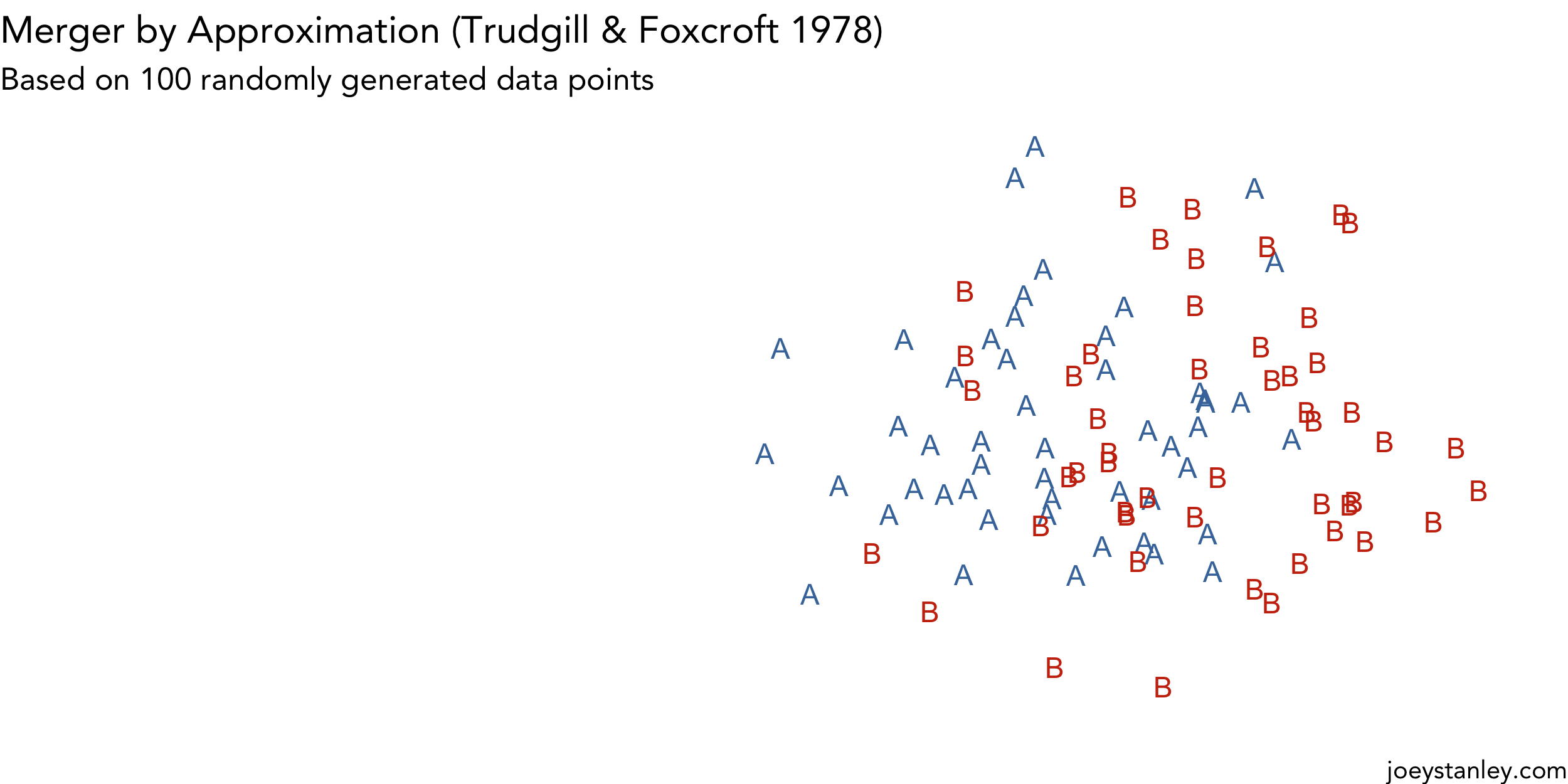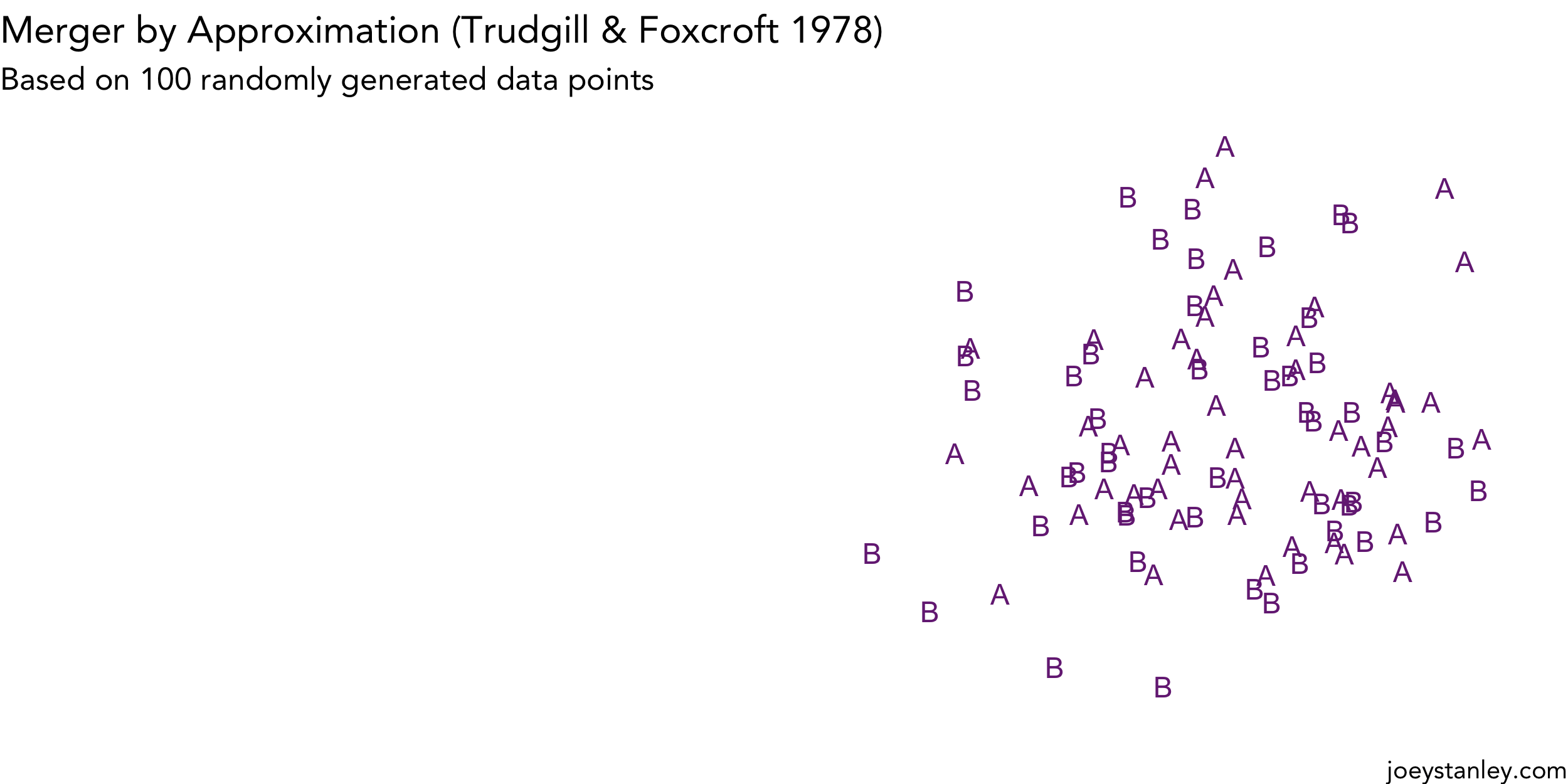
Animating Mergers
Animations
Data Viz
Github
R
Side Projects
Simulations
Teaching
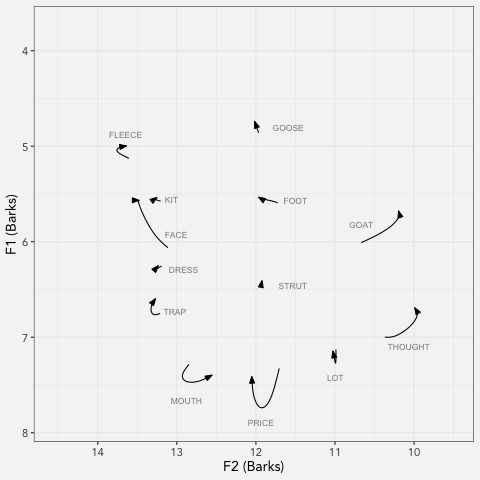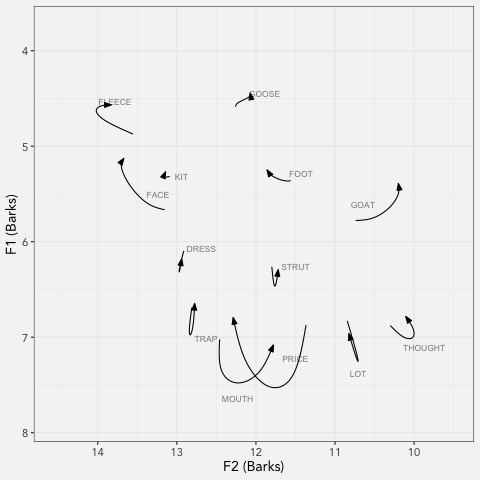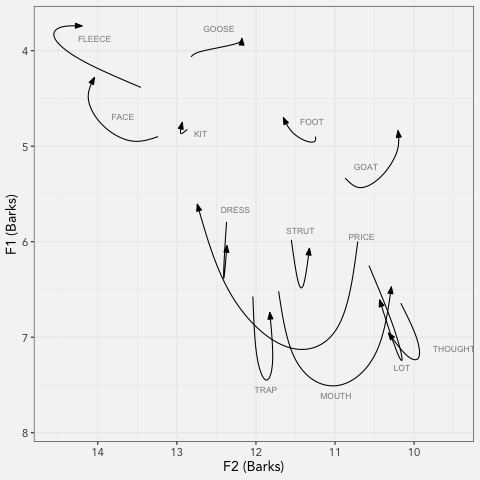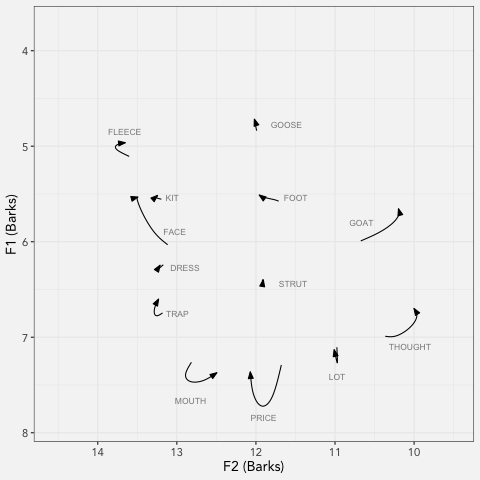
LCUGA6
Animations
Conferences
Linguistic Atlas
Presentations
Research
South
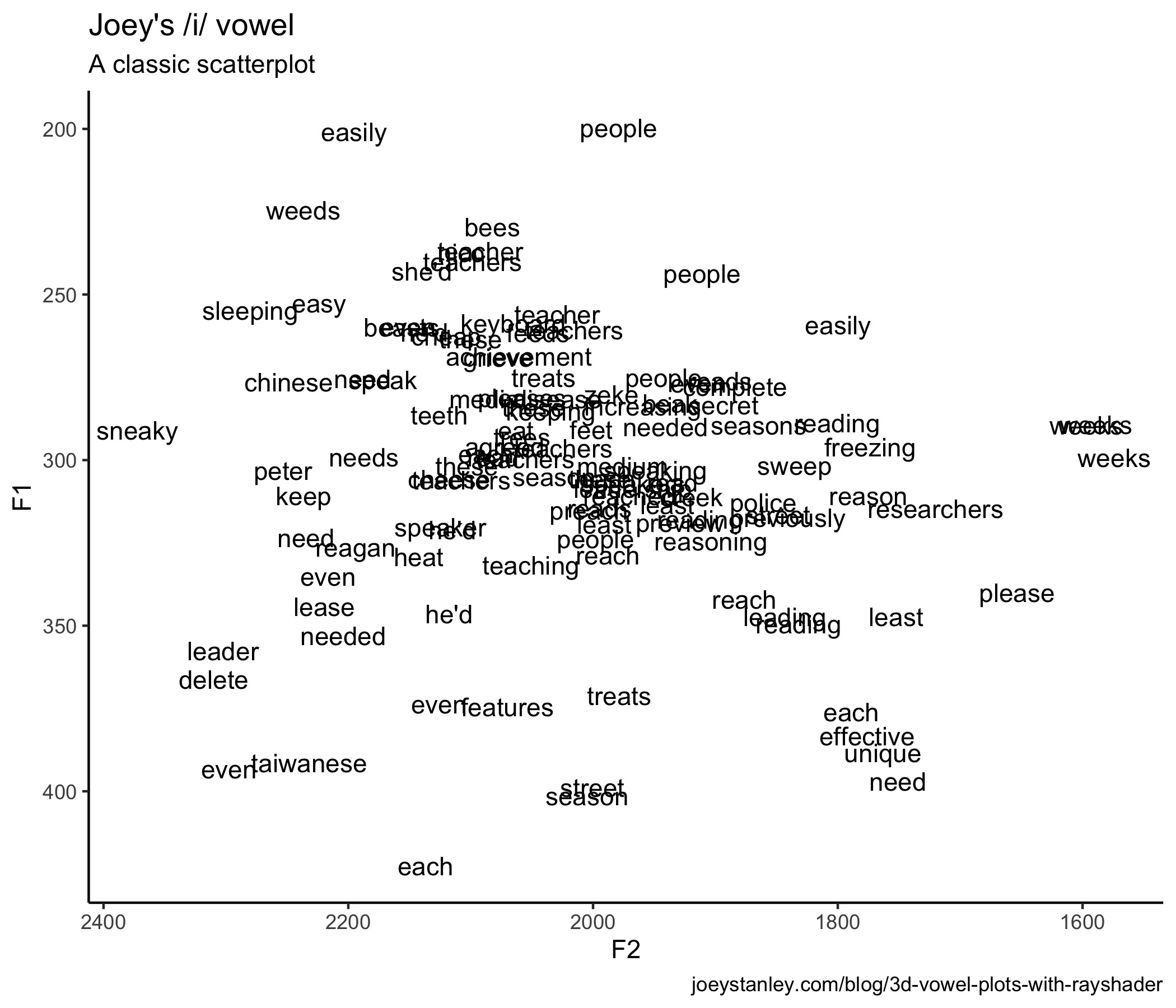
3D Vowel Plots with Rayshader
Animations
Data Viz
Github
How-to Guides
Phonetics
R
Side Projects
Skills
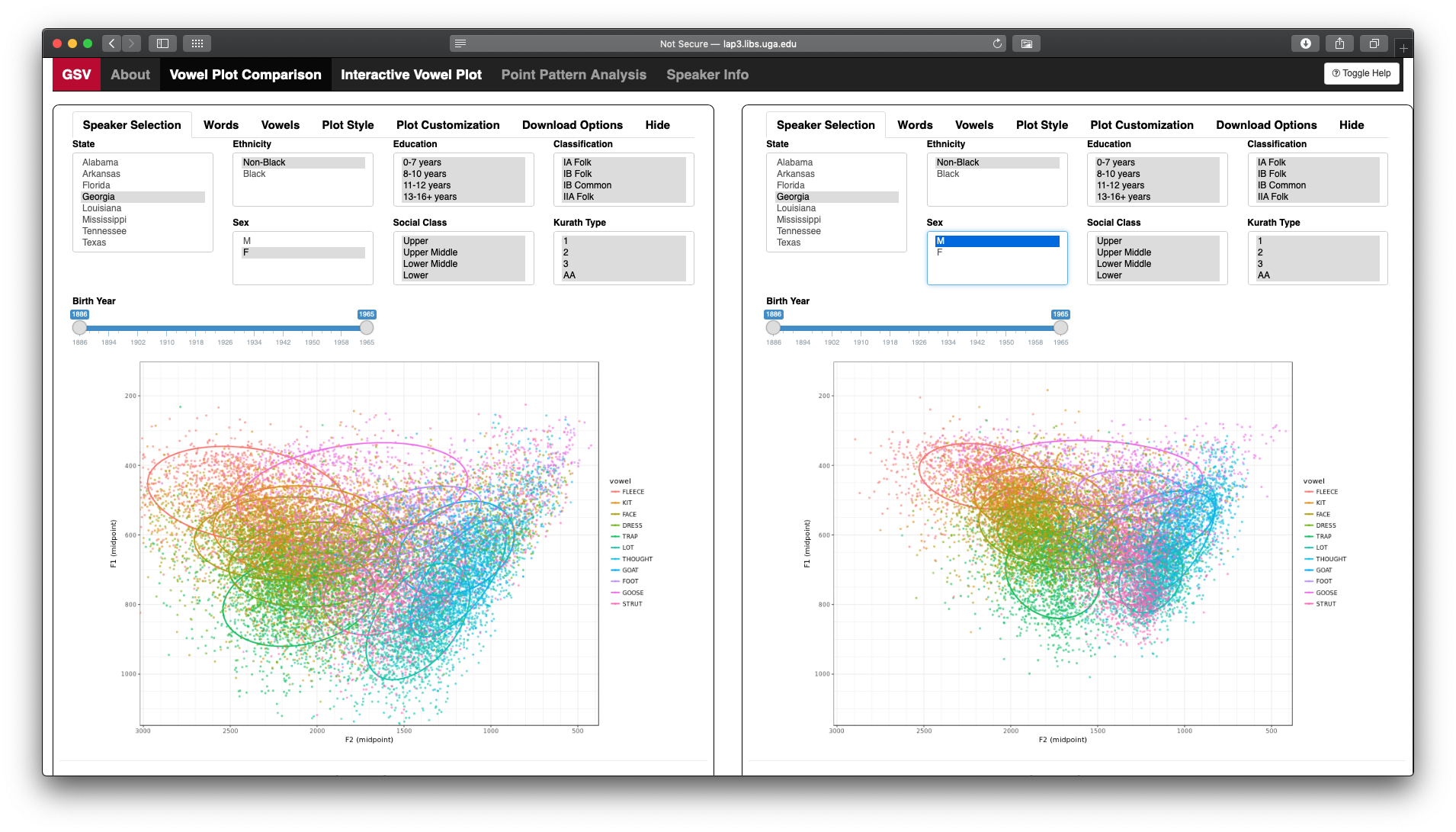
DH 2019
Conferences
Linguistic Atlas
Presentations
Research
South
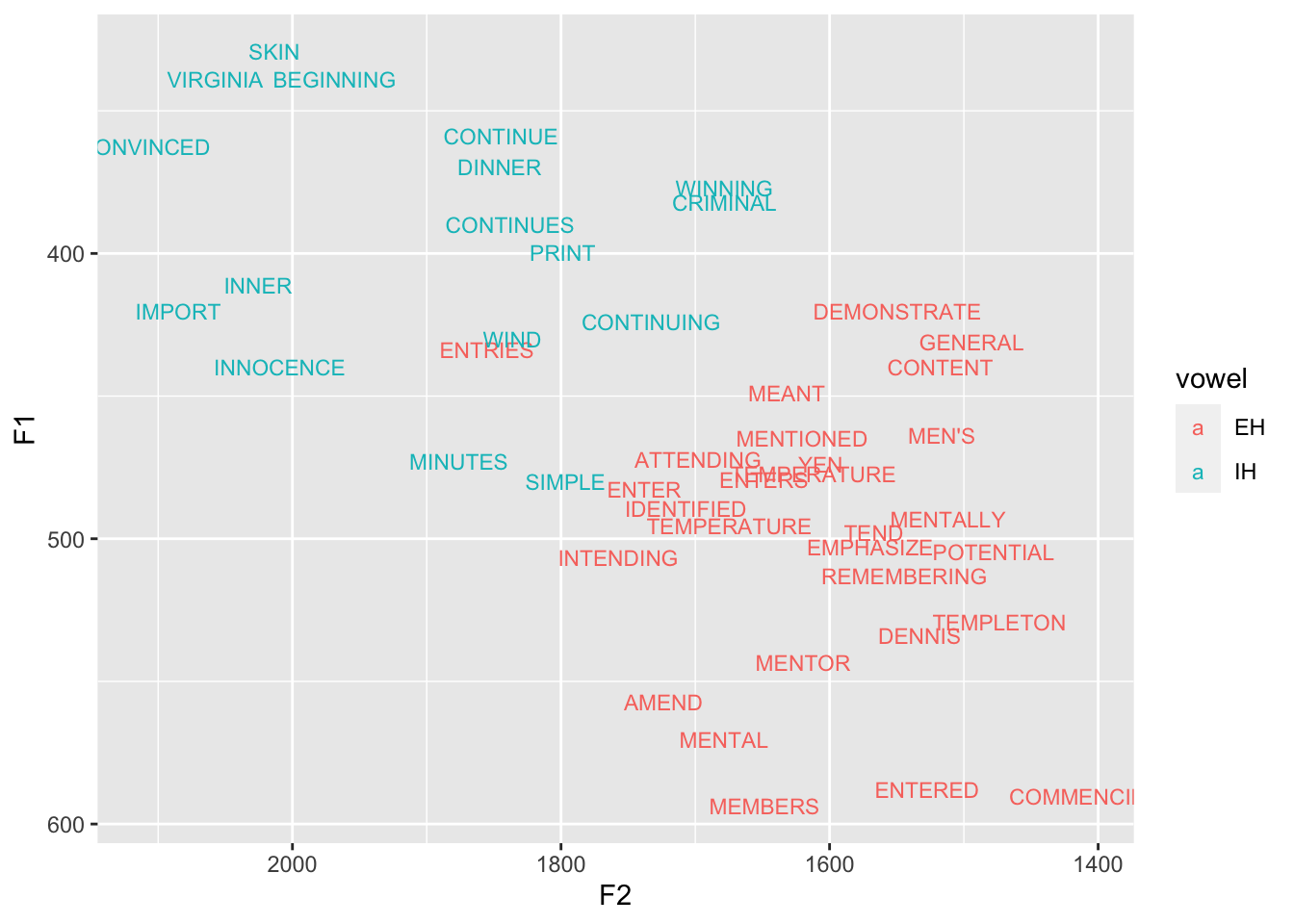
Vowel overlap in R: More advanced topics
How-to Guides
Methods
Phonetics
R
Skills
Data Viz
Vowel Overlap
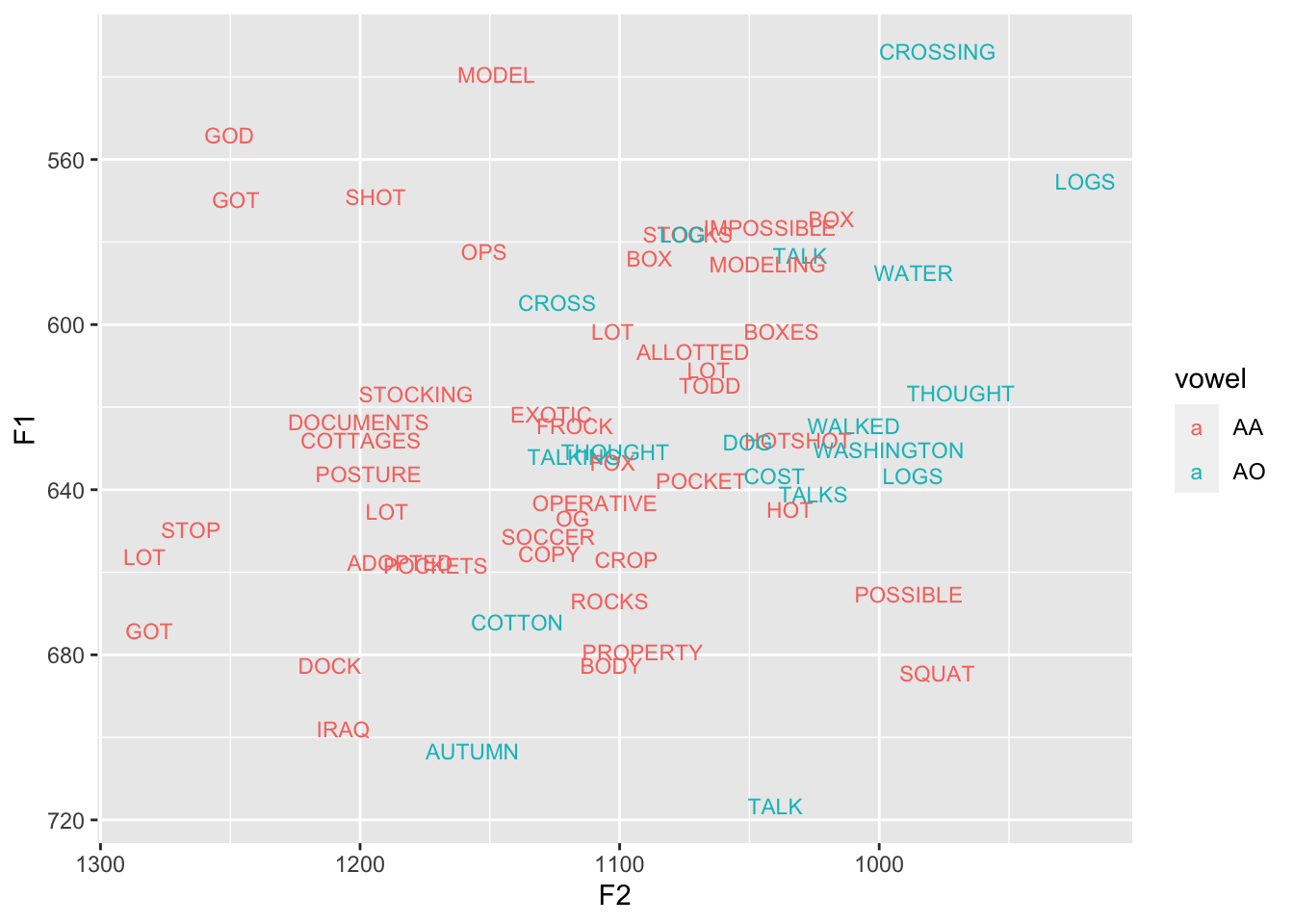
A tutorial in measuring vowel overlap in R
Data Viz
How-to Guides
Methods
Phonetics
R
Skills
Vowel Overlap
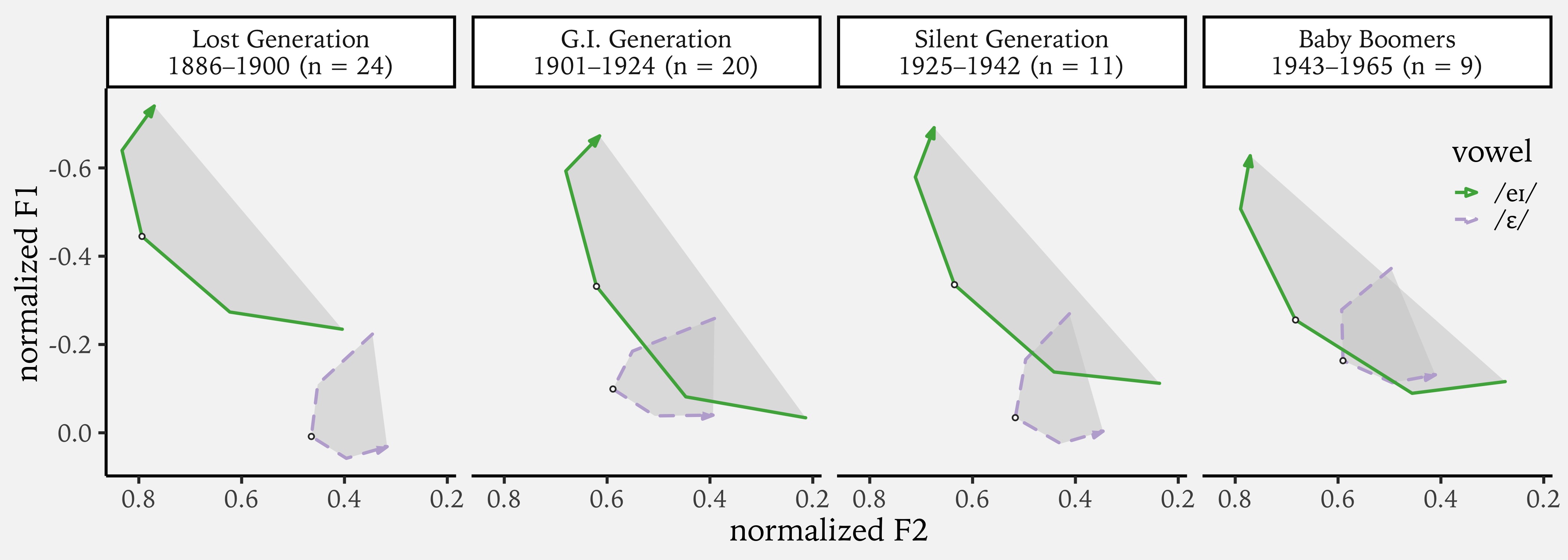
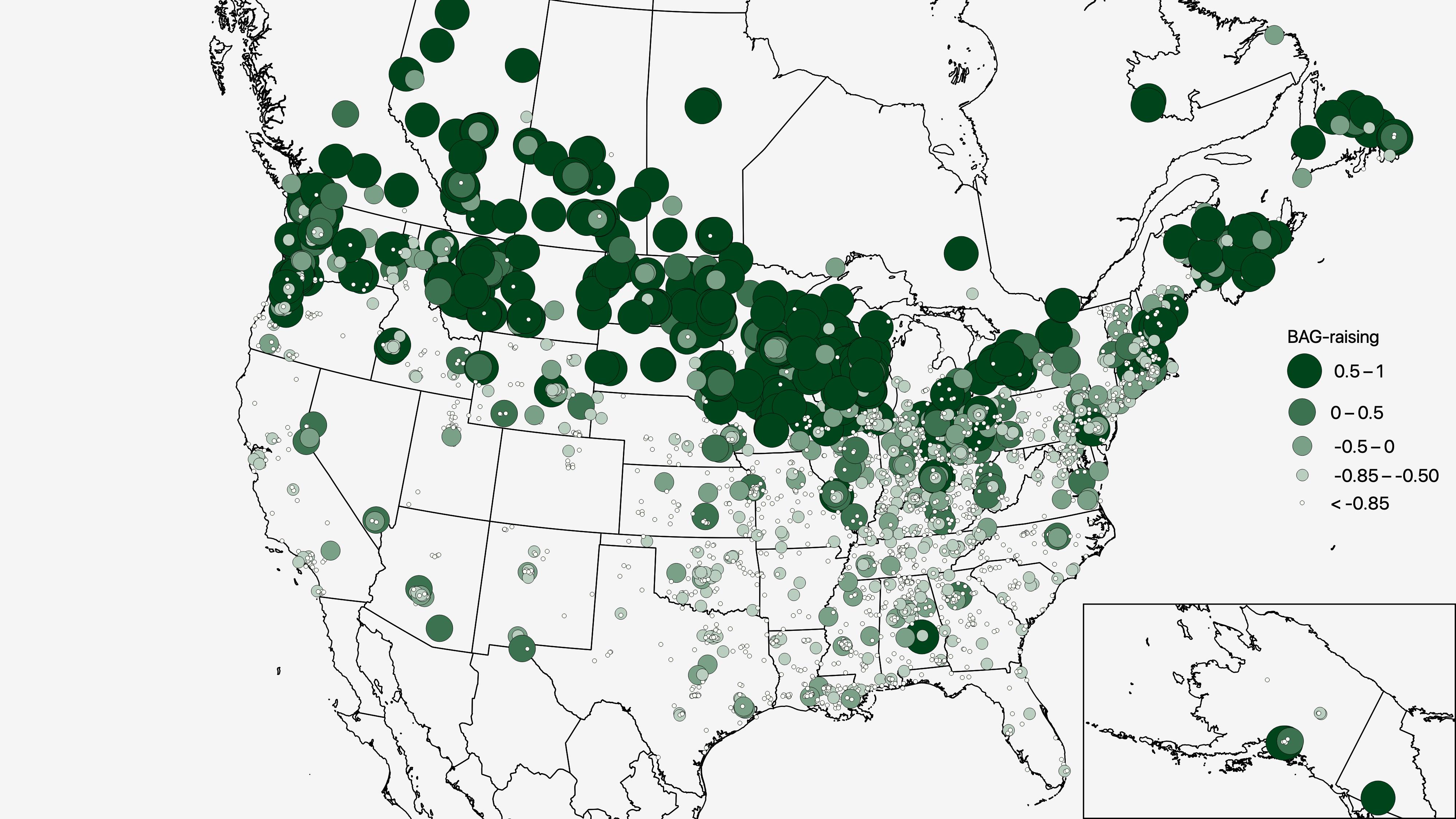

NWAV47
Conferences
Pacific Northwest
Presentations
Research
LCUGA5
Conferences
Pacific Northwest
Phonetics
Presentations
Research
South
Utah
Brand Yourself 2
CSS
Github
How-to Guides
Meta
Presentations
Twitter
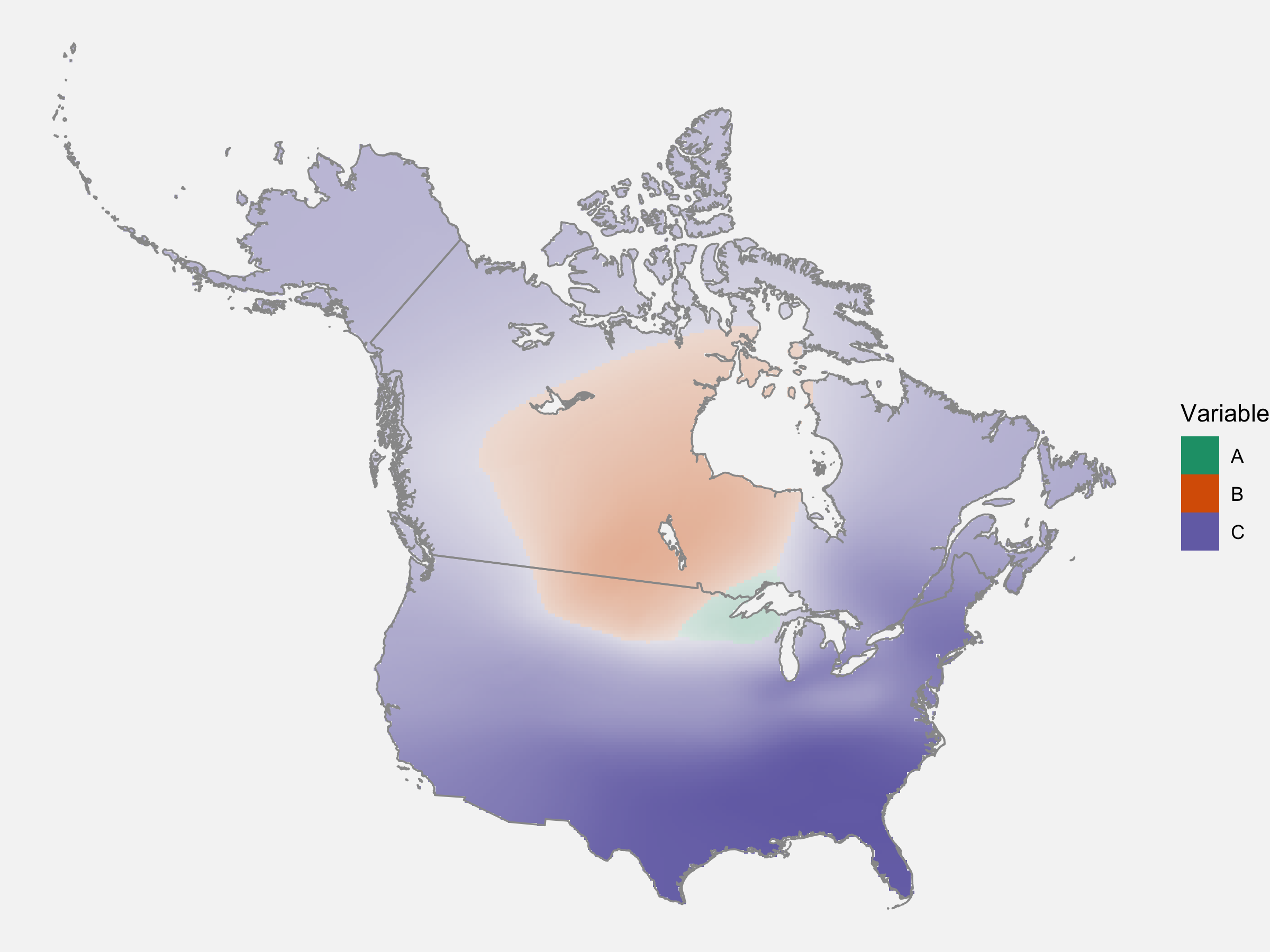
Jealousy List 1
Jealousy Lists
R
Skills
Statistics
GIS
Data Viz
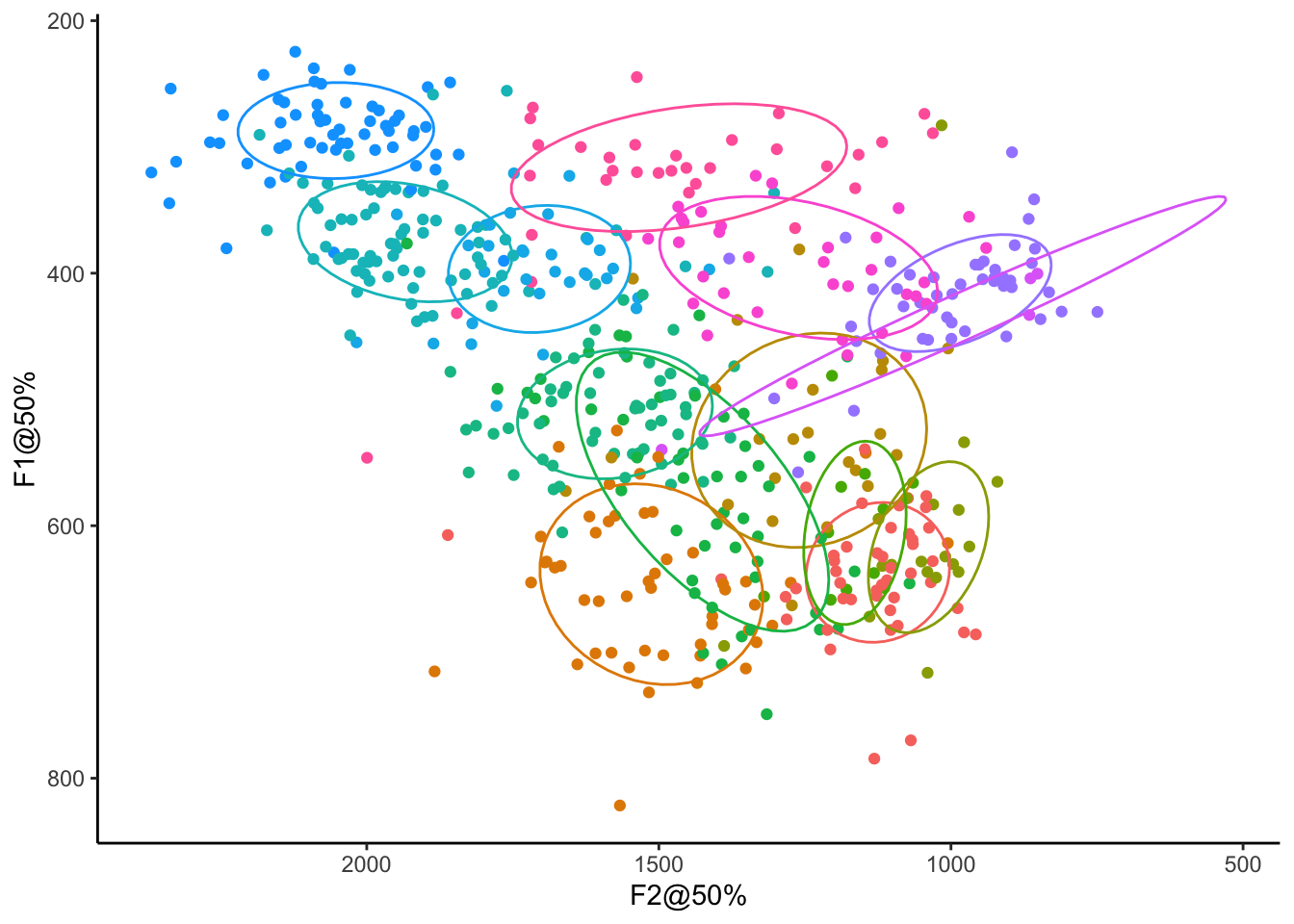
Making vowel plots in R (Part 2)
How-to Guides
Methods
Phonetics
R
Skills
Data Viz

Making vowel plots in R (Part 1)
How-to Guides
Methods
Phonetics
R
Skills
Data Viz
ADS2018
Conferences
Dissertation
Linguistic Atlas
Phonetics
Presentations
Research
Utah
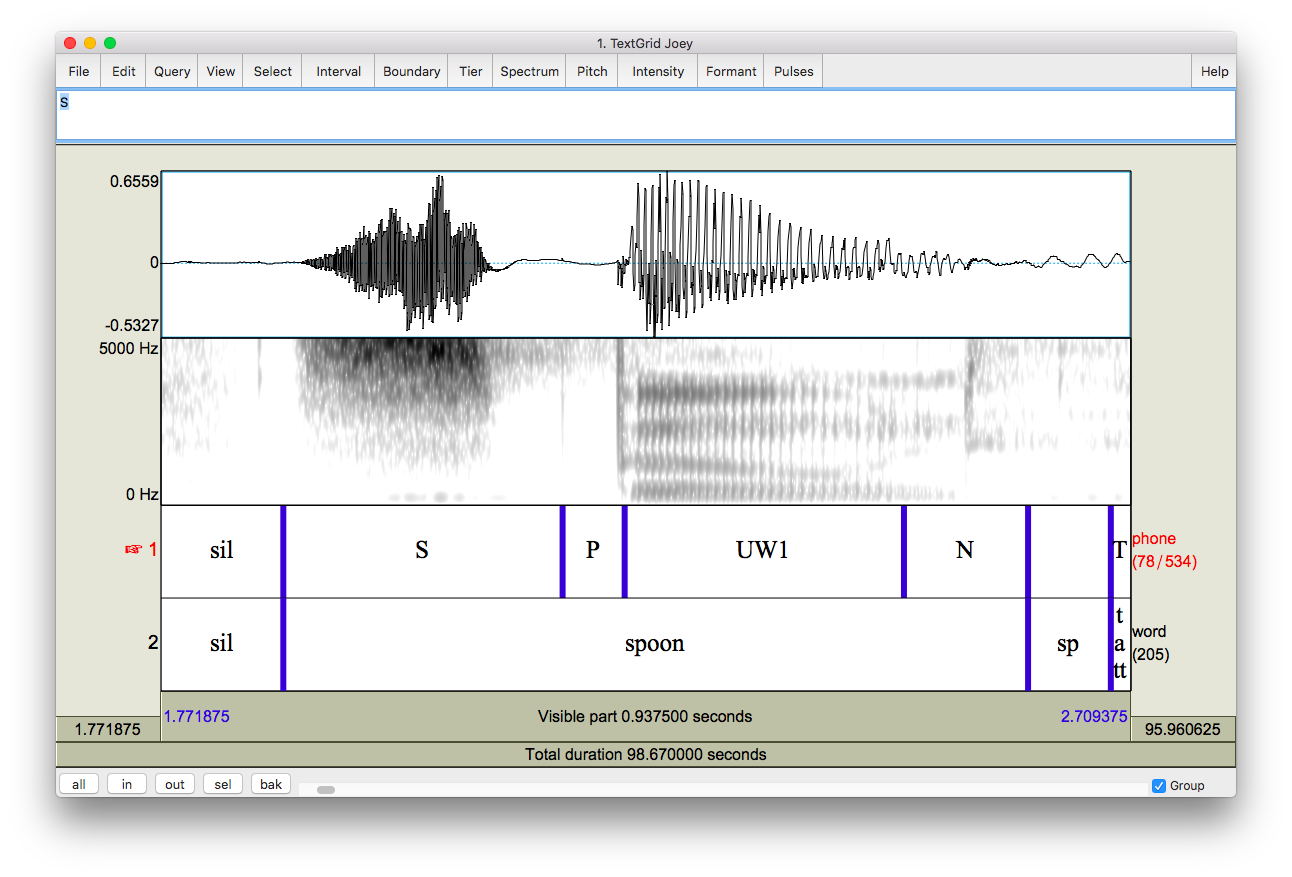

NWAV46
Conferences
Dissertation
Pacific Northwest
Presentations
Research
LCUGA4
Conferences
Pacific Northwest
Presentations
Research
Utah
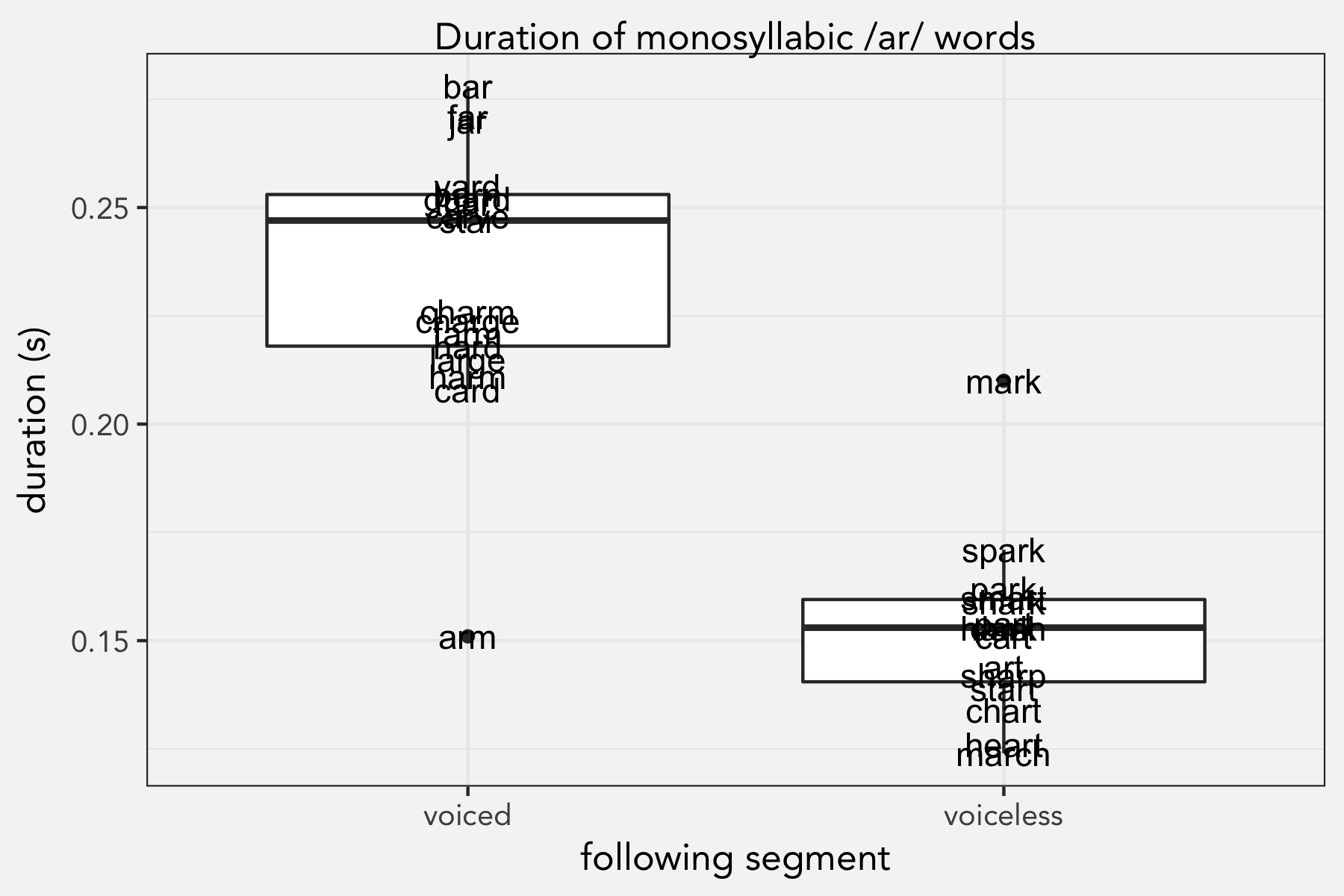
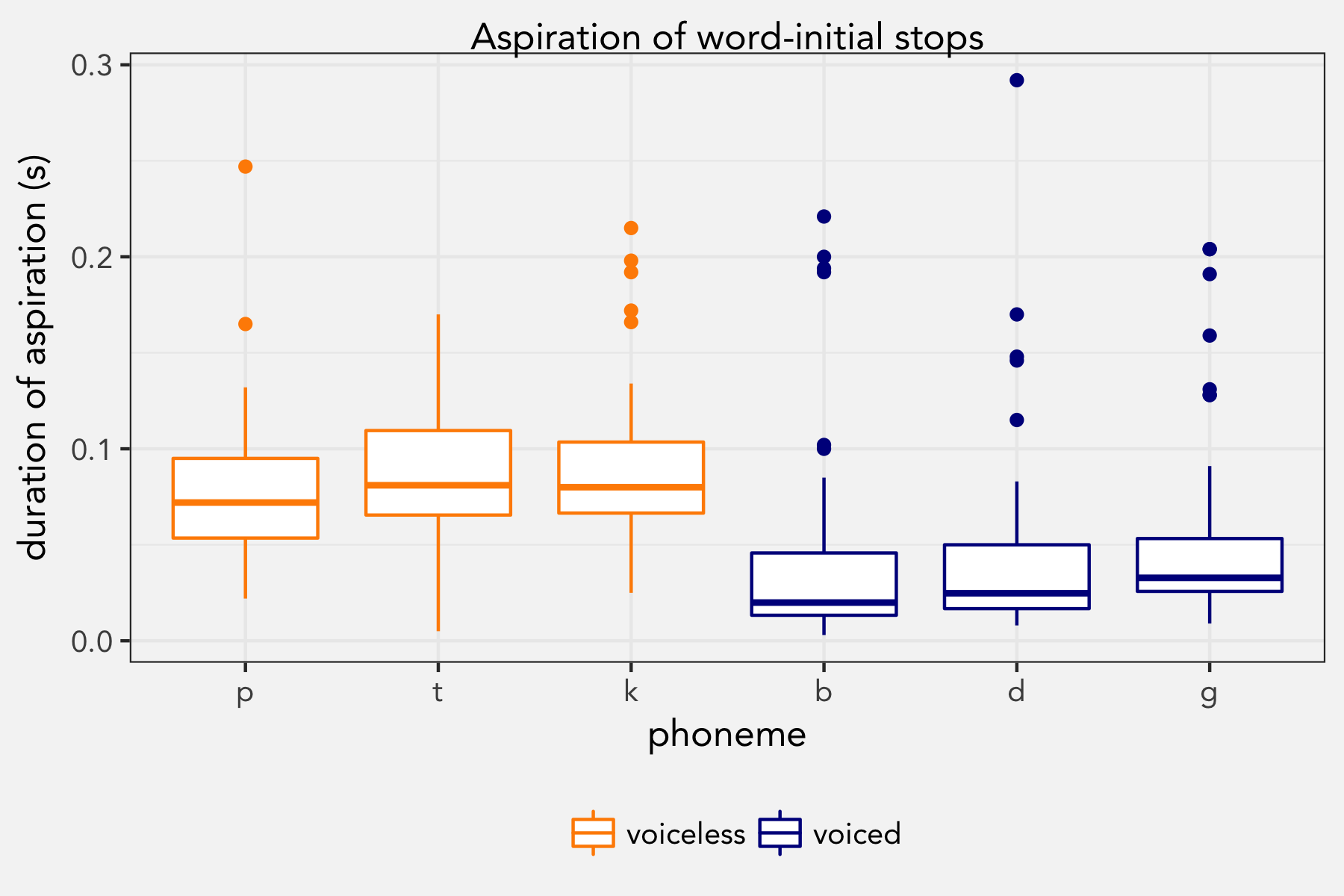
General Update
West
Utah
MTurk
Research
Conferences
Linguistic Atlas
Pacific Northwest
Dissertation

SECOL 2017
Conferences
Linguistic Atlas
Presentations
Research
Skills

Brand Yourself
CSS
Github
How-to Guides
Meta
Presentations
Twitter
ADS Meeting!
Conferences
Pacific Northwest
Research
No matching items